Библиотека сайта rus-linux.net
Ошибка базы данных: Table 'a111530_forumnew.rlf1_users' doesn't exist
Реализация механизма обработки регулярных выражений на языке C++
Оригинал: Pattern Matching with Regular Expressions in C++ Автор: Оливер Мюллер <ogmueller at t-online period de>Дата публикации оригинала: Апрель 1998 г.
Перевод: Владимир Царьков <bvbn at lipetsk period ru>
Дата перевода: 22.07.2010 г.
Copyright (c) 1998 by Oliver Muller. This material may be distributed only subject to the terms and conditions set forth in the Open Publication License, v1.0 or later (the latest version is presently available at http://www.opencontent.org/openpub/).
Регулярные выражения (РВ) позволяют реализовать очень гибкий механизм поиска по шаблону. Более 20 лет РВ использовались в многочисленных Unix программах, таких как grep, sed или awk. (Речь здесь может идти и о программах проекта GNU is Not Unix - http://gnu.org, которые на момент перевода имеют больше пользователей, чем оригинальные Unix программы. -- Прим. перев.) Данная статья расскажет читателю о том, как реализовать на C++ программу, которая будет осуществлять поиск текста на основе РВ.
Каждый, кто работал с Unix системой знает полезные РВ. Поиск с их помощью может быть осуществлён в программах grep, awk, emacs и это будет наиболее гибкий способ задания шаблонов для поиска текста. Каждый, кто хоть раз использовал grep, никогда не захочет потерять эту гибкость применения -- или кто-то всё-же хочет?
Необыкновенное удобство в использовании таких программ как grep -- результат обращения
к РВ. Если этот метод работы с шаблонами убрать из grep и заменить
его другим алгоритмом поиска, к примеру, алгоритмом Бойера--Мура, то в результате
получится игрушка, быстро работающая игрушка! (Знаете ли вы программу под
названием find для DOS, которая как раз является результатом замены такого рода...)
Но шутки в сторону. Поиск по шаблону с помощью РВ -- основа многих алгоритмов поиска в программах как для Unix, так и для Linux (GNU/Linux. -- Прим. перев.). Мощь этого метода поиска неоспорима.
Целью данной статьи является описание реализации механизма обработки РВ в виде класса на C++. Данная статья может быть вашим гидом по замечательному миру "поиска по шаблону" ("pattern matching").
Принципы
В первую очередь, рассмотрим несколько принципов поиска по шаблону с помощью РВ.
Для указания шаблона вы должны использовать форму записи, которую может обработать компьютер. Эта форма записи, или язык, в нашем случае -- синтаксис РВ.
- Квантификаторы (closure): строка одинаковых литералов, длина которой может меняться, либо литерал, появление которого не обязательно. (Одна из важнейших составляющих поиска по шаблону.)
- Конкатенация (concatenation): Если в шаблоне два литерала, идущих друг за другом, то и в тексте будет осуществлён поиск символов, идущих друг за другом.
- Объединение (конструкция выбора, alteration): Один из литералов, между которыми осуществляется выбор должен находиться в тексте, сравниваемом с шаблоном.
В дополнение к вышеперечисленному, использование скобок позволяет влиять на последовательность обработки элементов РВ.
- звёздочку (*), означающую повторение литерала нуль или более раз
- плюс (+), означающий повторение литерала один или более раз
- знак вопроса (?), означающий, что наличие того или иного литерала возможно, но не является обязательным условием совпадения шаблона с текстом
Примеры: A* совпадает с пустой строкой, "A", "AA", "AAA" и т. д., A+ совпадает с "A", "AA", "AAA" и т. д. A? совпадает с пустой строкой или "A".
Для задания конкатенации нет необходимости использовать метасимволы. Строка, содержащая идущие друг за другом символы, является конкатенацией. Регулярное выражение ABC, например, совпадёт со строкой "ABC".
Объединение (конструкция выбора, alteration) задаётся с помощью символа "|" между двумя РВ. A|B совпадает либо с "A", либо с "B".
В обработчиках расширенных РВ (Extended Regular Expressions) используются несколько дополнительных метасимволов для более эффективного задания сложных шаблонов. Но данная статья является не более, чем коротким введением в синтаксические возможности РВ и не включает рассмотрения этих метасимволов.
