Библиотека сайта rus-linux.net
LLVM
Глава 11 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: LLVM
Автор: Chris Lattner
Перевод: А.Панин
11.4. Реализация архитектуры трех фаз в LLVM
В компиляторе на основе LLVM система предварительной обработки кода осуществляет разбор, проверку и выявление ошибок в переданном коде, после чего преобразует разобранный код в представление LLVM IR (обычно, но не всегда путем формирования дерева стандартного синтаксического анализа (AST) и преобразования его в представление LLVM IR). Это представление может быть подвергнуто ряду операций по анализу и оптимизации для улучшения качества кода, после чего оно передается генератору кода для формирования машинного кода для необходимой архитектуры, как показано на Рисунке 11.3. Это достаточно линейная реализация архитектуры трех фаз, но простое объяснение демонстрирует всю мощь и гибкость, которой обладает архитектура LLVM благодаря использованию представления LLVM IR.
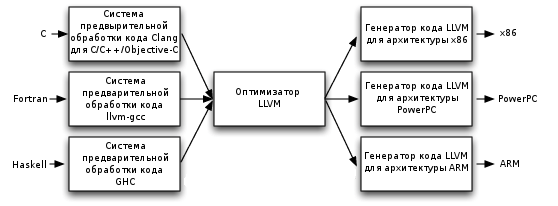
Рисунок 11.3: Реализация архитектуры трех фаз в LLVM
11.4.1 Представление LLVM IR является завершенным представлением кода
На самом деле представление LLVM IR является одновременно хорошо описанным и единственным интерфейсом для оптимизатора. Это означает, что все необходимые вам для разработки системы предварительной обработки кода знания заключаются в понимании устройства, принципов работы и используемых данных представления LLVM IR. Так как представление LLVM IR имеет текстовую форму, возможно и разумно создавать систему предварительной обработки кода, которая выводит представление LLVM IR в текстовой форме, после чего использует каналы Unix для передачи его выбранному оптимизатору и генератору кода.
Может показаться удивительным, но описанная выше возможность является оригинальной особенностью LLVM и одной из причин его успеха при работе в составе большого количества приложений. Даже очень успешный и обладающий относительно продуманной архитектурой компилятор GCC не имеет данной особенности: его промежуточное представление кода GIMPLE не является завершенным. В качестве простейшего примера следует упомянуть о том, что при генерации отладочной информации DWARF генератором кода из состава GCC, производится обход дерева исходного кода. Представление GIMPLE использует "кортежи" для обозначения операций в коде, но (по крайней мере в GCC 4.5) операнды все также обозначаются с помощью ссылок на дерево исходного кода.
В итоге разработчикам систем предварительной обработки кода необходимо обладать знаниями о том, как создается структуры дерева исходного кода GCC, а также о GIMPLE для их разработки. Генератор кода GCC обладает аналогичными недостатками, поэтому разработчикам приходится также разбираться в принципах его работы. Наконец, в GCC не предусмотрено возможности сохранения "завершенного представления кода" или способа чтения или записи представления GIMPLE (и соответствующих структур данных, формирующих представление кода) в текстовой форме. В результате эксперименты с GCC становятся относительно сложными, что ведет к уменьшению количества систем предварительной обработки кода.
11.4.2. LLVM является набором библиотек
Помимо представления LLVM IR, важным аспектом архитектуры LLVM является лежащий в его основе набор библиотек, а не монолитный компилятор с интерфейсом командной строки в случае GCC или сложная виртуальная машина в случае JVM или .NET. LLVM является инфраструктурой, набором полезных используемых в компиляторах технологий, которые могут быть использованы для решения специфических задач (таких, как включение компилятора языка C или оптимизатора в состав конвейера обработки спецэффектов). Эта возможность является одним из самых мощных и при этом плохо понимаемых архитектурных решений.
Давайте рассмотрим архитектуру оптимизатора, воспользовавшись примером: он читает представление LLVM IR, разделяет его на части, после чего генерирует представление LLVM IR, которое в теории может выполняться быстрее исходного. В LLVM (как и во многих других компиляторах) оптимизатор реализован в виде конвейера из разделенных фаз оптимизации, каждая из которых обрабатывает переданное представление и имеет возможность его модификации. Стандартными примерами оптимизаций являются: обработка inline-функций (при которой тела функций подставляются в места их вызовов), объединение выражений, оптимизация кода циклов, и.т.д. В зависимости от уровня оптимизаций выполняются различные фазы: например, при уровне -O0 (без оптимизаций) компилятор Clang не использует фазы вообще, а при уровне -O3 он использует серию из 67 фаз в ходе работы оптимизатора (в версии LLVM 2.8).
