Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти, часть 7. Инструменты для повышения производительности памяти
Оригинал: Memory part 7: Memory performance toolsАвтор: Ulrich Drepper
Дата публикации: ноябрь 2007 г.
Перевод: М.Ульянов
Дата перевода: 5 мая 2010 г.
Инструменты для повышения производительности памяти
Существует множество инструментов, помогающих программисту понять, как программа использует кэш и память. Современные процессоры позволяют оценивать производительность на аппаратном уровне. Но некоторые вещи не измеришь напрямую, поэтому нельзя отказаться и от программного моделирования. На верхнем функциональном уровне также имеются специальные инструменты контроля за выполнением процесса. Далее представлен набор широко используемых средств, доступных на большинстве Linux-систем.
7.1 Профилирование памяти
Для профилирования памяти необходима аппаратная поддержка. Конечно, можно собрать какую-то информацию исключительно программными средствами, но то будут либо грубые подсчеты, либо только моделирование. Примеры подобного моделирования можно наблюдать в разделах 7.2 и 7.5. В текущем же разделе сосредоточимся на том, что можно измерить напрямую аппаратными средствами.
В Linux доступ к аппаратному мониторингу производительности обеспечивается через oprofile, который предоставляет возможности по непрерывному профилированию (см. [continuous]); осуществляет статистическое общесистемное профилирование с удобным интерфейсом. Oprofile - далеко не единственный способ использования функциональности процессоров для оценки производительности; разработчики Linux работают над pfmon, который в перспективе может достаточно широко распространиться, став достойным представителем своего класса.
Oprofile предоставляет низкоуровневый интерфейс, простой и минималистичный, c возможностью использования графической оболочки. Из списка всех событий, которые может отслеживать процессор, пользователь должен выбрать нужные ему. В руководствах по архитектуре процессоров эти события описаны, но частенько для верного истолкования необходимо обладать обширными знаниями о самих процессорах. Дальше - больше: возникает проблема с интерпретацией собранных данных. Счетчики измерения производительности содержат абсолютные значения и могут возрастать произвольно. Отсюда вопрос: а насколько большим должно быть значение данного счетчика, чтобы оно действительно считалось большим?
Частичное решение проблемы: не обращать внимания на абсолютные значения, а вместо этого сравнивать значения счетчиков друг с другом. Процессоры могут отслеживать более чем одно событие; получив абсолютные значения, можно вычислить их отношения. Таким образом получаем сравнимые коэффициенты, с которыми можно работать. Часто в качестве делителя берется единица измерения длительности обработки, т.е. количество тактов либо количество команд. Для начала полезно сравнить хотя бы эти два параметра между собой.
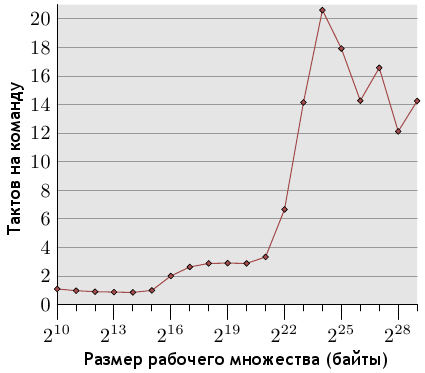
Рисунок 7.1: Количество тактов на команду (случайная выборка)
На рисунке 7.1 показано количество тактов на команду (Cycles Per Instruction, CPI) для простого теста в виде
выборки из памяти, выполняемой случайным образом для рабочих множеств разных размеров. В большинстве процессоров Intel события, получающие эту информацию, называются CPU_CLK_UNHALTED и INST_RETIRED. Имена говорят сами за себя: первое событие считает количество тактов, второе - количество команд. Наблюдается картина, схожая с проделанными ранее измерениями количества тактов на элемент списка. Для небольших рабочих множеств отношение равно 1 или даже меньше. Измерения проводились на мультискалярном процессоре Intel Core 2, который может работать одновременно с несколькими командами. Если программа не ограничена пропускной способностью памяти, отношение может быть значительно ниже единицы, но в нашем случае и единица - очень хороший результат.
Когда рабочее множество перестает помещаться в кэш L1d, коэффициент CPI возрастает до 3.0. Обратите внимание, что данный коэффициент усредняет расходы на доступ к кэшу L2 всех команд, а не только инструкций памяти. Используя данные отношения "тактов на элемент", можно вычислить, сколько команд тратится на доступ к элементу списка. Ну а когда и кэша L2 становится недостаточно, коэффициент CPI перешагивает планку в 20. Что вполне ожидаемо.
Но счетчики измерения производительности позволяют и глубже взглянуть на происходящее внутри ЦП. При этом следует помнить о различиях в реализации процессоров. Сейчас нас интересуют подробности работы с кэшем, так что соответствующие события и нужно рассматривать. Эти события, их имена и что именно они считают - всё зависит от конкретного процессора. Вот почему так сложно разобраться с использованием oprofile, несмотря на его простой интерфейс: пользователю приходится самостоятельно искать информацию о счетчиках производительности. В разделе 10 мы подробно рассмотрим несколько различных ЦП.
В случае использования Core 2 нам нужны события L1D_REPL, DTLB_MISSES и L2_LINES_IN. Последнее может измерять как все промахи разом, так и отдельно промахи, к которым привели инструкции, а не аппаратная предвыборка. На рисунке 7.2 показаны результаты выполнения теста случайной выборки.
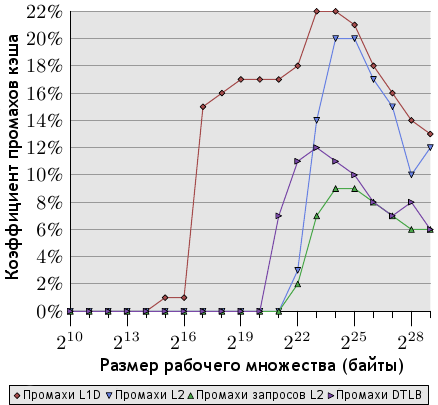
Рисунок 7.2: Промахи кэша (случайная выборка)
Коэффициенты вычислены с использованием количества всех выполненных команд (INST_RETIRED). Это значит, что считались также и те команды, которые не касаются памяти. А это, в свою очередь, значит, что число команд, связанных с памятью и вызвавших промах кэша, еще больше, чем показано на графике.
Число промахов L1d гораздо выше всех остальных потому, что в процессорах Intel используются инклюзивные (включающие, inclusive) кэши, то есть каждый промах L2 включает в себя также и промах L1d. Размер кэша L1d нашего ЦП составляет 32 Кб и мы видим, что, как и ожидалось, промахи L1d начинаются как раз когда рабочее множество достигает этого размера (промахи между отметками в 16 и 32 Кб вызваны использованием кэша, не связанным со структурой списка данных). Обратите внимание, что благодаря аппаратной предвыборке коэффициент промахов L1d держится на 1% при размерах рабочего множества до 64 Кб включительно, а затем прямо-таки взлетает.
Коэффициент промахов L2 держится на нуле до полного исчерпания объема кэша L2; пара промахов в связи с побочными использованиями кэша особо погоды не делают. Но как только размер L2 (221 байт) превышается, коэффициент промахов возрастает. Важно отметить, что коэффициент промахов запросов L2 (L2 demand miss rate) нулю не равен. Это говорит нам о том, что устройство аппаратной предвыборки загружает не все строки кэша, необходимые инструкциям в дальнейшем. И это ожидаемо: идеальная предвыборка невозможна ввиду случайности запросов доступа. Сравните с данными по последовательному чтению, показанными на рисунке 7.3.
