Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти
Оригинал: What every programmer should know about memoryАвтор: Ulrich Drepper
Дата публикации: 21.09.2007
Перевод: Капустин С.В.
Дата перевода: 25.03.2009
2 Современное массовое аппаратное обеспечение
Понимание устройства массового аппаратного обеспечения важно потому, что специализированное аппаратное обеспечение теряет свои позиции. Увеличение масштаба сейчас чаще достигается за счет горизонтального масштабирования, а не за счет вертикального. То есть сегодня проще использовать много небольших, соединенных вместе массовых компьютеров, чем несколько действительно больших очень быстрых (и дорогих) систем. Это так из-за того, что широко доступно недорогое и быстрое сетевое аппаратное обеспечение. Есть все ещё ситуации, когда применяются большие специализированные системы, и они все ещё предоставляют возможности для бизнеса, но в целом рынок почти целиком состоит из массового аппаратного обеспечения. На 2007 год Red Hat ожидает, что в будущем "стандартными строительными блоками" для большинства центров обработки данных будут компьютеры с числом процессоров до четырех, в каждом процессоре по четыре ядра, которые, в случае процессоров Intel будут использовать технологию гиперпоточности. {Гиперпоточность позволяет двум и более программам использовать одно ядро процессора с небольшим количеством дополнительного оборудования.} Это означает, что стандартная система в центре обработки данных будет иметь до 64 виртуальных процессоров. Машины большего размера будут поддерживаться, но четырехпроцессорные четырехъядерные системы представляются наиболее предпочтительными, и основная оптимизация будет направлена на эти машины.
В структуре массовых компьютеров существуют большие различия. Мы охватим более 90% таких компьютеров, концентрируясь на наиболее важных различиях. Имейте в виду, что технические детали меняются быстро, так что читатель должен принимать во внимание дату этой статьи.
Многие годы персональные компьютеры и небольшие серверы были построены на чипсете, состоящем из двух частей: Северный мост (Northbridge) и Южный мост (Southbridge). Рисунок 2.1 показывает эту структуру.
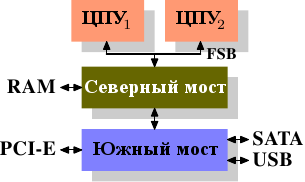
Рисунок 2.1: Структура с Северным и Южным мостом
Все ЦПУ (два в предыдущем примере, но может быть больше) соединены через системную шину (Front Side Bus, FSB) с Северным мостом. Северный мост содержит, кроме всего прочего, контроллер памяти, и его устройство определяет тип чипов RAM, используемых компьютером. Различные типы RAM, такие как DRAM, Rambus, и SDRAM, требуют различные контроллеры памяти.
Чтобы соединиться с другими системными устройствами Северный мост должен обмениваться данными с Южным мостом. Южный мост, часто именуемый мост ввода/вывода обменивается с устройствами через множество различных шин. Сегодня важное значение имеют шины PCI, PCI Express, SATA и USB, но также Южным мостом поддерживаются PATA, IEEE 1394, последовательные и параллельные порты. Более старые системы имеют слоты AGP, присоединенные к Северному мосту. Это делалось из соображений производительности и было связано с недостаточной скоростью обмена данными между Северным и Южным мостом. Однако сегодня слоты PCI-E присоединены к Южному мосту.
Из такой структуры системы вытекает несколько важных следствий:
- Все данные, которыми обмениваются ЦПУ друг с другом идут по той же шине, что используется для обмена данными с Северным мостом.
- Весь обмен данными с RAM проходит через Северный мост.
- У RAM имеется только один порт.
{Мы не обсуждаем многопортовую RAM в этом документе, так как она не применяется в персональных компьютерах, по крайней мере там, где программист имеет к ней доступ. Её можно найти в специализированнам аппаратном обеспечении, таком как сетевые маршрутизаторы, где очень важна скорость.}
- Обмен данными между ЦПУ и устройствами, присоединенными к Южному мосту, идет через Северный мост.
В этом дизайне можно сразу увидеть пару "бутылочных горлышек". Одно такое "бутылочное горлышко" возникает при доступе устройств к RAM. На заре эры персональных компьютеров весь обмен данными с устройствами по любому мосту шел через ЦПУ, негативно влияя на общую производительность системы. Чтобы этого избежать некоторые устройства получили возможность прямого доступа к памяти (DMA - direct memory access). DMA позволяет устройствам получать и сохранять данные в RAM с помощью Северного моста, не используя ЦПУ (и неизбежно влияя на его производительность). Сегодня все высокопроизводительные устройства, подключенные к любому мосту, могут использовать DMA. И хотя это очень сильно снижает загрузку ЦПУ, это создает конкуренцию за пропускную способность Северного моста, так как запросы DMA соревнуются с доступом ЦПУ к RAM. Эта проблема должна приниматься во внимание.
Второе "бутылочное горлышко" относится к шине от Северного моста к RAM. Точные детали устройства этой шины зависят от используемого типа памяти. На старых системах только одна шина ведет ко всем чипам RAM и параллельный доступ невозможен. Современные типы RAM требуют двух раздельных шин (или каналов, как они называются для DDR2, см. рисунок 2.8), что удваивает доступную пропускную способность. Северный мост распределяет доступ к памяти между каналами. Более новые технологии, (FB-DRAM, например) добавляют ещё больше каналов.
