Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти, часть 7. Инструменты для повышения производительности памяти
Оригинал: Memory part 7: Memory performance toolsАвтор: Ulrich Drepper
Дата публикации: ноябрь 2007 г.
Перевод: М.Ульянов
Дата перевода: 5 мая 2010 г.
Инструменты для повышения производительности памяти
7.5 Оптимизация страничных ошибок
В операционных системах с замещением страниц по требованию (Linux - одна из таких систем) всё, что делает вызов mmap, - изменяет таблицы страниц. А именно - он гарантирует, что в случае обращения к страницам, связанным с файлами, соответствующие данные (файлы) будут доступны, а в случае обращения к анонимной памяти будут предоставлены страницы, инициализированные нулями. То есть, при вызове mmap в таких системах не происходит собственно выделения памяти. {Не согласны и хочется возразить? Погодите маленько, далее мы поговорим об исключениях.}
Память выделяется при первом обращении к странице, будь то запрос чтения или записи, либо при выполнении кода. В ответ на возникающую в таком случае страничную ошибку ядро берет на себя управление и определяет (с помощью дерева таблиц страниц), какие данные должна содержать страница. Такая обработка страничных ошибок недешево обходится, но тем не менее именно это происходит с каждой страницей, используемой процессом.
Для минимизации стоимости страничных ошибок (стоимость здесь и далее - в смысле "потери производительности") необходимо снижать общее число используемых страниц памяти. Этой цели может послужить соответствующая оптимизация исходного кода. Для уменьшения стоимости определенной области кода (например, кода инициализации), можно реорганизовать его в таком порядке, чтобы в данной области количество затрагиваемых страниц памяти было минимально. Но не так уж просто определить "правильный" порядок.
Автор данной работы написал утилиту на основе инструментария valgrind, позволяющую контролировать появление страничных ошибок. Но контролировать не количество, а причину их возникновения. Инструмент pagein выдает информацию о порядке и времени возникновения страничных ошибок. Выходные данные, записываемые в файл pagein.<PID>, выглядят как показано на рисунке 7.8.
0 0x3000000000 C 0 0x3000000B50: (within /lib64/ld-2.5.so) 1 0x 7FF000000 D 3320 0x3000000B53: (within /lib64/ld-2.5.so) 2 0x3000001000 C 58270 0x3000001080: _dl_start (in /lib64/ld-2.5.so) 3 0x3000219000 D 128020 0x30000010AE: _dl_start (in /lib64/ld-2.5.so) 4 0x300021A000 D 132170 0x30000010B5: _dl_start (in /lib64/ld-2.5.so) 5 0x3000008000 C 10489930 0x3000008B20: _dl_setup_hash (in /lib64/ld-2.5.so) 6 0x3000012000 C 13880830 0x3000012CC0: _dl_sysdep_start (in /lib64/ld-2.5.so) 7 0x3000013000 C 18091130 0x3000013440: brk (in /lib64/ld-2.5.so) 8 0x3000014000 C 19123850 0x3000014020: strlen (in /lib64/ld-2.5.so) 9 0x3000002000 C 23772480 0x3000002450: dl_main (in /lib64/ld-2.5.so)Рисунок 7.8: Выходные данные утилиты pagein
Второй столбец содержит адрес запрошенной страницы. Содержит она код или данные, указывается в третьем столбце, соответственно `C' (Code) - код, `D' (Data) - данные. Четвертый столбец содержит количество тактов, прошедших с момента первой страничной ошибки. Оставшаяся часть строки - попытка valgrind'а определить имя для адреса, вызвавшего данную страничную ошибку. Само значение адреса всегда верно, но с именем могут быть несоответствия, если нет доступа к информации отладки.
В примере, показанном на рисунке 7.8, выполнение начинается с адреса 0x3000000B50, который запрашивает страницу по адресу 0x3000000000. Вскоре запрашивается следующая за ней страница, на этот раз функцией под названием _dl_start. Код инициализации обращается к переменной на странице 0x7FF000000. Это происходит по прошествии всего 3,320 тактов после первой страничной ошибки и больше всего похоже на вторую инструкцию программы (от первой ее отделяют лишь три байта). Давайте взглянем на саму программу: видим нечто необычное относительно доступа к памяти. А именно, обращает на себя внимание инструкция call, которая вроде бы не загружает и не записывает никаких данных. Но она сохраняет адрес возврата в стек, что, собственно, мы и наблюдали в выходном отчете. Конечно, имеется в виду не официальный стек процесса, а внутренний стек приложения, используемый valgrind. Следовательно, при интерпретации результатов pagein важно помнить, что valgrind может внести некоторые искажения.
