Библиотека сайта rus-linux.net
Шесть лучших программ для Data Mining с открытым исходным кодом
Оригинал: Six of the Best Open Source Data Mining ToolsАвтор: Chandan Goopta
Дата публикации: 9 октября 2014 года
Перевод: А. Кривошей
Дата перевода: май 2015 г.
Сегодня в мире происходит экспоненциальный рост количества данных. Однако эти данные, по большей части, неструктурированы, поэтому больших усилий требует процесс их обработки и извлечения полезной информации, а также преобразование ее в удобную для последующей работы форму. Здесь на сцену выходит data mining. Для решения задач обработки данных разработано большое количество инструментов, использующих элементы искусственного интеллекта, машинного обучения и других технологий обработки данных.
Ниже представлены шесть мощных программ с открытым исходным кодом для data mining:
RapidMiner (ранее известный как YALE)

Эта программа, написанная на Java, предлагает продвинутые возможности анализа данных, реализованные в виде основанного на шаблонах фреймвока. При этом пользователю вообще не требуется писать код. RapidMiner предлагается скорее в виде сервиса, а не отдельной программы, и занимает верхнюю позицию в нашем списке.
Кроме того, RapidMiner обеспечивает предварительную обработку и визуализацию данных, предиктивный анализ, статистическое моделирование. И наконец, он поддерживает учебные схемы, модели и алгоритмы из WEKA, а также скрипты на R.
RapidMiner распространяется под лицензией AGPL, и его можно скачать с SourceForge (бесплатно предлагается версия, которая на данный момент является предыдущей по отношению к коммерческой версии).
WEKA
Изначально WEKA была разработана для анализа данных сельскохозяйственного сектора. Затем программа была переписана на Java и стала значительно сложнее. Теперь она используется в различных областях, включая визуализацию и алгоритмы для анализа данных и предиктивного моделирования. Она бесплатна и распространяется под лицензией GNU General Public License, что является большим плюсом по сравнению с RapidMiner, так как пользователи могут дорабатывать программу под свои нужды.
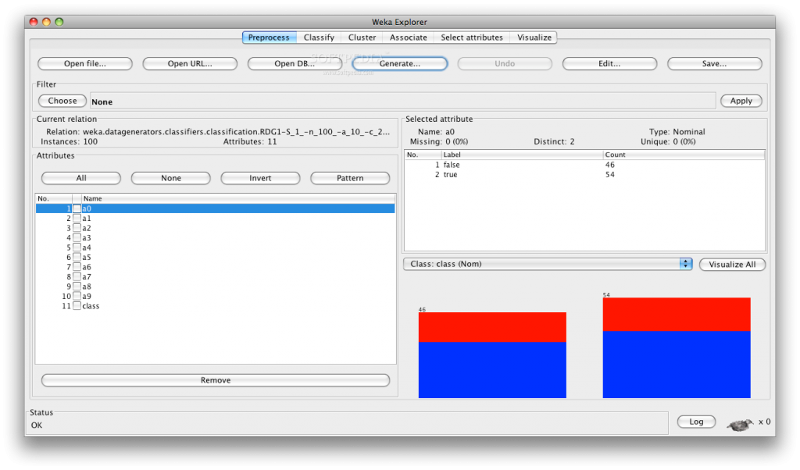
WEKA поддерживает ряд стандартных задач data mining, включая подготовку данных, визуализацию и выбор признаков.
Язык программирования R

R - это проект GNU, который изначально был написан на C и Fortran. Затем большое количество модулей было написано на самом R. Это свободный язык программирования и окружение для статистической обработки и визуализации данных. Язык R широко используется для разработки статистических программ и анализа данных. Простота использования и масштабируемость очень сильно повысили популярность R в последние годы.
Помимо задач data mining R хорошо подходит и для решения других близких задач, таких как линейная и нелинейная регрессия, классические статистические методы, анализ временных рядов и так далее.