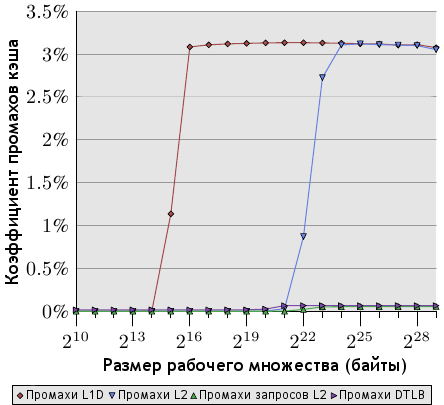
Рисунок 7.3. Промахи кэша (последовательная выборка)
Здесь мы видим, что промахи запросов L2 фактически отсутствуют (обратите внимание - масштаб рисунков 7.2 и 7.3 различен). То есть в случае последовательного доступа аппаратная предвыборка работает идеально и почти все промахи L2 вызваны самим устройством предвыборки. Коэффициенты промахов L1d и L2 одинаковы - это значит, что все промахи L1d обрабатываются в L2 без дальнейших задержек. Случай идеальный для любых программ, но, естественно, едва ли достижимый в реальных условиях.
Четвертый график на обоих рисунках - коэффициент промахов DTLB (Intel использует отдельные буферы TLB для кода и данных, и DTLB - это буфер данных). При случайном доступе его значение достаточно велико и заметно влияет на задержки. Любопытно, что эти промахи начинаются еще до появления промахов L2. В случае последовательного доступа промахи DTLB отсутствуют.
Вернувшись к примеру с перемножением матриц (в разделе 6.2.1) и примеру кода в разделе 9.1, сможем задействовать еще три счетчика. А именно, SSE_PRE_MISS, SSE_PRE_EXEC и LOAD_HIT_PRE могут быть использованы для оценки эффективности программной предвыборки. Запустив код из раздела 9.1, получим следующие результаты:
Описание Коэффициент Полезные предвыборки NTA 2.84% Поздние предвыборки NTA 2.65%
Низкое значение коэффициента полезной предвыборки NTA говорит о том, что многие команды предвыборки выполняются для уже загруженных строк кэша, когда никаких действий не требуется. То есть на декодирование таких команд и просмотр кэша процессор тратит время впустую. Тем не менее, слишком сильно придираться к коду не стоит. Многое зависит от объема кэшей в используемом процессоре, к тому же свою лепту вносит и само устройство аппаратной предвыборки.
Низкое значение коэффициента поздней предвыборки NTA на самом деле обманчиво. Этот коэффициент показывает, что 2,65% всех команд предвыборки выполняются слишком поздно. Инструкция, которой нужны данные, выполяется еще до того, как данные успевают оказаться в кэше. Нужно помнить, что всего лишь 2,84%+2,65%=5,5% всех команд предвыборки оказались полезными. А из всех полезных, 48% были выполнены с опозданием. Следовательно, код можно оптимизировать, учитывая следующие моменты:
- большинство команд предвыборки бесполезны.
- команды предвыборки следует использовать с учетом аппаратной основы.
В качестве упражнения пусть читатель попробует определить лучшее решение для доступного ему оборудования. Точная спецификация аппаратной части играет очень большую роль. На процессорах Core 2 задержка арифметических операций SSE составляет 1 такт. В прошлых версиях она составляла 2 такта, следовательно, устройство аппаратной предвыборки и команды предвыборки имели больше времени для загрузки данных.
Чтобы определить, нужно в данном случае использовать предвыборку или нет, используется программа opannotate. Она показывает исходники или ассемблерный код программы и выделяет команды с опознанным событием. Обратите внимание, что возможны два источника неопределенности:
- Oprofile выполняет вероятностное профилирование. Это значит, что записывается только каждое N-ое событие (порог N свой для каждого события, при этом имеется некое минимальное значение), дабы не слишком замедлять работу системы. Может случиться так, что какие-то строки кода вызывают сотню событий и тем не менее их не будет в отчете.
- Не все события записываются верно. К примеру, значение счетчика инструкций на момент записи определенного события может оказаться неправильным. Дать стопроцентно верное значение мешает мультискалярность процессоров. Хотя на некоторых процессорах есть и точные события.
Аннотированные листинги могут быть полезны не только для определения информации касательно предвыборки. Каждое событие записывается с указателем команды, а значит, можно найти и другие "горячие точки" программы. Области кода с большим количеством событий INST_RETIRED выполняются часто и потому заслуживают пристального внимания. Области, где происходит много промахов кэша, требуют использования инструкций предвыборки для избежания последних.
Есть тип событий, который можно отслеживать без аппаратной поддержки. Это ошибки отсутствия страниц, или страничные ошибки (page faults). За исправление этих ошибок отвечает операционная система, и в случае появления таковых, она же их и подсчитывает. Системой выделяются два вида страничных ошибок:
Легкие страничные ошибки (Minor Page Faults)
К ним относятся ошибки отсутствия анонимных (например, не связанных с файлами) страниц, которые пока еще не были использованы, ошибки копирования при записи (copy-on-write), а также ошибки страниц, содержимое которых уже находится где-то в памяти.
Значительные страничные ошибки (Major Page Faults)
Для разрешения этих ошибок необходим доступ к диску для получения связанных с файлами (или находящихся в файле подкачки) данных.
Очевидно, что значительные страничные ошибки обходятся системе значительно дороже легких. Но и последние тоже нельзя сбрасывать со счетов. В обоих случаях необходимо обратиться к ядру, найти новую страницу, очистить ее либо заполнить соответствующими данными, после чего отразить изменения в дереве таблиц страниц. Последний шаг потребует синхронизации с другими задачами чтения или изменения дерева таблиц страниц, что приведет к еще большим задержкам.
Легче всего получить информацию о количестве страничных ошибок - использовать инструмент time. Только заметьте: оригинальный инструмент, а не тот, что встроен в оболочку. Результаты вывода можно лицезреть на рисунке 7.4. {Обратная косая (бэкслэш) в начале предотвращает вызов встроенных команд.}
$ \time ls /etc [...] 0.00user 0.00system 0:00.02elapsed 17%CPU (0avgtext+0avgdata 0maxresident)k 0inputs+0outputs (1major+335minor)pagefaults 0swapsРисунок 7.4. Вывод утилиты time
Нас интересует последняя строка. Утилита докладывает о том, что произошла одна значительная и 335 легких страничных ошибок. Точные цифры постоянно меняются; в частности, если сразу же запустить программу повторно, скорее всего не будет обнаружено ни одной значительной страничной ошибки. Если программа выполняет одно и то же действие и окружающие условия не меняются, то общее количество страничных ошибок будет постоянной величиной.
Особенной фазой по отношению к страничным ошибкам является запуск программы. Каждая используемая страница вызовет страничную ошибку; внешне это проявляется (особенно в приложениях с графическим интерфейсом) в том, что чем больше страниц памяти используется, тем дольше программа запускается. В разделе 7.5 познакомимся с утилитой, позволяющей оценивать именно этот момент.
Заглянув внутрь time, можно обнаружить, что используется функциональность rusage. Системный вызов wait4 заполняет объект struct rusage, пока родитель ожидает завершения дочернего процесса; это именно то что нужно для инструмента, подобного time. Но процесс также может запросить информацию об использовании ресурсов (отсюда и пошло название rusage - Resource Usage, использование ресурсов) как своих, так и ресурсов завершенных дочерних процессов.