Выходные данные pagein можно использовать для определения, какие последовательности инструкций программы в идеале должны быть расположены рядом друг с другом. С первого же взгляда на код /lib64/ld-2.5.so видно, что первые команды сразу вызывают функцию _dl_start, и что два этих места расположены на разных страницах. Таким образом, реорганизация исходника путем перемещения кодовых последовательностей на одну и ту же страницу памяти может помочь избежать страничной ошибки - или хотя бы отсрочить её. Но пока что определение максимально эффективной организации кода - процесс обременительный. Поскольку повторные запросы страниц утилитой не записываются, то чтобы увидеть результаты изменений, приходится использовать метоб проб и ошибок. Путем анализа диаграммы вызовов можно предсказать возможные последовательности запросов, что поможет ускорить процесс сортировки функций и переменных.
На очень грубом, поверхностном уровне, последовательности запросов можно увидеть, изучая объектные файлы, из которых в итоге создается исполняемый модуль или DSO (Dynamic Shared Object = динамически разделяемый объект). Начиная с одной или нескольких отправных точек (например, имен функций), можно вычислять цепочки зависимостей. На уровне объектных файлов это неплохо работает даже без приложения особых усилий. На каждом проходе определяем, какие из объектных файлов содержат нужные нам функции и переменные. Начальный набор файлов необходимо определить однозначно. Затем выделяем все неопределенные ссылки в этих объектных файлах и добавляем их [ссылки] к набору нужных идентификаторов. И так повторяем, пока набор не станет стабилен.
Второй шаг - определение порядка. Объектные файлы необходимо скомпоновать друг с другом таким образом, чтобы "задеть" как можно меньше страниц памяти. Вдобавок, ни одна функция не должна пересекать границу страницы. Сложность в том, что для лучшего расположения объектных файлов необходимо знать, что дальше будет делать компоновщик. Тут важно, что компоновщик помещает объектные файлы в исполняемый модуль (или DSO) в том же порядке, в каком они расположены во входных файлах (например, архивах) и в командной строке. Это дает программисту значительные возможности.
Для тех, кто готов потратить немного больше времени: были успешные попытки реорганизации, сделанные с помощью автоматического отслеживания запросов через перехватчики (hooks) __cyg_profile_func_enter и __cyg_profile_func_exit, которые вставляет gcc при запуске с параметром -finstrument-functions [oooreorder]. Подробную информацию об интерфейсах __cyg_* можно найти в руководстве к gcc. Используя трассировку программы, программист может более точно определить цепочки запросов. Результаты, достигнутые в [oooreorder] - снижение стоимости инициализации на 5%, и это достигнуто всего лишь перестановкой функций. Основная польза - снижение числа страничных ошибок, но и кэш TLB тоже играет роль, и немалую, учитывая, что в виртуальных средах промахи TLB обходятся гораздо дороже.
Комбинируя анализ вывода утилиты pagein с информацией о последовательности запросов, можно оптимизировать определенные этапы работы программы (инициализация тому примером), минимизируя число страничных ошибок.
Ядро Linux предоставляет два дополнительных механизма для избежания страничных ошибок. Первый - флаг для mmap, заставляющий ядро не просто модифицировать таблицу страниц, но, по сути, заранее загрузить все страницы в отображаемой области. Это достигается просто - к четвертому параметру вызова mmap добавляется флаг MAP_POPULATE. В результате вызов mmap обойдется значительно дороже, но, если все страницы, выделенные по данному запросу, будут использованы в ближайшее время, преимущества могут оказаться огромными. Вместо обработки множества страничных ошибок, каждая из которых обходится довольно дорого в связи с требованиями синхронизации и пр., программе придется обработать всего один, хоть и дорогой, вызов mmap. Обратная сторона медали, т.е. этого флага, проявляется в случаях, когда большая часть выделенных страниц не используется в ближайшее время после вызова (или не используется вообще). Выделенные, но не используемые страницы - просто пустая трата времени и памяти. Страницы, выделенные, но не использованные сразу (в ближайшее время) после вызова, тоже засоряют систему. Память выделяется еще до того, когда это действительно нужно, что теоретически может привести к нехватке свободного места. С другой стороны, в худшем случае страница просто будет использована для других целей (ведь она еще не была изменена), что не так уж дорого обходится системе - хотя, с учетом выделения, чего-то тоже стоит.
В целом, механизму MAP_POPULATE недостает избирательности. А вторая проблема: это лишь оптимизация; даже если выделены все-все страницы - не беда. Если система слишком занята для выполнения операции, предварительное выделение может быть отменено. А когда страница будет реально нужна, опять же произойдет страничная ошибка; ничего страшного - по крайней мере, не страшнее искусственного создания нехватки ресурсов. Альтернатива - применение POSIX_MADV_WILLNEED с функцией posix_madvise. Это подсказка операционной системе, что в ближайшем будущем программе понадобится страница, описанная в запросе. Ядро может как проигнорировать эту подсказку, так и заранее выделить страницы. Преимущество этого механизма в том, что он более избирателен. Предварительно загружены могут быть как отдельные страницы, так и диапазоны страниц в любом отображенном адресном пространстве. В случае отображенного в память файла, содержащего множество не используемых при выполнении данных, этот метод имеет огромное преимущество перед MAP_POPULATE.