Orange
Python сейчас находится на пике популярности благодаря своей простоте и легкости изучения в сочетании с мощью. Поэтому, если вы ищете подходящий инструмент, и знаете Python, вам подойдет Orange - мощная утилита с открытым исходным кодом.
Вам понравится сочетание визуального программирования с написанием скриптов на Python. Также имеются компоненты для машинного обучения, биоинформатики и анализа текстов.
KNIME
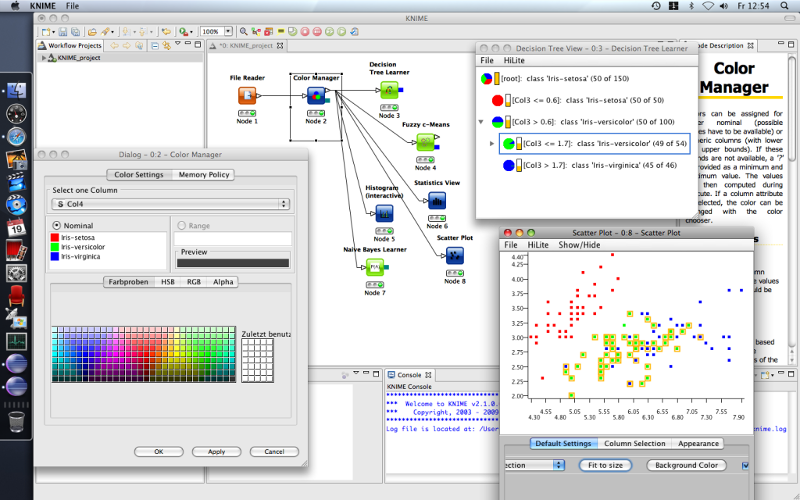
Подготовка данных включает три главных этапа: извлечение, преобразование и загрузку. KNIME обеспечивает выполнение всех трех. Он предлагает графический пользовательский интефейс, позволяющий конструировать процесс обработки данных. Это платформа с открытым исходным кодом для анализа данных и составления отчетов. В KNIME также интегрированы различные компоненты для машинного обучения и data mining, обеспечивающие совместно с концепцией построения конвейера из отдельных модулей возможности для бизнес-аналитики и анализа финансовых данных.
KNIME написан на Java и сделан на базе Eclipse, поэтому его возможности легко расширяются с помощью плагинов. Дополнительную функциональность можно добавить на лету. Множество модулей уже включено в базовую версию.
NLTK
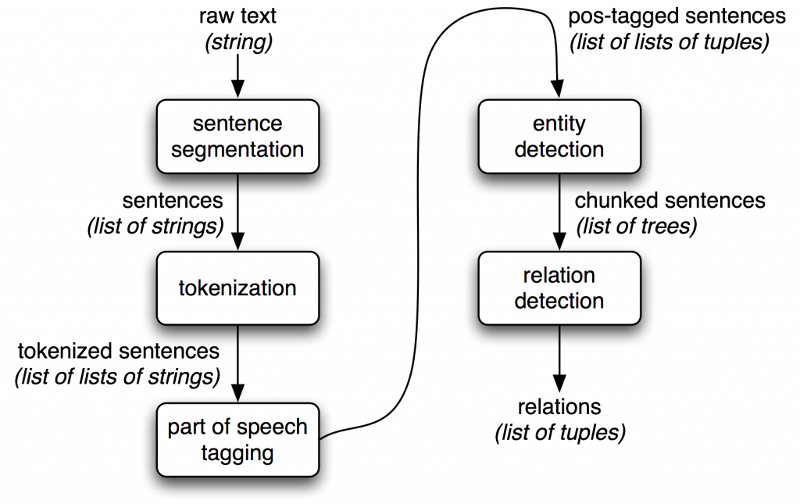
Если речь идет о задачах обработки естественного языка, ничто не сравнится с NLTK, который обеспечивает полный набор программного обеспечения для таких задач, включая data mining, машинное обучение, извлечение данных из веб-страниц, анализ тональности текста и другие задачи в области анализа языков. Поскольку NLTK написан на Python, вы можете включать его в свои приложения, подстраивая под свои задачи.