Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 5.
Оригинал: What every programmer should know about memory. Memory part 5: What programmers can do.
Автор: Ulrich Drepper
Дата публикации: 23.10.2007
Перевод: Капустин С.В.
Дата перевода: 30.10.2009
6. Что могут делать программисты - оптимизация кэша
6.2 Доступ к кэшу
6.2.2 Оптимизация доступа к кэшу инструкций уровня 1
Для подготовки кода для правильного использования L1i необходимы приемы, похожие на те, что применяются при правильном использовании L1d. Проблема однако в том, что программист обычно не может прямо влиять на то, как используется L1i, если он не пишет код на ассемблере. Если используется компилятор, то программист может задать механизм использования L1i не напрямую, а руководя компилятором в составлении наилучшего устройства кода.
Код имеет то преимущество, что между переходами он линеен. В такие периоды процессор может эффективно делать предварительную загрузку памяти. Переходы нарушают эту идеальную картину из-за того что
- цель перехода может быть определена не статически;
- даже если она определена статически, загрузка памяти может занять длительное время, если эта цель
отсутствует во всех кэшах.
Эти проблемы создают задержки при выполнении кода с возможным существенным снижением производительности. Вот почему современные процессоры плотно завязаны на предсказание ветвления (BP - branch prediction). Высокоспециализированные модули BP пытаются определить цель перехода настолько задолго до самого перехода, насколько возможно, так что процессор смог бы инициировать загрузку инструкций с нового места в кэш. Они используют статические и динамические правила и все лучше и лучше распознают шаблоны при исполнении кода.
Для кэша инструкций получить данные так скоро, как это возможно, еще более важно. Как упоминалось в разделе 3.1, инструкции должны быть декодированы, прежде чем они будут исполнены и, чтобы ускорить это (важно для x86 и x86-64), инструкции кэшируются в декодированной форме, а не в форме байт/слово, читаемой из памяти.
Чтобы достичь наилучшего использования L1i, программисты должны стремиться, по крайней мере, к следующим аспектам генерации кода:
- нужно уменьшать насколько возможно размер кода. Это должно быть сбалансировано с такими оптимизациями как развертывание цикла и использование встроенных функций
- исполнение кода должно быть линейным, без пузырей. {Пузырями называются дыры в конвейере процессора, которые появляются, когда процессор ожидает ресурсы. Подробности читатель может найти в литературе по дизайну процессоров.}
- нужно выравнивать код, когда это имеет смысл.
Теперь посмотрим на некоторые методы компиляторов, способные оптимизировать программы в соответствии с этими аспектами.
У компиляторов есть опции по установке уровней оптимизации, некоторые специфические оптимизации могут быть заданы отдельно. Много оптимизаций, установленных на высоких уровнях оптимизации (-O2 и -O3 для gcc), имеют дело с оптимизацией циклов и встраиванием функций. В общем, это хорошие оптимизации. Если код, оптимизированный таким образом, отвечает за значительную часть общего времени исполнения программы, общая производительность будет улучшена. Встраивание функций, в частности, позволяет компилятору оптимизировать за раз более крупные куски кода, что, в свою очередь, приводит к генерации машинного кода, который лучше использует конвейерную архитектуру процессора. Работа над кодом и данными (через dead code elimination или value range propagation и др.) идет лучше, когда более крупные части программы могут рассматриваться как единый модуль.
Более крупный размер кода означает большую нагрузку на кэши L1i (и также L2 и более высокие уровни). Это может ухудшать производительность. Маленький код может быть быстрее. К счастью gcc имеет связанную с этим опцию оптимизации. Если используется -Os, то компилятор оптимизирует размер кода. Те оптимизации, которые могут увеличить размер кода, отключаются. Использование этой опции часто приводит к неожиданным результатам. Эта опция может дать большой выигрыш, особенно если компилятор в действительности не может извлечь выгоды из развертывания циклов и использования встроенных функций.
Использованием встроенных функций можно также управлять индивидуально. У компилятора есть ограничения и эвристика, которые управляют использованием встроенных функций. Программист может управлять этими ограничениями. Опция -finline-limit определяет, насколько велика должна быть функция, чтобы считаться слишком большой для встраивания. Если функция вызывается из нескольких мест, то встраивание её во все эти места приведет к взрывному росту размера кода. И больше того. Предположим, что функция inlcand вызывается в двух функциях f1 и f2. Функции f1 и f2 сами вызываются последовательно
Со встраиванием Без встраивания Таблица 6.3: Со встраиванием и без
Таблица 6.3 показывает как может выглядеть сгенерированный код в случаях встраивания и отсутствия встраивания в обеих функциях. Если функция inlcand встроена и в f1 и в f2, то общий размер сгенерированного кода:
размерf1+ размерf2+ 2 × размерinlcand
Без встраивания общий размер меньше на размер inlcand. Вот настолько нужно больше кэша L1i и L2, если f1 и f2 вызываются одна за другой через небольшой промежуток времени. Плюс, если inlcand не встроена, то её код может быть все ещё в L1i и её не нужно будет снова декодировать. Плюс модуль предсказания ветвлений может работать лучше при предсказании переходов, так как он уже видел этот код. Если в компиляторе значение по умолчанию для верхнего предела размера встраиваемых функций не лучшее для программы, то его необходимо понизить.