#include <sys/resource.h> int getrusage(__rusage_who_t who, struct rusage *usage)
Параметр who определяет процесс, о котором запрашивается информация. На данный момент, определены значения RUSAGE_SELF (о себе) и RUSAGE_CHILDREN (о дочерних процессах). Коэффициент использования ресурсов дочерними процессами определяется в момент завершения каждого из них. Эта величина - общая для всех дочерних процессов, а не для каждого из них по отдельности. В ближайшем будущем планируется реализовать возможность запроса информации об отдельных потоках, в связи с чем появится и третье значение - RUSAGE_THREAD. Структура rusage определена таким образом, что может содержать все типы показателей, включая время выполнения, количество посланных сообщений IPC, используемую память и число страничных ошибок. Последнее можно найти в членах ru_minflt и ru_majflt данной структуры.
Программист, желающий определить, снижается ли производительность его программы из-за страничных ошибок и где именно это происходит, может регулярно проверять данные члены и затем сравнивать полученные значения с предыдущими.
Такую информацию видно и "снаружи", если запрашивающий имеет необходимые привилегии. Псевдофайл /proc/<PID>/stat, где <PID> - идентификатор интересующего нас процесса, содержит информацию (в виде пар чисел) о страничных ошибках в полях с десятого по четырнадцатое. Эти пары представляют собой общее количество легих и значительных страничных ошибок процесса и его дочерних процессов соответственно.
7.2 Моделирование кэшей ЦПУ
В то время как техническое описание работы кэша относительно легко понять, гораздо тяжелее разобраться, как именно с ним взаимодействует конкретная программа. Программисты не работают напрямую с адресами, ни с абсолютными, ни с относительными. Адреса определяются, во-первых, компоновщиком; а во-вторых - уже во время выполнения программы, ядром и динамическим компоновщиком. Ожидается, что полученный в результате компоновки код сможет работать со всеми возможными адресами; в исходном же коде нет ни намека на то, какие адреса использовать. Вот поэтому понять, как именно программа работает с памятью, и бывает довольно тяжело. {При программировании на низком уровне, близком к аппаратному, ситуация может отличаться - но такой вариант не является типичным для нормального программирования и вообще возможен только в особых случаях, например с устройствами, отображаемыми в память.}
Разобраться в использовании кэша могут помочь инструменты профилирования уровня ЦПУ, вроде oprofile, описанного в разделе 7.1. Предоставляемые ими результаты привязаны к фактически используемому оборудованию, и могут быть собраны относительно быстро, если нет необходимости в большей детализации. Но если углубленная детализация все-таки потребуется, oprofile выходит из игры: слишком часто придется прерывать работу потока, что недопустимо. Более того, чтобы протестировать поведение программы на разном оборудовании, придется как-то находить другие машины и выполнять программу на них. Иногда (а скорее - очень и очень часто) это попросту невозможно. Возьмем пример - рисунок 3.8. Чтобы собрать такие данные с помощью oprofile, потребовалось бы 24 компьютера разных конфигураций, многих из которых вообще не существует на данный момент.
На деле те данные были получены с использованием программы моделирования кэша. Программа носит имя cachegrind и использует инструментарий valgrind, который первоначально разрабатывался для отладки работы с памятью. Valgrind моделирует выполнение программы и при этом поддерживает различные расширения, вроде cachegrind, позволяющие в ней копаться. Утилита cachegrind использует эти возможности для перехвата всех адресных обращений к памяти; затем она моделирует работу кэшей L1i, L1d и L2 с заданными объемами, размерами строк кэша и соответствующей ассоциативностью.
Для применения утилиты необходимо запустить программу, вызвав её через valgrind:
valgrind --tool=cachegrind command arg
Это простейшая форма запуска: программа command запускается с параметром arg и моделированием трех кэшей, в которых используются размеры и ассоциативность, аналогичные таковым на используемом процессоре. Часть результатов выводится при стандартной ошибке во время выполнения программы; показывается общая статистика использования кэша, как показано на рисунке 7.5.
==19645== I refs: 152,653,497 ==19645== I1 misses: 25,833 ==19645== L2i misses: 2,475 ==19645== I1 miss rate: 0.01% ==19645== L2i miss rate: 0.00% ==19645== ==19645== D refs: 56,857,129 (35,838,721 rd + 21,018,408 wr) ==19645== D1 misses: 14,187 ( 12,451 rd + 1,736 wr) ==19645== L2d misses: 7,701 ( 6,325 rd + 1,376 wr) ==19645== D1 miss rate: 0.0% ( 0.0% + 0.0% ) ==19645== L2d miss rate: 0.0% ( 0.0% + 0.0% ) ==19645== ==19645== L2 refs: 40,020 ( 38,284 rd + 1,736 wr) ==19645== L2 misses: 10,176 ( 8,800 rd + 1,376 wr) ==19645== L2 miss rate: 0.0% ( 0.0% + 0.0% )Рисунок 7.5. Общие выходные данные cachegrind
Дано общее число команд и обращений к памяти, количество промахов кэшей L1i/L1d и L2, коэффициенты промахов и т.п. Утилита может даже разделять обращения к L2 на запросы инструкций и запросы данных, а все обращения к данным - на запросы чтения и запросы записи.
А еще интереснее становится, если изменить параметры моделируемых кэшей и сравнить результаты. Чтобы заставить cachegrind игнорировать параметры кэшей используемого процессора и применять указанные в командной строке, используются параметры --I1, --D1 и --L2. Ну например, строка
valgrind --tool=cachegrind --L2=8388608,8,64 command arg
приведет к моделированию кэша L2 объемом 8 Мб с 8-канальной ассоциативностью и строкой кэша размером 64 байта. Обратите внимание, что параметр --L2 в командной строке идет перед именем моделируемой программы.
Этим возможности cachegrind не исчерпываются. Перед завершением процесса cachegrind создает файл с именем cachegrind.out.XXXXX, где XXXXX - идентификатор процесса (PID). В файле содержится как общая суммарная информация, так и подробности использования кэша каждой функцией исходного кода. Данные можно просмотреть с помощью программы cg_annotate.
Выходные данные, предоставляемые программой, содержат общую информацию об использовании кэша, которая была показана при завершении процесса, а также подробности использования строк кэша каждой функцией программы. Для связи данных с соответствующими функциями необходимо, чтобы cg_annotate могла сопоставить адреса функциям. То есть, для наилучшего результата должна быть доступна информация отладки. Если таковая отсутствует, то могут помочь таблицы идентификаторов ELF, но, поскольку внутренние идентификаторы отсутствуют в динамической таблице, результаты будут неполными. На рисунке 7.6 показана часть выходных данных для того же прогона программы, что и на рисунке 7.5.