Автомат
Для поиска шаблона, заданного РВ, вы не можете сравнивать каждый символ шаблона с каждым символом текста. Квантификаторы и объединение вызывают к жизни такое количество путей срабатывания сложных шаблонов, что использование "обычного" алгоритма невозможно. Должен быть применен более действенный подход. Лучший путь -- построить автомат и смоделировать его работу. Для описания поискового шаблона, заданного регулярным выражением, вы можете использовать недетерминированный и детерминированный конечные автоматы.
Автомат может переходить в несколько состояний. Он может переходить из одного
состояния в другое, в зависимости от события, которое поступило ему на вход,
в нашем случае, -- очередной входной символ. Здесь же видна разница между
детерминированными и недетерминированными конечными автоматами. Детерминированный
автомат может принять только одно состояние в ответ на определённый символ,
а недетерминированный автомат может перейти в одно из нескольких
состояний в ответ на один и тот же входной символ.
Оба типа автоматов допустимо использовать для задания любого РВ. Каждый из этих типов автоматов имеет достоинства и недостатки. Для всех, кто хочет знать больше об этих автоматах в их связи с РВ, может быть рекомендована книга /1/. В нашей реализации мы будем использовать недетерминированный автомат. Это наиболее востребованная стратегия реализации алгоритма обработки РВ. Более того, сконструировать недетерминированный автомат по РВ несколько проще, чем детерминированный.
На Рисунке 1 показана диаграмма переходов недетерминированного конечного автомата для шаблона a*(cb|c*)d. Она содержит все типы операций над регулярными множествами: итерацию, конкатенацию, объединение. Заметьте, что скобка, содержащая объединение, является литералом для операции конкатенации. Начальное состояние представлено прямоугольником в левой части рисунка. Допускающее состояние автомата показано в правой части рисунка в виде прямоугольника, перечёркнутого по диагонали.
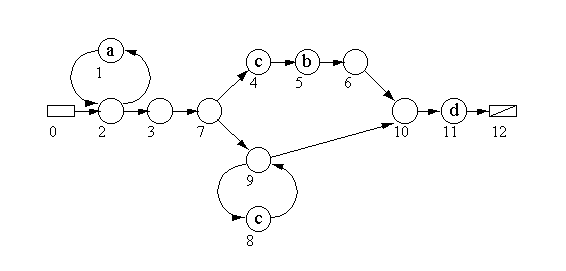
Рисунок 1. Недетерминированный конечный автомат для шаблона a*(cd|c*)d
Этот пример очень хорошо демонстрирует проблемы обработки шаблонов. В состоянии под номером 7 не ясно какое состояние будет следующим для входного символа "c". Состояния 4 и 9 -- возможные варианты. Автомат должен выбрать правильный путь.
Если на предмет совпадения с шаблоном
должна быть исследована строка, содержащая текст "aaccd",
автомат стартует из состояния номер 0 -- начального состояния.
Следующее состояние, номер 2, является нулевым. Иными словами,
для перехода автомата в это состояние не нужны символы, совпадающие
с шаблоном.
Первый символ на входе -- "a". Автомат переходит в состояние под номером 1, это единственный путь. После успешного совпадения части шаблона с символом "a" будет прочитан очередной символ и автомат снова перейдёт в состояние 2. Для следующего входного символа, тоже "a", крайние два перехода повторяются. После этого, единственный допустимый путь -- переход в состояние под номером 3 и 7.
Мы оказались в состоянии, которое может вызвать проблемы. Следующий символ на входе -- "c". Здесь мы видим силу автомата. Он может догадаться, что правильный путь будет через состояние номер 9, но не 4. Это -- душа недетерминированной стратегии: возможные решения находятся. Они не описываются алгоритмом, работающим "шаг за шагом".
Разумеется, в реальном мире программирования мы должны перебирать все возможные пути. Однако, о практической стороне дела поговорим несколько позже.