Помимо этих активных подходов к минимизации количества страничных ошибок, также можно применить более пассивный подход, популярный среди разработчиков оборудования. Динамически разделяемый объект (DSO) занимает смежные страницы в адресном пространстве, часть из них содержит код, другая часть - данные. Чем меньше размер страницы, тем больше страниц необходимо для одного объекта DSO. А это, в свою очередь, увеличивает число страничных ошибок. Но важно отметить, что верно и обратное. Чем больше размер страницы, тем меньше их нужно для отображения; а следовательно, уменьшается и число страничных ошибок.
Большинством архитектур поддерживаются страницы размером в 4 Кб. На IA-64 и PPC64 популярен размер страниц в 64 Кб. Это значит, что минимальный объем выделяемой памяти составляет 64 Кб. Данное значение необходимо указывать при компиляции ядра, и его нельзя изменить динамически, во время работы. По крайней мере, пока нельзя. Интерфейсы ABI архитектур, поддерживающих несколько размеров страниц, позволяют запускать приложения с любым из поддерживаемых размеров. Среда выполнения сама сделает необходимые настройки, а корректно написанная программа ничего не заметит. Увеличенные размеры страниц означают больше потерь в результате того, что страницы используются лишь частично, но в некоторых ситуациях это вполне допустимо.
Большинство архитектур также поддерживают очень большие размеры, от 1 Мб и больше. Такие страницы иногда бывают полезны, но выделять всю память такими огромными кусками - бессмысленно. Слишком велики будут потери физической памяти. Но огромные страницы имеют свои преимущества: если используются не менее огромные наборы данных, то хранение их в страницах по 2 Мб на х86-64 потребует на 511 страничных ошибок меньше (в расчете на каждую большую страницу), чем применение страничек по 4 Кб. Это может в корне всё изменить. Решение: избирательно выделять память таким образом, чтобы использовались большие страницы именно для указанного диапазона адресов, а для остальных отображений того же процесса оставить обычные размеры страниц.
Использование больших страниц имеет свою цену. Поскольку области физической памяти, используемые для больших страниц, должны быть непрерывны, то спустя какое-то время отображение таких страниц может стать невозможным вследствие фрагментации памяти. Не доводите до такого. Люди работают над проблемами дефрагментации памяти и способами избежания фрагментации, но это очень сложно. Для больших страниц размером, скажем, 2 Мб, необходимо найти 512 последовательных страничек, а это сложно сделать практически всегда, за исключением одного периода: загрузки системы. Вот поэтому-то сегодня для использования больших страниц применяется специальная файловая система, hugetlbfs. Эта псевдо-файловая система резервируется по требованию системного администратора с помощью записи количества страниц, которое необходимо зарезервировать, в
/proc/sys/vm/nr_hugepages
Данная операция не будет выполнена, если не будет найдено достаточно свободных, последовательно расположенных областей памяти. Становится еще интересней, если используется виртуализация. Виртуальная система, созданная с использованием модели VMM, не имеет прямого доступа к физической памяти и потому не может сама выделить hugetlbfs. Ей приходится полагаться на менеджер VMM, и не факт, что данная функциональность вообще поддерживается. Что касается модели KVM, ядро Linux, на котором запущен модуль KVM, может выполнить монтирование hugetlbfs и передать подмножество страниц для выделения на одном из гостевых доменов.
В дальнейшем, когда программе потребуется страница большого размера, будет несколько вариантов:
- программа может использовать разделяемую память System V, применив флаг
SHM_HUGETLB. - файловая система
hugetlbfsможет быть полностью смонтирована и затем программа может создавать файл уже внутри, и использоватьmmapдля отображения одной (или более) страниц в качестве анонимной памяти.
В первом случае hugetlbfs не требует монтирования. Код, запрашивающий одну или более страниц, будет выглядеть примерно так:
key_t k = ftok("/some/key/file", 42);
int id = shmget(k, LENGTH, SHM_HUGETLB|IPC_CREAT|SHM_R|SHM_W);
void *a = shmat(id, NULL, 0);
Критичные моменты данной кодовой последовательности - применение флага SHM_HUGETLB и выбор верного значения LENGTH, которое должно быть кратно размеру больших страниц системы. Для разных архитектур используются разные значения. Использование интерфейса разделяемой памяти System V неудобно, ибо завязано на ключевом аргументе для различия (разделения) отображений. Интерфейс ftok может легко привести к конфликтам, и поэтому лучше - если возможно - использовать другие механизмы.