--------------------------------------------------------------------------------
Ir I1mr I2mr Dr D1mr D2mr Dw D1mw D2mw file:function
--------------------------------------------------------------------------------
53,684,905 9 8 9,589,531 13 3 5,820,373 14 0 ???:_IO_file_xsputn@@GLIBC_2.2.5
36,925,729 6,267 114 11,205,241 74 18 7,123,370 22 0 ???:vfprintf
11,845,373 22 2 3,126,914 46 22 1,563,457 0 0 ???:__find_specmb
6,004,482 40 10 697,872 1,744 484 0 0 0 ???:strlen
5,008,448 3 2 1,450,093 370 118 0 0 0 ???:strcmp
3,316,589 24 4 757,523 0 0 540,952 0 0 ???:_IO_padn
2,825,541 3 3 290,222 5 1 216,403 0 0 ???:_itoa_word
2,628,466 9 6 730,059 0 0 358,215 0 0 ???:_IO_file_overflow@@GLIBC_2.2.5
2,504,211 4 4 762,151 2 0 598,833 3 0 ???:_IO_do_write@@GLIBC_2.2.5
2,296,142 32 7 616,490 88 0 321,848 0 0 dwarf_child.c:__libdw_find_attr
2,184,153 2,876 20 503,805 67 0 435,562 0 0 ???:__dcigettext
2,014,243 3 3 435,512 1 1 272,195 4 0 ???:_IO_file_write@@GLIBC_2.2.5
1,988,697 2,804 4 656,112 380 0 47,847 1 1 ???:getenv
1,973,463 27 6 597,768 15 0 420,805 0 0 dwarf_getattrs.c:dwarf_getattrs
Рисунок 7.6: Выходные данные cg_annotate
Столбцы Ir, Dr и Dw показывают общее использование кэша, а не промахи, которые, в свою очередь, показаны в оставшихся двух столбцах. Эти данные можно использовать для поиска области кода, приводящей к большинству промахов кэша. В первую очередь, пожалуй, стоит сконцентрироваться на промахах L2, а затем уже переходить к оптимизации промахов L1i/L1d.
cg_annotate может детализировать данные еще сильнее. Если дано имя исходного файла, утилита сможет пометить каждую строку (кроме имени программы) количеством промахов и попаданий кэша, соответствующих данной строке. Такая информация позволит программисту точно выявить строку, приводящую к промахам. Интерфейс программы сыроват: на момент написания данной работы, файл данных cachegrind и исходный файл должны находиться в одной директории.
А теперь снова следует повторить: cachegrind - утилита моделирования, которая не использует аппаратные измерения процессора. Фактическая реализация кэшей процессора может очень и очень сильно отличаться. Cachegrind моделирует алгоритм вытеснения LRU (Least Recently Used), который для кэшей с большим уровнем ассоциативности явно слишком дорог. Более того, при моделировании не принимаются во внимание системные вызовы и контекстные переключения, а ведь и те и другие могут занять большую часть L2 и переполнить L1i/L1d. В итоге число промахов кэша при модуляции оказывается меньше, чем оно есть на самом деле в реальных условиях. Но тем не менее, cachegrind - отличная утилита для изучения работы программы с памятью и сопутствующих проблем.
7.3 Оценка использования памяти
Первый шаг к оптимизации использования памяти - узнать, сколько памяти выделяет для себя программа и, если возможно, где именно (в каком месте кода). К счастью, для данной цели существуют простые в применении утилиты, даже не требующие рекомпиляции или какой-либо модификации испытуемой программы.
Для первого такого инструмента, massif, важно не удалять информацию отладки, автоматически генерируемую компилятором. Данная утилита предоставляет обзор использования памяти за некоторый период времени. На рисунке 7.7 показан пример выходных данных.
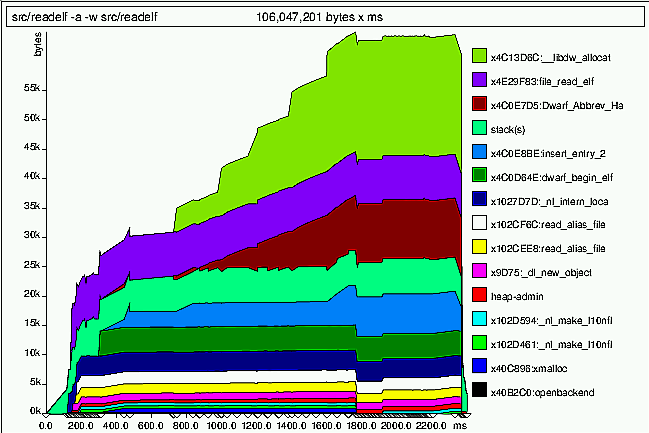
Рисунок 7.7. Выходные данные massif
Как и cachegrind (раздел 7.2), massif использует инструментарий valgrind. Запускается через
valgrind --tool=massif command arg
где command arg - наблюдаемая программа и ее параметр(ы). В процессе моделирования работы распознаются все вызовы функций выделения памяти. Место и время каждого вызова записываются; выделенный объем памяти добавляется к памяти, выделенной предыдущими вызовами из этого же места, а также к общему объему памяти всей программы. По тому же алгоритму обрабатываются и функции, освобождающие память, только, естественно, наоборот: размер освобожденного блока вычитается из соответствующих суммарных объемов. В дальнейшем собранная таким образом информация может быть использована для построения диаграммы, описывающей использование памяти за весь жизненный цикл программы и устанавливающей соответствие каждого момента времени месту кода, откуда было вызвано выделение памяти. Перед завершением процесса, massif создает два файла: massif.XXXXX.txt и massif.XXXXX.ps, где XXXXX в обоих случаях - идентификатор процесса (PID). Файл .txt содержит суммарную информацию по использованию памяти для всех мест вызова, а .ps вы видите на рисунке 7.7.
Также massif может контролировать использование стека программой, что может помочь определить общий объем памяти, которую занимает программа. Но иногда это невозможно. Бывает, что valgrind не может определить границы стека - например, когда используется signaltstack или стеки потоков. В таких случаях не имеет смысла добавлять размеры этих стеков к общей сумме. Есть и другие примеры, когда контролировать стек бессмысленно. В любом из этих случаев massif следует запускать с дополнительным параметром --stacks=no. Обратите внимание, это параметр valgrind, и поэтому он ставится перед именем испытуемой программы.
В некоторых программах используются их собственные функции выделения памяти, либо т.н. "интерфейсные" функции, предоставляющие интерфейс вызова системных функций выделения памяти. В первом случае выделение памяти проходит незамеченным; во втором - записанные места вызова несут дезинформацию, поскольку записывается адрес вызова внутри интерфейсной функции, а не адрес самой этой функции. В связи с этим, существует возможность дополнять список функций выделения памяти дополнительными функциями. Параметр --alloc-fn=xmalloc говорит программе, что xmalloc - тоже функция выделения памяти, что нередко в программах GNU. Тогда будут записываться вызовы самой xmalloc, а не вызовы выделения памяти изнутри нее.
Вторая утилита - memusage; это часть библиотеки GNU C. Представляет собой упрощенную версию massif (и существовавшая задолго до появления последней). Всё, что она контролирует - общий объем памяти, выделенной из кучи (включая возможные вызовы mmap и им подобных, если используется параметр -m), и, при необходимости, использование стека. Результаты могут быть показаны в виде диаграммы либо общего использования памяти за время работы, либо в виде разбиения по вызовам функций выделения памяти. Диаграммы создаются по отдельности сценарием memusage, который (как и valgrind), необходимо использовать для запуска приложения:
memusage command arg
При использовании параметра -p IMGFILE диаграмма будет создана в файле IMGFILE с расширением PNG. Код, собирающий информацию, запускается прямо в самой программе, это не моделирование, в отличие от valgrind. Следовательно, memusage гораздо быстрее, чем massif, и используется даже тогда, когда утилита massif бесполезна. Помимо суммарного потребления памяти, программа также записывает размеры выделенной памяти при каждом вызове и выводит их в виде гистограммы. Эта информация также показывается при возникновении ошибки.