Имея в виду ограниченную пропускную способность, важно так составить расписание доступа к памяти, чтобы минимизировать задержки. Как мы увидим, процессоры намного быстрее и должны ждать доступа к памяти, несмотря на использование процессорных кэшей. Когда к памяти одновременно пытаются получить доступ множество процессоров, их ядер или потоков, ожидание становится ещё длиннее. Это также справедливо для операций DMA.
Кроме параллельного доступа к памяти есть и другие проблемы. Сами модели доступа к данным очень сильно влияют на производительность подсистемы памяти, особенно когда есть несколько каналов памяти. Модели доступа к данным RAM будут подробно обсуждаться в разделе 2.2.
На некоторых более дорогих системах Северный мост не содержит контроллера памяти. Вместо этого Северный мост может быть подключен к нескольким внешним контроллерам памяти (в следующем примере к четырем).
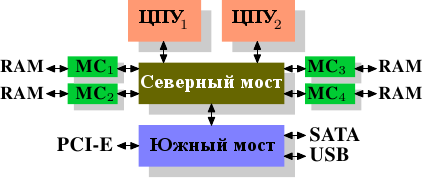
Рисунок 2.2: Северный мост с внешними контроллерами памяти
Преимущество такой архитектуры в том, что есть больше, чем одна шина памяти и, следовательно, общая пропускная способность больше. Также этот дизайн поддерживает больший объем памяти. При параллельном доступе к памяти задержка снижается за счет одновременного доступа к разным банкам. Это особенно верно, когда к Северному мосту подключено несколько процессоров, как на рисунке 2.2. Для такого дизайна первичное ограничение - это внутренняя пропускная способность Северного моста, феноменальная для этой архитектуры (от Intel). {Для полноты следует заметить, что такое расположение контроллеров памяти может быть использовано для других целей, таких как ⌠RAID памяти■, полезный при использовании памяти с возможностью горячей замены.}
Использование нескольких контроллеров памяти не единственный способ увеличить пропускную способность памяти. Другой популярный способ - это встраивать контроллеры памяти в ЦПУ и присоединять к каждому ЦПУ память. Эта модель популярна на системах с архитектурой SMP (symmetric multiprocessing), базирующихся на процессорах Opteron от AMD. Рисунок 2.3 показывает такую систему. У Intel, начиная с процессоров Nehalem, будет поддержка технологии Common System Interface (CSI). Это в основном тот же подход: встроенный контроллер памяти с возможностью локальной памяти для каждого процессора.
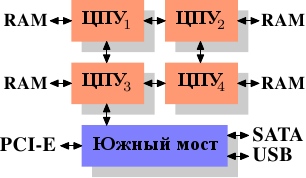
Рисунок 2.3: Встроенный контроллер памяти
В такой архитектуре количество банков памяти равно количеству процессоров. На четырехпроцессорной машине пропускная способность памяти будет в 4 раза больше и отпадет необходимость в сложном Северном мосте с огромной пропускной способностью. То, что контроллер памяти встроен в ЦПУ, также имеет ряд преимуществ, мы не будем сейчас в это углубляться.
Но у такой архитектуры есть и недостатки. Во-первых, так как по-прежнему вся память машины должна быть доступна для всех процессоров, память более не является однородной (отсюда и название - "архитектура с неоднородной памятью", NUMA - Non-Uniform Memory Architecture). Локальная память процессора доступна ему на обычной скорости. Ситуация меняется, когда нужно получить доступ к памяти, расположенной на другом процессоре. Тут приходится использовать соединения между процессорами. Чтобы получить доступ к памяти ЦПУ2 из ЦПУ1, нужно пройти по одному соединению. Чтобы получить доступ к памяти ЦПУ4 из ЦПУ1, нужно пройти по двум соединениям.
Каждый проход по соединению имеет соответствующую стоимость. Мы говорим о "факторах NUMA", когда описываем дополнительное время, необходимое, чтобы достичь удаленной памяти. Пример архитектуры на рисунке 2.3 имеет два уровня для каждого ЦПУ: ЦПУ, который находится рядом, и ЦПУ, который находится через два соединения. На более сложных машинах число уровней может быть значительно больше. Есть также архитектуры (например x445 у IBM x445 и Altix у SGI), где более одного типа соединения. ЦПУ организованы в узлы, и внутри узла время доступа к памяти может быть однородным или иметь небольшой фактор NUMA. Соединение между узлами может быть очень дорогим, с большим фактором NUMA.
Массовые машины с архитектурой NUMA существуют сегодня и, наверное, будут играть все большую роль в будущем. Ожидается, что с конца 2008 года все машины с технологией SMP будут использовать архитектуру NUMA. Ограничения этой архитектуры делают важной способность программы учитывать то, что она использует NUMA. В главе 5 мы еще обсудим архитектуры машин и некоторые технологии, которые ядро Linux предоставляет для программ.
Кроме технических деталей, описанных в оставшейся части этой главы есть несколько дополнительных факторов, влияющих на производительность RAM. Программное обеспечение не может на них влиять, поэтому в этом разделе они не описываются. Заинтересованный читатель может узнать о некоторых из них в разделе 2.1. Это нужно только для полноты картины и возможно будет полезно при принятии решения о приобретении компьютера.
Следующие две главы обсуждают детали устройства памяти на уровне выходов и протокол доступа между контроллером памяти и чипами DRAM. Программисты найдут эту информацию поучительной, так как эти детали объясняют, почему доступ к RAM работает так, как он работает. Это не обязательное знание и читатель, ищущий темы, более приближенные к повседневной жизни, может перейти к разделу 2.2.5.
| Назад | Оглавление | Вперед |