После достижения состояния под номером 9, автомат осуществляет переход из 9 в 8 (первое "c" на входе), в 9, в 8 (второе "c" на входе), 10 и 11 (совпадение с "d") в допускающее состояние под номером 12. Допускающее состояние достигнуто, следовательно, текст "aaccd" совпадает с шаблоном "a*(cb|c*)d".
Разработка
Механизм обработки РВ может быть разделен на две части: компилятор, генерирующий автомат по заданному шаблону и интерпретатор или эмулятор, имитирующий автомат и осуществляющий поиск по шаблону.
Сердцем компилятора является синтаксический анализатор (parser), основанный на следующей контекстно-свободной грамматике:
list ::= element | element "|" list
element ::= ( "(" list ")" | v ) ["*"] [element]
Эта EBNF диаграмма (=Extended Backus-Naur Form -- Расширенная форма Бакуса-Наура) описывает (сокращённую) грамматику РВ. В рамках данной статьи невозможно объяснить, что такое контекстно-свободная грамматика или, например, EBNF. Поэтому, если вы не знакомы с этими темами, рекомендую почитать /1/ и /3/, например. (Краткое, но ёмкое введение в систему обозначений EBNF на русском языке, может быть найдено в свободной энциклопедии Wikipedia. -- Прим. перев.)
В нашем примере механизма обработки РВ мы реализуем базовые операции
над регулярными множествами, в частности, | и *. Такие
квантификаторы как + и ? мы не будем применять. Но
с помощью Рисунка 2 вам не составит проблем самим их реализовать.
Все функции РВ будут инкапсулированы в класс объектов под названием
RegExpr. Этот класс будет содержать компилятор и интерпретатор/эмулятор.
Пользователю будут предоставлены только два конструктора, один перегруженный оператор и четыре
метода для компиляции, поиска и обработки ошибок.
Шаблон может быть задан через вызов конструктора RegExpr(const char *pattern),
через использование оператора присваивания = или метода compile(const char *pattern).
Если re является объектом RegExpr, следующие строки зададут шаблон "a*(cb|c*)d":
RegExpr re("a*(cb|c*)d");
или RegExpr re; re = "a*(cb|c*)d";
или RegExpr re; re.compile("a*(cb|c*)d");
Для поиска в текcте предлагается использовать
методы search() и searchLen(). Разница между ними в том, что
searchLen() ожидает, как дополнительный параметр, ссылку на переменную
типа unsigned integer. В этой переменной возвращается длина совпавшей с
шаблоном подстроки. Обратите внимание, что при использовании квантификаторов
и конструкции выбора, длина найденной подстроки может изменяться, например,
a* совпадает с "", "a", "aa" и т. д.
В таких программах как grep вам не потребуется такая дополнительная информация.
Здесь можно использовать search() вместо searchLen(). Этот
метод обрабатывает входную последовательность, вызывая searchLen()
с "фиктивной" переменной.
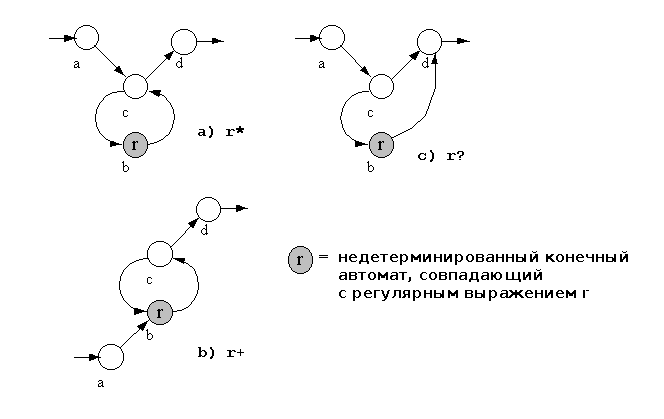
Рисунок 2. Автоматы, реализующие поведение квантификаторов
Обработка ошибок полностью основана на обработке исключений. В случае, если
компилятор обнаруживает синтаксическую ошибку в обрабатываемом РВ,
он выдаст ошибку типа xsyntax. Вы можете поймать это исключение в вашей программе
и вызвать метод getErrorPos(), возвращающий
позицию символа, при обработке которого произошла ошибка. Это может выглядеть следующим
образом:
try {
re.compile("a*(cb|c*)d");
} catch(xsyntax &X) {
cout < "error near character position "
<
X.getErrorPos() < endl;
}
Другая ошибка, которая может произойти -- нехватка памяти. Такая ошибка --
вызванная использованием очередного метасимвола (caused by the new operator) --
обрабатывается различными компиляторами C++ неодинаково. gcc, к примеру,
реагирует на такую ошибку, завершая работу. Некоторые компиляторы
генерируют исключения. Другие вовсе ничего не делают и ожидают
пока появятся дополнительные ошибки, которых не приходится долго ждать
в рассматриваемом случае. Обычно, в каждом ANSI C++ компиляторе,
данная проблема решается использованием функции set_new_errorhandler()
(объявлена в new.h) для установки режима обработки ошибки.