Иногда программу, которую нужно исследовать, невозможно (или запрещено) запускать напрямую. Например, стадия компиляции gcc, запускаемая драйвером gcc. В таких случаях имя исследуемой программы необходимо предоставить сценарию memusage, передав его через параметр -n NAME. Также этот параметр полезен, если исследуемая программа запускает другие программы. В случае, когда имя программы не указано, профилированию подвергаются все запускаемые приложения.
У обеих утилит, massif и memusage, есть дополнительные параметры. Когда программисту нужна дополнительная функциональность, сперва стоит прочесть мануал или справку, дабы убедиться, не реализована ли уже данная функциональность.
Теперь мы знаем, каким образом собираются данные касательно выделения памяти, и далее необходимо обсудить, как эти данные можно интерпретировать в контексте использования памяти и кэша. Главные моменты эффективного динамического распределения памяти - последовательное выделение и компактность выделенной области памяти. Таким образом мы возвращаемся к повышению эффективности предвыборки и снижению количества промахов кэша.
Когда программе нужно считать некоторое количество данных для последующей обработки, это можно организовать, создав список, каждый элемент которого содержит новый элемент данных. Потери при таком методе выделения памяти теоретически должны быть минимальны (один указатель для простого связанного списка), но на деле использование таких данных кэшем может чрезвычайно снизить производительность.
Например, одна из проблем - нет никаких гарантий, что последовательно выделенная память окажется в лежащих рядом областях. Тому есть множество возможных причин:
- адреса блоков памяти внутри большого участка, управляемого распределителем памяти, возвращаются от конца к началу;
- свободное место на участке памяти заканчивается, и происходит переход к новому участку, в совсем другой области адресного пространства;
- запросы на выделение разных объемов памяти обслуживаются разными пулами памяти;
- чередование выделений памяти разными потоками многопоточных приложений.
Если нужно распределить память для данных заранее для будущей обработки, применение связанного списка - явно плохая идея. Нет никакой гарантии (и даже вероятности), что соседние элементы списка окажутся соседними и в памяти. Для гарантии смежности выделенных областей память ни в коем случае нельзя распределять мелкими участками. Необходимо использовать другой слой работы с памятью; и программист легко может его применить. Я имею в виду реализацию obstack, доступную в библиотеке GNU C. Этот распределитель запрашивает большие блоки памяти у системного распределителя и затем уже из этих блоков выделяет произвольные области, маленькие или не очень. Области, выделяемые таким образом, всегда будут расположены последовательно, если только не закончится место в том самом большом блоке. Что, учитывая объемы, запрашиваемые на выделение, происходит довольно редко. Применение obstack не означает полный отказ от стандартного распределителя памяти, поскольку obstack ограничен в возможностях освобождения объектов. Подробнее см. руководство к библиотеке GNU C.
Итак, каким же образом, используя диаграммы, можно понять, где лучше использовать obstack (или другие подобные приемы)? Точное место возможной оптимизации нельзя определить, не обратившись к исходникам, но диаграмма помогает выбрать отправную точку для поисков. Если из одного и того же места происходит много запросов на выделение памяти, значит, тут может помочь выделение большого блока (см.obstack). На рисунке 7.7 вероятный кандидат на оптимизацию наблюдается по адресу 0x4c0e7d5. На промежутке от 800мс и до 1800мс с начала работы это единственная растущая область, ну за исключением верхней, зеленой. Более того, возрастание не резкое - значит, имеем дело с большим числом выделений относительно малых объемов памяти. Вне всяких сомнений, это наш кандидат на применение технологии obstack или ей подобных.
Другая проблема, которую помогают увидеть диаграммы - слишком большое суммарное число попыток выделения памяти. Особенно легко это заметить, если диаграмма строится в зависимости не от времени, а от количества вызовов (установлено по умолчанию в memusage). В этом случае пологий склон диаграммы означает большое количество выделений малых объемов памяти. Утилита memusage не может сказать, где именно происходят запросы выделения, но это "лечится" сравнением с выводом massif, а иногда программист и сам сразу может определить проблемное место. Множество мелких запросов выделения памяти следует объединить, чтобы достичь последовательного использования памяти.
Касательно последнего случая есть еще один момент, не менее важный: множество небольших выделений приводит к увеличению административной (управляющей) информации. Само по себе это не страшно. На диаграмме вывода massif (рис.7.7) область такой информации называется "heap-admin" и она довольно мала. Но в зависимости от реализаций malloc эта административная информация может выделяться вместе с блоками данных, в той же области памяти. Что сейчас и имеет место в текущей реализации malloc в библиотеке GNU C: каждый выделенный блок начинается с двухсловного (минимум) заголовка: 8 байт для 32-битных платформ, 16 байт для 64-битных. К тому же, размеры блоков обычно немного больше, чем нужно, из-за особенностей управления памятью (размеры блоков округляются до определенных значений).
Всё вышесказанное означает, что память, используемая программой, смешивается с памятью, используемой распределителем исключительно для административных целей. И мы получаем что-то вроде этого:

Каждый блок представляет собой одно слово (word) памяти и всего на этой небольшой области мы видим четыре выделенных блока. Заголовки и заполнение незначащей информацией привели к издержкам (потерям полезного места) в 50%. Такое расположение заголовка автоматически снижает коэффициент эффективной предвыборки процессора на те же 50%. Если бы блоки обрабатывались последовательно (для получения максимальной пользы от предвыборки), процессор бы считал все слова, содержащие заголовки и заполнители, в кэш, несмотря на то что само приложение никогда не будет к ним обращаться ни для записи, ни для чтения. Заголовки используются только средой выполнения, а она вступает в дело только при освобождении блока памяти.
Можно прийти к выводу, что следует использовать другую реализацию, дабы поместить административную информацию отдельно. Несомненно, в некоторых реализациях так и делается, и это может быть полезно. Но при этом необходимо помнить о множестве нюансов, и не в самую последнюю очередь - о безопасности. Независимо от того, к чему мы придем в будущем, проблема заполнения блоков [незначащей информацией] никогда не исчезнет (а одни эти "пустышки", без учета заголовков, занимают 16% всего объема памяти в нашем примере). Этого можно избежать только если программист возьмет на себя прямой контроль за выделением памяти. "Пустышки" также могут появиться в связи с требованиями выравнивания памяти, но и этот момент - во власти программиста.
7.4 Улучшаем прогнозирование ветвлений
В разделе 6.2.2 были упомянуты два метода улучшения работы L1i с помощью прогнозирования ветвлений и изменения порядка блоков, а именно: явное (статическое) предсказание через __builtin_expect и оптимизацию по профилю (profile guided optimization = PGO). Правильное прогнозирование ветвлений в первую очередь влияет на производительность, но в данный момент нас интересует иное - оптимизация использования памяти.
Использовать __builtin_expect (а лучше - макросы likely и unlikely) достаточно просто. Определения помещаются в центральном заголовке, и компилятор берет на себя всё остальное. Хотя есть тут небольшая проблема: программист может легко перепутать определения - использовать likely вместо unlikely, и наоборот. Даже если применять инструмент вроде oprofile для контроля за ошибочным прогнозированием ветвлений и промахами L1i, подобные проблемы сложно обнаружить.
Тем не менее, есть один простой способ. Листинг в разделе 9.2 демонстрирует альтернативные определения макросов likely и unlikely, с помощью которых прямо при выполнении программы отслеживается, верно заданы явные предсказания или же вкралась ошибка. Затем программист или тестер проверяет результаты и вносит поправки при необходимости. Производительность программы в расчет при этом не берется - просто проверяются статически заданные программистом предсказания, не более. С подробностями и исходниками можно ознакомиться в вышеупомянутом разделе.