Если требование обязательного монтирования системы hugetlbfs - не проблема, то лучше использовать именно этот вариант заместо разделяемой памяти System V. На деле может возникнуть пара затруднений с использованием специальной файловой системы - во-первых, ядро должно поддерживать ее, и во-вторых, пока нет стандартизированной точки монтирования. Когда файловая система смонтирована, к примеру, в /dev/hugetlb, программа легко может ее использовать:
int fd = open("/dev/hugetlb/file1", O_RDWR|O_CREAT, 0700);
void *a = mmap(NULL, LENGTH, PROT_READ|PROT_WRITE, fd, 0);
Используя одно и то же имя файла в запросе open, разные процессы могут совместно использовать одни и те же большие страницы и взаимодействовать. Также есть возможность сделать страницы исполняемыми, для чего нужно установить флаг PROT_EXEC в запросе mmap. Как и в примере с разделяемой памятью System V, значение LENGTH должно быть кратно размеру больших страниц.
Аккуратно написанные программы (а такими должны быть все программы) могут определять точку монтирования во время выполнения, используя функцию вроде этой:
char *hugetlbfs_mntpoint(void) {
char *result = NULL;
FILE *fp = setmntent(_PATH_MOUNTED, "r");
if (fp != NULL) {
struct mntent *m;
while ((m = getmntent(fp)) != NULL)
if (strcmp(m->mnt_fsname, "hugetlbfs") == 0) {
result = strdup(m->mnt_dir);
break;
}
endmntent(fp);
}
return result;
}
Больше информации об этих двух случаях можно найти в файле hugetlbpage.txt, являющемся частью дерева исходников ядра. Этот файл также описывает особый подход, требуемый в случае IA-64.
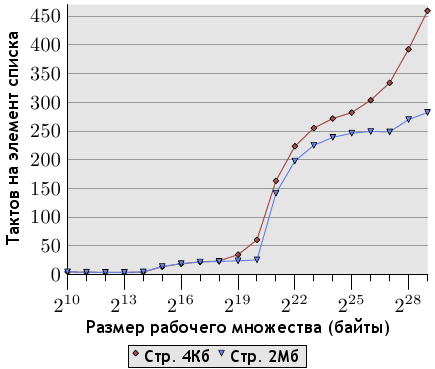
Рисунок 7.9: Выборка с применением больших страниц памяти, NPAD=0
Чтоб продемонстрировать преимущества больших страниц, на рисунке 7.9 показаны результаты выполнения теста случайной выборки при NPAD=0. Это те же данные, что показаны на рисунке 3.15, но в этот раз мы используем также страницы памяти большого размера. Как видно - преимущество в производительности может быть огромно. Для 220 байт использование больших страниц дало прирост производительност в 57%. Это связано с тем, что данный размер всё еще полностью умещается в одну страницу размером 2 Мб, и потому не происходит никаких промахов DTLB.
Далее прирост поначалу не столь высок, но с повышением размера рабочего множества снова увеличивается. Для рабочего множества в 512 Мб использование больших страниц дает прирост производительности в 38%. Кривая теста с использованием больших страниц выравнивается на отметке в 250 тактов. Когда рабочие множества достигают размеров более 227 байт, цифры снова значительно вырастают. Причина выравнивания в том, что буфер TLB в 64 элемента для страниц в 2 Мб покрывает 227 байт.
Как показывают цифры, большую часть потерь при использовании больших рабочих множеств составляют потери TLB. Использование интерфейсов, описанных в этом разделе, дает большой выигрыш. Скорее всего, данные этого графика соответствуют идеальному варианту, но даже реально работающие программы демонстрируют значительное увеличение в скорости. Среди программ, использующих сегодня страницы больших размеров, находятся базы данных, поскольку они работают с большими объемами данных.
На данный момент нет способов использования больших страниц для отображения данных, связанных с файлами. Есть заинтересованность в реализации данной возможности, но все сделанные пока что предложения подразумевают использование исключительно больших страниц с помощью файловой системы hugetlbfs. Это неприемлемо: использование больших страниц в данном случае должно быть прозрачным. Ядро может легко определять, какие отображения достаточно велики, и может автоматически использовать страницы большого размера. Проблема в том, что ядро не всегда в курсе важных нюансов. Если память, отображаемая большими страницами, в дальнейшем потребуется разделить на маленькие, по 4 Кб (например, в случае частичного изменения защиты с применением mprotect), то будет потеряно очень много драгоценных ресурсов, в частности, последовательных областей физической памяти. Так что можно быть уверенным: пройдет еще какое-то время, прежде чем такой подход будет успешно реализован.
| Назад | Оглавление | Вперед |
| Вся часть 7 в одном файле |