Есть случаи, однако, когда встраивание всегда имеет смысл. Если функция вызывается один только раз, то её можно встроить. Это дает возможность компилятору выполнить другие оптимизации (такие как value range propagation, которая может значительно улучшить код). Такое встраивание может быть нарушено заданными ограничениями. В gcc для таких случаев имеется опция, позволяющая определить, что функция всегда встраивается. Добавление атрибута always_inline к функции заставляет компилятор всегда её встраивать.
В том же контексте, если функция никогда не должна быть встроена, несмотря на то, что она достаточно мала, можно использовать атрибут noinline. Использование этого атрибура имеет смысл даже для маленьких функций, если они вызываются часто и из разных мест. Если можно повторно использовать содержимое L1i и общий размер кода снижен, это часто оправдывает затраты на дополнительный вызов функции. Современное предсказание ветвления работает очень хорошо. Если встраивание может привести к более агрессивным оптимизациям, то все выглядит по-другому. Это то, что нужно решать в каждом конкретном случае.
Атрибут always_inline работает хорошо, если встраиваемый код всегда используется. А что если нет? Что если встраиваемая функция используется изредка?
void fct(void) {
... code block A ...
if (condition)
inlfct()
... code block C ...
}
Код, сгенерированный для такого кода, в целом совпадет со структурой источника. Это значит, что сначала будет блок A, затем условный переход, который, если условие будет вычислено как ложь, приведет к скачку вперед. Затем идет код, сгенерированный для встроенной функции inlfct и, в конце, блок кода C. Это все выглядит разумно, но есть проблема.
Если condition часто принимает значение ложь, то выполнение не будет линейным. Будет большой кусок неиспользуемого кода в центре, который не только загрязняет L1i из-за предварительной выборки, но и может вызвать проблемы с предсказанием ветвлений. Если предсказание ветвления неверно, то условный переход может быть очень неэффективным.
Это общая проблема, не специфическая только для встраиваемых функций. Всегда, когда есть однобокое условное выполнение (то есть когда выражение в условном переходе намного чаще выдает один результат, чем другой), есть потенциальная опасность неверного статического предсказания ветвления и, следовательно пузырей в конвейере. Это может быть предотвращено указанием компилятору передвинуть реже используемый код подальше от основного пути кода. В этом случае условная ветвь, сгенерированная для конструкции if, перескочит в другое место, так как показано на картинке.
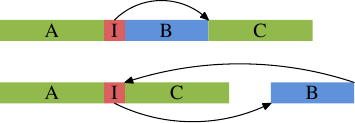
Верхняя часть представляет собой простой план кода. Если часть B, то есть часть, сгенерированная для встраиваемой функции inlfct, часто пропускается при выполнении потому, что условие I перепрыгивает через него, то предварительная выборка процессором будет помещать в кэш строки, содержащие блок B, который редко используется. Используя перестановку блоков, можно изменить это и получить результат из нижней части картинки. Часто исполняемый код линеен в памяти, а редко исполняемый передвинут туда, где он не помешает предварительной выборке и эффективности L1i.
GCC предоставляет два метода, чтобы добиться этого. Во-первых, компилятор может учесть выводы программы сбора информации о выполнении при перекомпиляции кода и переставить блоки кода с учетом этого. Мы увидим как это работает в разделе 7. Второй метод использует явное предсказание ветвей. Gcc использует __builtin_expect:
long __builtin_expect(long EXP, long C);
Эта конструкция говорит компилятору о том, что выражение EXP скорее всего примет значение C. Возвращаемым значением будет EXP. Предполагается, что __builtin_expect будет использоваться с условным выражением. Почти всегда это будет выражение с булевым значением, поэтому удобно определить два вспомогательных макроса:
#define unlikely(expr) __builtin_expect(!!(expr), 0) #define likely(expr) __builtin_expect(!!(expr), 1)
Эти макросы можно использовать так:
if (likely(a > 1))
Если программист использует эти макросы и потом использует опцию оптимизации -freorder-blocks, gcc переупорядочит блоки как на картинке выше. Эта опция включена для -O2, но выключена для -Os. Есть еще одна опция для перестановки блоков (-freorder-blocks-and-partition), но она имеет ограниченное применение, так как не работает с обработкой исключений.
Есть еще одно большое преимущество маленьких циклов, по крайней мере на некоторых процессорах. Интерфейс Intel Core 2 имеет специальное свойство, называемое Детектор Потока Цикла (Loop Stream Detector - LSD). Если цикл состоит не более чем из 18 инструкций (ни одна из которых не является вызовом подпрограммы), требует не более 4 вызовов декодера по 16 байт, имеет не более 4 инструкций ветвления и выполняется более 64 раз, то такой цикл иногда закрепляется в очереди инструкций и, следовательно, быстрее доступен при следующем использовании. Это применимо, например, к маленьким внутренним циклам, которые запускаются много раз через внешний цикл. И даже без такого специального железа компактные циклы имеют преимущества.