Механизм PGO в наши дни довольно легко использовать через gcc. Процесс состоит из трех шагов, при этом необходимо соблюдать некоторые требования. Во-первых, все исходные файлы должны быть скомпилированы с дополнительным параметром -fprofile-generate. Этот параметр должен использоваться при всех запусках компилятора и должен быть передан команде, компонующей программу. Смешивать объектные файлы, скомпилированные с применением этого параметра и без него - теоретически можно, но с последними могут возникнуть проблемы.
Компилятор создает исполняемый файл, работающий как обычно, но только он значительно больше и медленнее, поскольку записывает (и сохраняет) всю информацию о ветвлениях. Компилятор также создает файл с расширением .gcno для каждого входного файла. Этот файл содержит информацию относительно ветвлений в коде и его нужно сохранить на будущее.
Как только исполняемый файл будет готов, следует выполнить репрезентативный набор тестов с разными рабочими нагрузками. Какая бы нагрузка не использовалась, в итоге исполняемый файл будет оптимизирован для эффективного выполнения соответствующей задачи. Неоднократные прогоны программы в пределах одного теста возможны - и, в общем, даже необходимы; каждое выполнение вносит свой вклад в итоговый выходной файл. Перед завершением работы программы данные, собранные в течение текущего прогона, записываются в файлы с расширением .gcda, которые создаются в каталоге с исходниками. Программу можно запускать из любого каталога, исполняемый файл можно копировать, но каталог с исходниками в любом случае должен быть доступен для записи. Еще раз: для каждого входного файла исходников создается свой выходной файл. В случае нескольких прогонов важно, чтобы файлы .gcda, созданные во время предыдущего прогона, оставались в том же каталоге с исходниками, иначе итоговые данные будет невозможно собрать в один файл.
После завершения всех тестовых прогонов программу следует перекомпилировать. Необходимо и крайне важно, чтобы файлы .gcda оставались в том же каталоге, где находятся файлы исходников. Эти файлы нельзя перемещать, иначе компилятор их попросту не найдет, что приведет к несовпадению контрольных сумм. При повторной компиляции параметр -fprofile-generate нужно заменить на -fprofile-use. Важно не вносить в исходники никаких изменений, могущих повлиять на генерируемый исполняемый код. Это значит: можно изменять форматирование (пробелами) и редактировать комментарии, но вот добавление новых ветвлений или блоков приводит к недействительности всей собранной информации, и компиляция в этом случае окончится неудачей.
Вот и всё, что требуется от программиста; и вправду довольно простой процесс. Самое главное, на что необходимо обратить внимание - это выбор подходящих репрезентативных тестов для сбора информации. Если тестовые нагрузки не будут совпадать с реальными будущими условиями эксплуатации программы, выполненная оптимизация принесет больше вреда чем пользы. Поэтому в общем случае трудно использовать PGO для создания библиотек, ведь они могут быть использованы в самых разных сценариях, иногда чуть ли не противоположных. В связи с этим, если нет уверенности в схожести условий использования, то обычно лучше полагаться исключительно на статическое прогнозирование ветвлений с применением __builtin_expect.
Пара слов о файлах .gcno и .gcda. Это бинарные файлы, первоначально не предназначенные для просмотра. Тем не менее, при необходимости для их исследования можно применить инструмент gcov, также являющийся частью пакета gcc. В основном эта утилита применяется для анализа покрытия (coverage, отсюда и название), но при этом используется тот же формат файлов, что и для PGO. Утилита gcov генерирует выходные файлы с расширением .gcov для каждого исходного файла с исполняемым кодом (обычно включая системные заголовки). Эти выходные файлы представляют собой листинги, аннотированные в соответствии с заданными gcov параметрами - могут быть показаны вероятности, счетчик ветвлений и т.п.
7.5 Оптимизация страничных ошибок
В операционных системах с замещением страниц по требованию (Linux - одна из таких систем) всё, что делает вызов mmap, - изменяет таблицы страниц. А именно - он гарантирует, что в случае обращения к страницам, связанным с файлами, соответствующие данные (файлы) будут доступны, а в случае обращения к анонимной памяти будут предоставлены страницы, инициализированные нулями. То есть, при вызове mmap в таких системах не происходит собственно выделения памяти. {Не согласны и хочется возразить? Погодите маленько, далее мы поговорим об исключениях.}
Память выделяется при первом обращении к странице, будь то запрос чтения или записи, либо при выполнении кода. В ответ на возникающую в таком случае страничную ошибку ядро берет на себя управление и определяет (с помощью дерева таблиц страниц), какие данные должна содержать страница. Такая обработка страничных ошибок недешево обходится, но тем не менее именно это происходит с каждой страницей, используемой процессом.
Для минимизации стоимости страничных ошибок (стоимость здесь и далее - в смысле "потери производительности") необходимо снижать общее число используемых страниц памяти. Этой цели может послужить соответствующая оптимизация исходного кода. Для уменьшения стоимости определенной области кода (например, кода инициализации), можно реорганизовать его в таком порядке, чтобы в данной области количество затрагиваемых страниц памяти было минимально. Но не так уж просто определить "правильный" порядок.
Автор данной работы написал утилиту на основе инструментария valgrind, позволяющую контролировать появление страничных ошибок. Но контролировать не количество, а причину их возникновения. Инструмент pagein выдает информацию о порядке и времени возникновения страничных ошибок. Выходные данные, записываемые в файл pagein.<PID>, выглядят как показано на рисунке 7.8.
0 0x3000000000 C 0 0x3000000B50: (within /lib64/ld-2.5.so) 1 0x 7FF000000 D 3320 0x3000000B53: (within /lib64/ld-2.5.so) 2 0x3000001000 C 58270 0x3000001080: _dl_start (in /lib64/ld-2.5.so) 3 0x3000219000 D 128020 0x30000010AE: _dl_start (in /lib64/ld-2.5.so) 4 0x300021A000 D 132170 0x30000010B5: _dl_start (in /lib64/ld-2.5.so) 5 0x3000008000 C 10489930 0x3000008B20: _dl_setup_hash (in /lib64/ld-2.5.so) 6 0x3000012000 C 13880830 0x3000012CC0: _dl_sysdep_start (in /lib64/ld-2.5.so) 7 0x3000013000 C 18091130 0x3000013440: brk (in /lib64/ld-2.5.so) 8 0x3000014000 C 19123850 0x3000014020: strlen (in /lib64/ld-2.5.so) 9 0x3000002000 C 23772480 0x3000002450: dl_main (in /lib64/ld-2.5.so)Рисунок 7.8: Выходные данные утилиты pagein
Второй столбец содержит адрес запрошенной страницы. Содержит она код или данные, указывается в третьем столбце, соответственно `C' (Code) - код, `D' (Data) - данные. Четвертый столбец содержит количество тактов, прошедших с момента первой страничной ошибки. Оставшаяся часть строки - попытка valgrind'а определить имя для адреса, вызвавшего данную страничную ошибку. Само значение адреса всегда верно, но с именем могут быть несоответствия, если нет доступа к информации отладки.