В большинстве случаев я пишу маленькую подпрограмму для генерации исключения,
с указанием типа ошибки, и использую данную подпрограмму
в качестве обработчика очередного метасимвола. Это, между
прочим, -- простое решение при программировании переносимого
обработчика ошибок, которого можно использовать вместе со всеми
ANSI C++ компиляторами и с любой операционной системой.
Для удаления экземпляра объекта RegExpr
при возникновении ошибки и генерации исключения, в RegExpr
содержится метод под названием clear_after_error().
Вызов данного метода важен, так как ошибка оставляет компилятор и
эмулятор (части механизма обработки регулярного выражения -- Прим. перев.)
в неопределённом состоянии, которое может вызвать фатальные ошибки при
вызове других методов.
Компилятор
Грамматика, описанная ранее средствами EBNF, реализуется в методах
list, element и v. list и element
представляют правила вывода в EBNF. v -- это метод, реализующий
специальный символ v. В рамках грамматики этот символ не является
метасимволом (|, *, и т. д.). Также это может быть
последовательность, экранированная обратной косой чертой, например, \с,
где c любой символ. Обратная косая черта отменяет особое значение
метасимвола.
Эти три метода обрабатывают массив с именем automaton. Массив состоит
из struct переменных, содержащих информацию о состояниях автомата.
Каждое состояние содержит индексы следующего состояния(ний) и символ, который
должен совпасть. Для состояния номер 0 эта информация будет нулевым байтом ("\0").

Рисунок 3. Дерево разбора для "a*|b"
Мы реализуем разбор сверху-вниз (top-down parser).
Используется рекурсивный спуск --
каждое правило вывода программируется как функция.
Синтаксический анализатор разбивает шаблон на
части до тех пор пока не будет достигнут заключительный
символ. На Рисунке 3 показано дерево разбора для "a*|b".
Сначала входим в list, ветвящийся на незаключительный (non-terminate)
element, терминальный символ "|", а также незаключительный,
list. element обнаруживает v и "*"
и спускается к "a". Другая часть
list спускается прямо к "b", проходя через element и v.
Дерево разбора для рассмотренного ранее примера РВ
отображено на Рисунке 4.
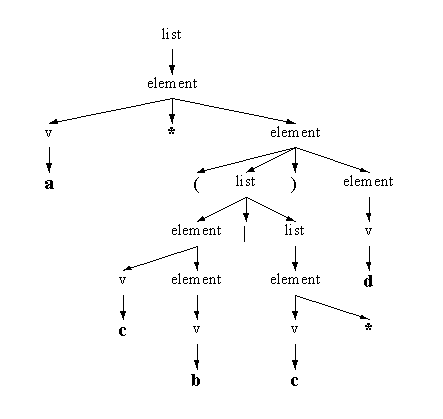
Рисунок 4. Дерево разбора для "a*(cb|c*)d"
Каждый незаключительный символ представляет вызов функции в нашем анализаторе. Рекурсивный спуск -- наиболее простой путь реализации анализатора из контекстно-свободной грамматики, в частности, EBNF диаграммы. Самое главное -- не допустить ошибок при задании грамматики!
Внутри обсуждавшихся выше методов генерируются состояния автомата. Для каждого символа регулярного выражения будет создано состояние. Единственное исключение -- метасимвол "|", который компилируется в два состояния.