Встраивание - не единственный аспект оптимизации по отношению к L1i. Другой аспект - это выравнивание, так же как и для данных. Есть очевидные отличия: код является по большей части линейным двоичным объектом, который нельзя произвольным образом разместить в памяти и на который программист не влияет непосредственно, из-за того, что он генерируется компилятором. Есть, однако, некоторые аспекты, на которые программист может влиять.
Не имеет никакого смысла выравнивать каждую отдельную инструкцию. Цель состоит в том, чтобы поток инструкций был последовательным. Поэтому выравнивание имеет смысл только в стратегических местах. Чтобы решить, куда добавлять выравнивания, нужно понимать в чем могут состоять преимущества. Нахождение инструкции в начале строки кэша {Для некоторых процессоров строка кэша не совпадает с атомарными блоками инструкций. Интерфейс Intel Core 2 передает декодеру 16-байтные блоки. Они выравнены и поэтому не могут выйти за границы строк кэша. Выравнивание по началу строки кэша имеет однако преимущества, так как оптимизирует позитивный эффект предварительной выборки.} означает, что предварительная выборка строки кэша максимизирована. Для инструкций это также означает, что декодер более эффективен. Легко видеть, что если инструкция выполняется в конце строки кэша, то процессор должен подготовиться прочесть следующую строку кэша и декодировать инструкции. Но есть вещи, которые могут пойти неправильно (такие как промахи кэша), что означает, что в среднем инструкции в конце строки кэша выполняются не так эффективно, как в начале.
Соедините это с тем, что проблема может быть еще серьезнее, если управление только что было перенесено к рассматриваемой инструкции (и, следовательно, предварительная выборка неэффективна) и мы придем к окончательному заключению о том, где выравнивание наиболее полезно:
- в начале функций;
- в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код;
- до некоторой степени в начале циклов.
В первых двух случаях выравнивание происходит с небольшими затратами. Выполнение кода продолжается с нового места, и если мы разместим его в начале строки кэша, то мы оптимизируем предварительную выборку и декодирование. {Для декодирования инструкций процессоры часто используют меньший чем размер строки кэша блок, 16-байтный в случае x86 и x86-64.} Компилятор выполняет выравнивание, вставляя где нужно инструкции no-op, чтобы заполнить пустые места, созданные выравниванием. Этот ⌠мертвый код■ занимает немного места и обычно не влияет на производительность.
Третий случай немного отличается: выравнивание начала каждого прохода цикла может создать проблемы для производительности. Проблема в том, что к началу цикла программа часто подходит последовательно. При неудачных обстоятельствах выравнивание начала цикла приведет к появлению пустоты между началом цикла и предыдущей инструкцией. В отличие от первых двух случаев, эта пустота не может быть мертвым кодом. После предыдущей инструкции должна исполняться первая инструкция цикла. Это означает, что после предыдущей инструкции нужно вставить или несколько инструкций no-op, или бузусловный переход к первой инструкции цикла. Ни то, ни другое не бесплатно. Если цикл выполняется немного раз, то эти инструкции no-op или безусловный переход могут стоить больше, чем выигрыш от выравнивания цикла.
Есть три способа, с помощью которых программист может влиять на выравнивание кода. Очевидно, что если код написан на ассемблере, то функция и все инструкции могут быть явным образом выравнены. Для этого ассемблер предоставляет для всех архитектур директиву .align. Для языков высокого уровня нужно сообщать компилятору о требованиях выравнивания. В отличие от типов данных и переменных, это невозможно сделать в исходном коде. Вместо этого используется опция компиляции:
-falign-functions=N
Эта опция заставляет компилятор выравнивать все функции по ближайшей большей N степени двойки. Это означает, что появляется дыра размером до N байт. Для маленьких функций использование большого значения N будет расточительством. Равно как и для кода, который выполняется редко. Последнее может часто происходить в библиотеках, которые могут содержать как популярные, так и не очень популярные интерфейсы. Мудрый выбор этой опции может ускорить выполнение или сохранить память избегая выравнивания. Все выравнивание может быть отключено используя единицу в качестве значения N или используя опцию -fno-align-functions.
Выравнивание для второго случая, упомянутого выше — в начале блоков, которые могут быть достигнуты только перескакиванием через предыдущий код — может контролироваться другой опцией
-falign-jumps=N
Все остальные детали эквивалентны, применимо то же предупреждение о ненужном расходе памяти.
Третий случай также имеет свою опцию:
-falign-loops=N
И снова применимы те же детали и предупреждения. Исключая то, что, как объяснялось выше, выравнивание отрицательно влияет на выполнение, так как либо инструкции no-op, либо бузусловный переход должны быть выполнены, если выравниваемый адрес достигается последовательно.
У gcc есть ещё одна опция для контроля над выравниванием, которую упомянем только для полноты. Опция -falign-labels выравнивает каждый ярлык в коде (в основном начало каждого блока). Это всегда, кроме редких исключений, замедляет код и, следовательно, не должно использоваться.
| Назад | Оглавление | Вперед |