В примере, показанном на рисунке 7.8, выполнение начинается с адреса 0x3000000B50, который запрашивает страницу по адресу 0x3000000000. Вскоре запрашивается следующая за ней страница, на этот раз функцией под названием _dl_start. Код инициализации обращается к переменной на странице 0x7FF000000. Это происходит по прошествии всего 3,320 тактов после первой страничной ошибки и больше всего похоже на вторую инструкцию программы (от первой ее отделяют лишь три байта). Давайте взглянем на саму программу: видим нечто необычное относительно доступа к памяти. А именно, обращает на себя внимание инструкция call, которая вроде бы не загружает и не записывает никаких данных. Но она сохраняет адрес возврата в стек, что, собственно, мы и наблюдали в выходном отчете. Конечно, имеется в виду не официальный стек процесса, а внутренний стек приложения, используемый valgrind. Следовательно, при интерпретации результатов pagein важно помнить, что valgrind может внести некоторые искажения.
Выходные данные pagein можно использовать для определения, какие последовательности инструкций программы в идеале должны быть расположены рядом друг с другом. С первого же взгляда на код /lib64/ld-2.5.so видно, что первые команды сразу вызывают функцию _dl_start, и что два этих места расположены на разных страницах. Таким образом, реорганизация исходника путем перемещения кодовых последовательностей на одну и ту же страницу памяти может помочь избежать страничной ошибки - или хотя бы отсрочить её. Но пока что определение максимально эффективной организации кода - процесс обременительный. Поскольку повторные запросы страниц утилитой не записываются, то чтобы увидеть результаты изменений, приходится использовать метоб проб и ошибок. Путем анализа диаграммы вызовов можно предсказать возможные последовательности запросов, что поможет ускорить процесс сортировки функций и переменных.
На очень грубом, поверхностном уровне, последовательности запросов можно увидеть, изучая объектные файлы, из которых в итоге создается исполняемый модуль или DSO (Dynamic Shared Object = динамически разделяемый объект). Начиная с одной или нескольких отправных точек (например, имен функций), можно вычислять цепочки зависимостей. На уровне объектных файлов это неплохо работает даже без приложения особых усилий. На каждом проходе определяем, какие из объектных файлов содержат нужные нам функции и переменные. Начальный набор файлов необходимо определить однозначно. Затем выделяем все неопределенные ссылки в этих объектных файлах и добавляем их [ссылки] к набору нужных идентификаторов. И так повторяем, пока набор не станет стабилен.
Второй шаг - определение порядка. Объектные файлы необходимо скомпоновать друг с другом таким образом, чтобы "задеть" как можно меньше страниц памяти. Вдобавок, ни одна функция не должна пересекать границу страницы. Сложность в том, что для лучшего расположения объектных файлов необходимо знать, что дальше будет делать компоновщик. Тут важно, что компоновщик помещает объектные файлы в исполняемый модуль (или DSO) в том же порядке, в каком они расположены во входных файлах (например, архивах) и в командной строке. Это дает программисту значительные возможности.
Для тех, кто готов потратить немного больше времени: были успешные попытки реорганизации, сделанные с помощью автоматического отслеживания запросов через перехватчики (hooks) __cyg_profile_func_enter и __cyg_profile_func_exit, которые вставляет gcc при запуске с параметром -finstrument-functions [oooreorder]. Подробную информацию об интерфейсах __cyg_* можно найти в руководстве к gcc. Используя трассировку программы, программист может более точно определить цепочки запросов. Результаты, достигнутые в [oooreorder] - снижение стоимости инициализации на 5%, и это достигнуто всего лишь перестановкой функций. Основная польза - снижение числа страничных ошибок, но и кэш TLB тоже играет роль, и немалую, учитывая, что в виртуальных средах промахи TLB обходятся гораздо дороже.
Комбинируя анализ вывода утилиты pagein с информацией о последовательности запросов, можно оптимизировать определенные этапы работы программы (инициализация тому примером), минимизируя число страничных ошибок.
Ядро Linux предоставляет два дополнительных механизма для избежания страничных ошибок. Первый - флаг для mmap, заставляющий ядро не просто модифицировать таблицу страниц, но, по сути, заранее загрузить все страницы в отображаемой области. Это достигается просто - к четвертому параметру вызова mmap добавляется флаг MAP_POPULATE. В результате вызов mmap обойдется значительно дороже, но, если все страницы, выделенные по данному запросу, будут использованы в ближайшее время, преимущества могут оказаться огромными. Вместо обработки множества страничных ошибок, каждая из которых обходится довольно дорого в связи с требованиями синхронизации и пр., программе придется обработать всего один, хоть и дорогой, вызов mmap. Обратная сторона медали, т.е. этого флага, проявляется в случаях, когда большая часть выделенных страниц не используется в ближайшее время после вызова (или не используется вообще). Выделенные, но не используемые страницы - просто пустая трата времени и памяти. Страницы, выделенные, но не использованные сразу (в ближайшее время) после вызова, тоже засоряют систему. Память выделяется еще до того, когда это действительно нужно, что теоретически может привести к нехватке свободного места. С другой стороны, в худшем случае страница просто будет использована для других целей (ведь она еще не была изменена), что не так уж дорого обходится системе - хотя, с учетом выделения, чего-то тоже стоит.
В целом, механизму MAP_POPULATE недостает избирательности. А вторая проблема: это лишь оптимизация; даже если выделены все-все страницы - не беда. Если система слишком занята для выполнения операции, предварительное выделение может быть отменено. А когда страница будет реально нужна, опять же произойдет страничная ошибка; ничего страшного - по крайней мере, не страшнее искусственного создания нехватки ресурсов. Альтернатива - применение POSIX_MADV_WILLNEED с функцией posix_madvise. Это подсказка операционной системе, что в ближайшем будущем программе понадобится страница, описанная в запросе. Ядро может как проигнорировать эту подсказку, так и заранее выделить страницы. Преимущество этого механизма в том, что он более избирателен. Предварительно загружены могут быть как отдельные страницы, так и диапазоны страниц в любом отображенном адресном пространстве. В случае отображенного в память файла, содержащего множество не используемых при выполнении данных, этот метод имеет огромное преимущество перед MAP_POPULATE.
Помимо этих активных подходов к минимизации количества страничных ошибок, также можно применить более пассивный подход, популярный среди разработчиков оборудования. Динамически разделяемый объект (DSO) занимает смежные страницы в адресном пространстве, часть из них содержит код, другая часть - данные. Чем меньше размер страницы, тем больше страниц необходимо для одного объекта DSO. А это, в свою очередь, увеличивает число страничных ошибок. Но важно отметить, что верно и обратное. Чем больше размер страницы, тем меньше их нужно для отображения; а следовательно, уменьшается и число страничных ошибок.
Большинством архитектур поддерживаются страницы размером в 4 Кб. На IA-64 и PPC64 популярен размер страниц в 64 Кб. Это значит, что минимальный объем выделяемой памяти составляет 64 Кб. Данное значение необходимо указывать при компиляции ядра, и его нельзя изменить динамически, во время работы. По крайней мере, пока нельзя. Интерфейсы ABI архитектур, поддерживающих несколько размеров страниц, позволяют запускать приложения с любым из поддерживаемых размеров. Среда выполнения сама сделает необходимые настройки, а корректно написанная программа ничего не заметит. Увеличенные размеры страниц означают больше потерь в результате того, что страницы используются лишь частично, но в некоторых ситуациях это вполне допустимо.