В ответ на вызов методы всегда возвращают входную точку для сгенерированной части автомата (индекс состояния). Часть автомата всегда завершается крайним текущим состоянием, индекс которого хранится в свойствах RegExpr. На Рисунке 5 показаны несколько частей автоматов (part automata).
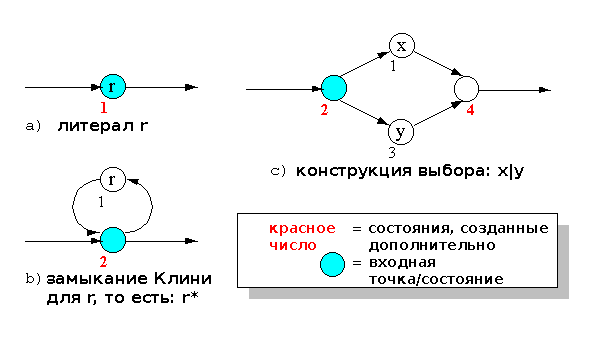
Рисунок 5. Примеры частей автомата
Числа, выделенные красным шрифтом, обозначают состояния сгенерированные для выполнения той или иной операции над регулярными множествами. Последовательность чисел определяется анализатором, который читает строку слева направо. Возвращаемое входное значение также выделено. Теперь понятно почему очень важно сообщать вызывающей функции точку входа: она не всегда имеет наименьший индекс!
Состояния, да и весь автомат, генерируются шаг за шагом обозначенным выше образом. Вероятно, не имеет смысла больше описывать то, как создаётся автомат. Вам лучше обратиться к исходникам, откомпилировать их и проследить за работой алгоритма через отладчик.
Небольшое пояснение к автомату. Он реализуется через статический массив в RegExpr. Разумеется, такая реализация очень недоразвита. В серьёзной программе необходимо использовать стратегию получше, например, в RegExpr организовать класс, работающий с динамическим массивом.
Имейте в виду, что предлагаемая простая реализация автомата может вызвать фатальные ошибки при использовании слишком длинного шаблона! Нами не создавалась функция, которая управляет процессом компиляции шаблона при нехватке состояний.
Впрочем, не сложно реализовать автомат как класс, управляющий процессом компиляции шаблона через динамический массив или связный список.
Имитация работы автомата
После компиляции шаблона мы можем запустить на исполнение сгенерированный код
и, таким образом, имитировать работу автомата.
Алгоритм поиска реализуется в методе simulate().
Ранее уже отмечалось, что автомат выбирает правильный ответ, но это с теоретической точки зрения. Компьютерная имитация недетерминированного конечного автомата должна включать испытание каждого возможного прохода через этот автомат. Седжвик (/3/) реализовал интересный алгоритм для решения этой задачи. Наш алгоритм будет основываться на этом подходе.
Система Седжвика имеет ряд недостатков при практическом применении. Во-первых, её грамматика нуждается в наличии символа (character) после квантификатора, иначе она не может его найти. Но эта проблема быстро решается написанием заплатки к программе -- и наша реализация уже содержит исправленный код. Вторая проблема несколько более сложна. Реализация Седжвика завершает работу после первого совпадения. Это значит, что поиск самой длинной, удовлетворяющей шаблону, строки не производится. К примеру, если вы ищите "a*a" в "xxaaaaaxx", будет найдена только "a" вместо "aaaaa". В нашей реализации будет исправлен и этот недостаток.
Идея о том, что программа может угадать правильный путь звучит невероятно. Основа такого программного обеспечения заключается в проверке всех возможных путей, за исключением крайнего, верно совпадающего. Параллельное выполнение имеет здесь решающее значение.
Каждый переход автомата будет протестирован и, в случае несовпадения с шаблоном, удалён. Это несколько "усложнённый" путь. Каждый возможный переход тестируется одновременно с другими и удаляется при несовпадении с символом, обрабатываемым в текущий момент поиска по тексту.
Базовой для данного алгоритма является очередь с двусторонним доступом (deque, double-ended queue). Это гибрид между стэком и буфером. С такой структурой данных можно не только взаимодействовать через команды push и pop (по принципу Last In First Out), но и средствами команды put. Иными словами, данные в эту структуру могут добавляться не только сверху, но и снизу.