Алгоритм работы каждой фазы разрабатывается в виде отдельного класса C++, наследуемого (не напрямую) от класса Pass. Для большинства фаз используются отдельные файлы с расширением .cpp и их подкласс класса Pass объявляется в анонимном пространстве имен (что делает его полностью недоступным из файла объявления). Для того, чтобы было возможным использование фазы, у кода вне класса должна быть возможность использовать его, поэтому единственная функция (создания класса) экспортируется из файла. Немного упрощенный пример алгоритма фазы для пояснения представлен ниже6:
namespace {
class Hello : public FunctionPass {
public:
// Печать имен функций из представления LLVM IR, подвергающихся оптимизации.
virtual bool runOnFunction(Function &F) {
cerr << "Hello: " << F.getName() << "\n";
return false;
}
};
}
FunctionPass *createHelloPass() { return new Hello(); }
Как упоминалось ранее, оптимизатор LLVM позволяет использовать множество различных фаз, стили реализации алгоритмов каждой из которых идентичны. Эти алгоритмы компилируются в одни или несколько файлов с расширением .o, которые затем преобразуются в ряд статических библиотек (файлы с расширением .a в Unix-системах). Эти библиотеки предоставляют все виды функций для анализа и преобразования кода, а фазы по возможности объединяются: они могут использоваться отдельно или явно объявлять зависимости в том случае, если их работа зависит от результатов какого-либо анализа кода из другой фазы. При выполнении данной последовательности фаз система PassManager из состава LLVM использует явную информацию о зависимостях для удовлетворения этих зависимостей и оптимизации процесса выполнения фаз.
Библиотеки и абстрактные возможности замечательно проработаны, но они на самом деле не решают проблем. Интересно рассмотреть случай, когда кто-либо хочет создать инструмент, в котором возможно использование технологии компиляции, в частности, JIT-компилятор для языка обработки изображений. Разработчик этого JIT-компилятора сформулировал ряд условий: например, язык обработки изображений очень восприимчив к задержке при компиляции и имеет некоторые характерные свойства, поэтому необходимо произвести оптимизацию производительности.
Архитектура оптимизатора LLVM, основанная на библиотеках, позволяет нашему разработчику выбрать последовательность исполнения фаз, а также выбрать те фазы, которые необходимы в случае обработки изображений: если весь код находится в одной большой функции, нет смысла тратить время на обработку inline-функий. Если указатели используются крайне редко, не стоит беспокоиться об анализе ссылок и оптимизации использования памяти. Однако, несмотря на наши усилия, LLVM не сможет волшебным образом решить все задачи оптимизации! Так как система оптимизации разделена на модули и система PassManager не обладает информацией о внутренних алгоритмах фаз, у разработчика появляется возможность реализации своих собственных фаз оптимизации для данного языка, способных сгладить неточности работы оптимизатора LLVM в плане явных специфических для данного языка возможностей оптимизации. На Рисунке 11.4 показан простой пример нашей гипотетической системы обработки изображений XYZ:
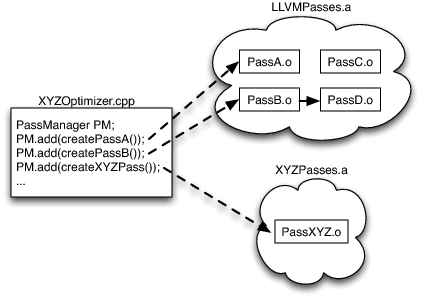
Рисунок 11.4: Гипотетическая система XYZ, использующая LLVM
Как только выбран набор оптимизаций (а также приняты подобные решения для генератора кода) компилятор для языка обработки изображений формируется в виде исполняемого файла или динамической библиотеки. Так как единственной ссылкой на алгоритм фазы оптимизации является простая функция create, объявляемая в каждом файле с расширением .o, а также оптимизаторы находятся в статических библиотеках с расширением .a, с приложением связывается код только тех фаз оптимизации, которые действительно используются, а не всех фаз оптимизации, доступных для LLVM. В нашем примере выше есть ссылки на код фаз PassA и PassB, поэтому они связываются с кодом приложения. Так как алгоритм фазы PassB использует алгоритм фазы PassD для проведения анализа, код фазы PassD также связывается с кодом приложения. Однако, так как фаза PassC (и множество других фаз оптимизации) не используется, код данной фазы не связывается с кодом приложения для обработки изображений.
В этой ситуации очевидна вся мощь архитектуры LLVM на основе библиотек. Это простое архитектурное решение позволяет LLVM предоставлять большое количество возможностей, некоторые из которых могут быть полезны только для определенного круга разработчиков, не лишая возможности использования библиотек тех, кому нужно выполнять только простейшие задачи. Напротив, в классических компиляторах оптимизаторы реализованы в виде тесно связанного кода большого объема, что осложняет его разделение на части, определение назначения его частей и ускорение его работы. В LLVM вы можете понять как работают отдельные оптимизаторы, не зная о том, как функционирует вся система.
Эта архитектура на основе библиотек также является причиной непонимания многими людьми принципов работы LLVM: библиотеки LLVM имеют множество возможностей, но они на самом деле ничего не делают сами по себе. Разработчик клиента для этих библиотек (например, компилятора языка C Clang) решает то, как они будут использоваться лучшим образом. Это тщательное разделение уровней, функций и внимание к разделению компонентов обуславливает возможность использования оптимизатора LLVM в таком широком диапазоне различных приложений для различных целей. Также тот факт, что LLVM позволяет использовать JIT-компиляию не говорит о том, что каждый клиент использует ее.
Сноски
- Для ознакомления с подробностями обратитесь к руководству "Writing an LLVM Pass manual" по адресу http://llvm.org/docs/WritingAnLLVMPass.html.
Далее: 11.5. Архитектура многоцелевого генератора кода LLVM