Большинство архитектур также поддерживают очень большие размеры, от 1 Мб и больше. Такие страницы иногда бывают полезны, но выделять всю память такими огромными кусками - бессмысленно. Слишком велики будут потери физической памяти. Но огромные страницы имеют свои преимущества: если используются не менее огромные наборы данных, то хранение их в страницах по 2 Мб на х86-64 потребует на 511 страничных ошибок меньше (в расчете на каждую большую страницу), чем применение страничек по 4 Кб. Это может в корне всё изменить. Решение: избирательно выделять память таким образом, чтобы использовались большие страницы именно для указанного диапазона адресов, а для остальных отображений того же процесса оставить обычные размеры страниц.
Использование больших страниц имеет свою цену. Поскольку области физической памяти, используемые для больших страниц, должны быть непрерывны, то спустя какое-то время отображение таких страниц может стать невозможным вследствие фрагментации памяти. Не доводите до такого. Люди работают над проблемами дефрагментации памяти и способами избежания фрагментации, но это очень сложно. Для больших страниц размером, скажем, 2 Мб, необходимо найти 512 последовательных страничек, а это сложно сделать практически всегда, за исключением одного периода: загрузки системы. Вот поэтому-то сегодня для использования больших страниц применяется специальная файловая система, hugetlbfs. Эта псевдо-файловая система резервируется по требованию системного администратора с помощью записи количества страниц, которое необходимо зарезервировать, в
/proc/sys/vm/nr_hugepages
Данная операция не будет выполнена, если не будет найдено достаточно свободных, последовательно расположенных областей памяти. Становится еще интересней, если используется виртуализация. Виртуальная система, созданная с использованием модели VMM, не имеет прямого доступа к физической памяти и потому не может сама выделить hugetlbfs. Ей приходится полагаться на менеджер VMM, и не факт, что данная функциональность вообще поддерживается. Что касается модели KVM, ядро Linux, на котором запущен модуль KVM, может выполнить монтирование hugetlbfs и передать подмножество страниц для выделения на одном из гостевых доменов.
В дальнейшем, когда программе потребуется страница большого размера, будет несколько вариантов:
- программа может использовать разделяемую память System V, применив флаг
SHM_HUGETLB. - файловая система
hugetlbfsможет быть полностью смонтирована и затем программа может создавать файл уже внутри, и использоватьmmapдля отображения одной (или более) страниц в качестве анонимной памяти.
В первом случае hugetlbfs не требует монтирования. Код, запрашивающий одну или более страниц, будет выглядеть примерно так:
key_t k = ftok("/some/key/file", 42);
int id = shmget(k, LENGTH, SHM_HUGETLB|IPC_CREAT|SHM_R|SHM_W);
void *a = shmat(id, NULL, 0);
Критичные моменты данной кодовой последовательности - применение флага SHM_HUGETLB и выбор верного значения LENGTH, которое должно быть кратно размеру больших страниц системы. Для разных архитектур используются разные значения. Использование интерфейса разделяемой памяти System V неудобно, ибо завязано на ключевом аргументе для различия (разделения) отображений. Интерфейс ftok может легко привести к конфликтам, и поэтому лучше - если возможно - использовать другие механизмы.
Если требование обязательного монтирования системы hugetlbfs - не проблема, то лучше использовать именно этот вариант заместо разделяемой памяти System V. На деле может возникнуть пара затруднений с использованием специальной файловой системы - во-первых, ядро должно поддерживать ее, и во-вторых, пока нет стандартизированной точки монтирования. Когда файловая система смонтирована, к примеру, в /dev/hugetlb, программа легко может ее использовать:
int fd = open("/dev/hugetlb/file1", O_RDWR|O_CREAT, 0700);
void *a = mmap(NULL, LENGTH, PROT_READ|PROT_WRITE, fd, 0);
Используя одно и то же имя файла в запросе open, разные процессы могут совместно использовать одни и те же большие страницы и взаимодействовать. Также есть возможность сделать страницы исполняемыми, для чего нужно установить флаг PROT_EXEC в запросе mmap. Как и в примере с разделяемой памятью System V, значение LENGTH должно быть кратно размеру больших страниц.
Аккуратно написанные программы (а такими должны быть все программы) могут определять точку монтирования во время выполнения, используя функцию вроде этой:
char *hugetlbfs_mntpoint(void) {
char *result = NULL;
FILE *fp = setmntent(_PATH_MOUNTED, "r");
if (fp != NULL) {
struct mntent *m;
while ((m = getmntent(fp)) != NULL)
if (strcmp(m->mnt_fsname, "hugetlbfs") == 0) {
result = strdup(m->mnt_dir);
break;
}
endmntent(fp);
}
return result;
}
Больше информации об этих двух случаях можно найти в файле hugetlbpage.txt, являющемся частью дерева исходников ядра. Этот файл также описывает особый подход, требуемый в случае IA-64.
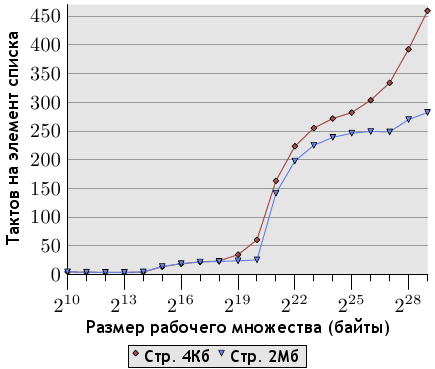
Рисунок 7.9: Выборка с применением больших страниц памяти, NPAD=0
Чтоб продемонстрировать преимущества больших страниц, на рисунке 7.9 показаны результаты выполнения теста случайной выборки при NPAD=0. Это те же данные, что показаны на рисунке 3.15, но в этот раз мы используем также страницы памяти большого размера. Как видно - преимущество в производительности может быть огромно. Для 220 байт использование больших страниц дало прирост производительност в 57%. Это связано с тем, что данный размер всё еще полностью умещается в одну страницу размером 2 Мб, и потому не происходит никаких промахов DTLB.
Далее прирост поначалу не столь высок, но с повышением размера рабочего множества снова увеличивается. Для рабочего множества в 512 Мб использование больших страниц дает прирост производительности в 38%. Кривая теста с использованием больших страниц выравнивается на отметке в 250 тактов. Когда рабочие множества достигают размеров более 227 байт, цифры снова значительно вырастают. Причина выравнивания в том, что буфер TLB в 64 элемента для страниц в 2 Мб покрывает 227 байт.
Как показывают цифры, большую часть потерь при использовании больших рабочих множеств составляют потери TLB. Использование интерфейсов, описанных в этом разделе, дает большой выигрыш. Скорее всего, данные этого графика соответствуют идеальному варианту, но даже реально работающие программы демонстрируют значительное увеличение в скорости. Среди программ, использующих сегодня страницы больших размеров, находятся базы данных, поскольку они работают с большими объемами данных.
На данный момент нет способов использования больших страниц для отображения данных, связанных с файлами. Есть заинтересованность в реализации данной возможности, но все сделанные пока что предложения подразумевают использование исключительно больших страниц с помощью файловой системы hugetlbfs. Это неприемлемо: использование больших страниц в данном случае должно быть прозрачным. Ядро может легко определять, какие отображения достаточно велики, и может автоматически использовать страницы большого размера. Проблема в том, что ядро не всегда в курсе важных нюансов. Если память, отображаемая большими страницами, в дальнейшем потребуется разделить на маленькие, по 4 Кб (например, в случае частичного изменения защиты с применением mprotect), то будет потеряно очень много драгоценных ресурсов, в частности, последовательных областей физической памяти. Так что можно быть уверенным: пройдет еще какое-то время, прежде чем такой подход будет успешно реализован.