- верхняя часть для символа, обрабатываемого в данный момент при поиске в тексте
- нижняя часть для следующего символа
Следующие значения нулевых состояний (см. раздел Автомат. -- Прим. перев.) хранятся в верхней части очереди, так как реализуется структура, необходимая для выявления совпадения с текущим символом. Последующие значения ненулевых состояний (the_char != '\0') размещаются в нижней части очереди, указывая на последующий символ. Также хранится специальное значение next_char(-1), указывающее на то, что будет обработан следующий символ из текста.
Основной цикл, в процессе имитации работы автомата, получает значение состояния из очереди и проверяет условия. Если символ в the_char совпадает с проверяемым на данный момент символом из текста, индексы следующих состояний (next1 и next2) будут помещены в конец очереди. Если прочитанное состояние -- нулевое, следующие индексы будут размещены в начало очереди. Если состояние равно next_char(-1), будет обработан следующий символ в исследуемом тексте. В таком случае, next_char размещается в конце очереди.
Цикл будет завершён если достигнут конец текста или очередь пуста. Очередь пуста при отсутствии каких-либо непроверенных частей шаблона.
До сего момента, описание похоже на предлагаемый Седжвиком подход, однако, разница в том, что когда состояние становится нулевым, цикл не завершится. Будет найдено и сохранено совпадение, но цикл продолжит выполнение! Поиск возможных совпадений будет производится до конца.
После завершения цикла возвращается крайнее совпадение. Если же совпадений с шаблоном не найдено, -- позиция, с которой начинается поиск, минус один.
Небольшой пример
Исходный код может быть скачан отсюда.
eg.cc -- маленькое подобие egrep. Оно призвано продемонстрировать возможности применения RegExpr. eg читает из стандартного входа или из файла, указанного опционально, и печатает каждую строку, совпадающую с шаблоном.
Применение: eg шаблон [имя_файла]
- Обработка квантификаторов ? и +
- Реализация автомата как объекта с динамическим массивом или связным списком, управляющим состояниями
- Символьные классы [...]
- Метасимвол . для обозначения любого символа
- Другие метасимволы из тех, что известны по sed или ed {...}
- Метасимволы, указывающие на начало и конец строки (^ и $).
Надеюсь, вам понравится разбираться с предлагаемым примером реализации обработчика регулярных выражений. Если у вас есть какие-либо предложения, вопросы или идеи, пожалуйста, дайте мне знать.
Источники
- Aho, Alfred V. / Sethi, Ravi / Ullman, Jeffrey D.: COMPILERS Principles, Techniques and Tools. Reading (Mass.): Addison Wesley 1986
- Muller, Oliver: Mustererkennung mit Delphi-Suchen und Ersetzen von regulaeren Ausdruecken. mc extra (DOS International) 7/96
- Sedgewick, Robert: Algorithms. Reading (Mass.): Addison Wesley 2nd Ed. 1992
Рекомендуемая литература
- Серебряков В. А., Галочкин М. П., Гончар Д. Р., Фуругян М. Г. Теория и реализация языков программирования: Учебное пособие. М.: МЗ-Пресс, 2003. 345 с.
- Фридл Дж. Регулярные выражения. Библиотека программиста. СПб.: Питер, 2001. 352 с.
- Царьков В. Б. Теория и методика построения регулярных выражений. Проблема самообразования. 2010. URL: http://lipetsk.lug.ru/projects/index.html#re (дата обращения 20.07.2010).
- Cox R. Implementing Regular Expressions. 2007. URL: http://swtch.com/~rsc/regexp/ (дата обращения 20.07.2010).
Если ваша фирма не обладает штатом квалифицированных программистов, вы можете прибегнуть к услугам IT аутсорсинга. На сегодняшний день IT аутсорсинг одно из самых эффективных средств обеспечения бизнес-процессов на Вашем предприятии. Во-первых, аутсорсинг позволяет снизить расходы на содержание штата технических сотрудников и устранить проблему поиска квалифицированных кадров. А во-вторых, вместо нескольких человек Вы получаете целую команду высококлассных специалистов, готовых качественно и быстро решить любые Ваши задачи, независимо от направленности и сложности.