Библиотека сайта rus-linux.net
Руководство по созданию простой UNIX-подобной ОС
4. Таблицы GDT и IDT
Оригинал: "4. The GDT and IDT"Автор: James Molloy
Дата публикации: 2008
Перевод: Н.Ромоданов
Дата перевода: январь 2012 г.
GDT и IDT являются таблицами дескрипторов. Это массивы флагов и однобитовых значений, описывающих работу либо системы сегментации (в случае GDT), либо таблицу векторов прерываний (IDT).
К сожалению, немного сложной теории, но потерпите - поскольку скоро она закончится!
4.1. Таблица глобальных дескрипторов GDT (теория)
В архитектуре x86 есть два способа защиты памяти и реализации виртуальной памяти - сегментация и страничная организация памяти.
При сегментации доступ к памяти осуществляется внутри сегмента. То есть адрес памяти добавляется к базовому адресу сегмента и проверяется длина сегмента. Вы можете рассматривать сегмент как окно в адресном пространстве. Процесс не знает, что это окно, все, что он видит - линейное адресное пространство, начиная с нуля и до длины сегмента.
Что касается страничной организации памяти, то адресное пространство делится на блоки (обычно размером 4 Кб, но его можно изменить), называемые страницами. Каждая страница может быть отображена в физическую память - отображается на то, что называется "фрейм". Либо отображение может не быть. Таким образом, вы можете создавать виртуальные пространства памяти.
У каждого из этих методов есть свои собственные преимущества, но страничная организация памяти намного лучше. Сегментация, хотя все еще используется, быстро устаревает как способ защиты памяти и виртуальной памяти. На самом деле, в архитектуре x86-64 для того, чтобы некоторые ее команды работали должным образом, требуется плоская модель памяти (один сегмент с базой с адресом 0 и границей с адресом 0xFFFFFFFF).
Сегментация, однако, встроена непосредственно в архитектуру x86. Ее обойти невозможно. Итак, мы собираемся показать вам, как создать вашу собственную таблицу глобальных дескрипторов - список дескрипторов сегментов.
Как упоминалось ранее, мы попытается создать плоскую модель памяти. Окно сегмента должно начинаться с адреса 0x00000000 и продолжаться до адреса 0xFFFFFFFF (конец памяти). Однако есть одна вещь, которую при сегментации делать можно, а при страничной организации памяти - нет, это задание уровня кольца.
Кольцо определяет уровень привилегий - нулевое кольцо является наиболее привилегированным и еще есть, как минимум, три кольца. Говорят, что процессы, запущенные в нулевом кольце, работают в режиме ядра или в режиме супервизора, поскольку они могут использовать такие инструкции, как sti и cli, которые большинство процессов использовать не может. Как правило, кольца 1 и 2 не используются. Технически в них можно получить доступ к большему подмножеству инструкций режима супервизора, чем это можно сделать в кольце 3. В некоторых микроядерных архитектурах эти кольца используются для запуска серверных процессов или драйверов.
Внутри дескриптора сегмента есть число, указывающее уровень кольца, который используется. Чтобы изменить уровень кольца (что мы сделаем позже), нам, среди прочего, потребуются сегменты, представляющие как кольцо 0, так и кольцо 3.
4.2. Таблица глобальных дескрипторов GDT (практика)
Хорошо, это был фрагмент теории, позволяющий понять подробности реализации.
Единственное, что я забыл упомянуть, это то, что GRUB настроит для вас таблицу GDT. Проблема в том, что вы не знаете, где находится GDT, или то, что в ней задано. Так что если вы ее случайно перезапишите, после трехкратного повторения ошибки ваш компьютер перезагрузится. Это плохо.
В архитектуре x86 у нас есть 6 регистров сегментации. В каждом хранится смещение, указываемое в GDT. Это: cs (сегмент кода), ds (сегмент данных), es (дополнительный сегмент), fs, gs, ss (сегмент стека). В сегменте кода должна быть ссылка на дескриптор, который установлен как 'code segment' (сегмент кода). Для этого в байте доступе существует флаг. Остальные ссылки должны указывать на дескриптор, который определен как 'data segment' (сегмент данных).
4.2.1. Файл descriptor_tables.h
Запись в таблице GDT выглядит следующим образом:
// В этой структуре хранится содержимое одной записи GDT.
// Мы используем атрибут 'packed', которые указывает компилятору GCC,
// что в этой структуре выравнивание не выполняется.
struct gdt_entry_struct
{
u16int limit_low; // Младшие 16 битов граничного значения limit.
u16int base_low; // Младшие 16 битов адресной базы.
u8int base_middle; // Следующие 8 битов адресной базы.
u8int access; // Флаги доступа, определяющие в каком кольце можно использовать этот сегмент.
u8int granularity;
u8int base_high; // Последние 8 битов адресной базы.
} __attribute__((packed));
typedef struct gdt_entry_struct gdt_entry_t;
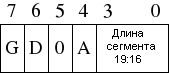
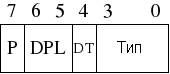
Большинство этих полей должны быть понятны сами по себе. Формат байта доступа показан на рисунке, приведенном ранее, а здесь показан формат байта гранулярности.
P - Сегмент присутствует? (1 = Да)
DPL - Дескриптор уровня привилегий - кольцо 0 - 3
DT - Тип дескриптора
Type - Тип сегмента - сегмент кода/сегмент данных
G - Гранулярность (0 = 1 байт, 1 = 1 кбайт)
D - Размер операнда (0 = 16 бит, 1 = 32 бита)
0 - Всегда должно быть нулевое значение
A - Возможность доступа из системы (всегда должно быть нулевым)
Для того, чтобы сообщить процессору, где найти нашу таблицу GDT, мы должны передать ему адрес специальной структуры с указателями:
struct gdt_ptr_struct
{
u16int limit; // Верхние 16 битов всех предельных значений селектора.
u32int base; // Адрес первой структуры gdt_entry_t.
}
__attribute__((packed));
typedef struct gdt_ptr_struct gdt_ptr_t;
Базой является адрес первой записи в нашей таблице GDT, предельным значением будет размер таблицы минус один (последний допустимый адрес в таблице).
Определения этих структур вместе с прототипами должны находиться в заголовочном файле descriptor_tables.h.
// Общедоступная функция инициализации. void init_descriptor_tables();
4.2.2. Файл descriptor_tables.c
В файле descriptor_tables.c у нас находятся несколько объявлений:
// // descriptor_tables.c - Инициализирует таблицы GDT и IDT и определяет // обработчик, используемый для ISR и IRQ по умолчанию. // Разработано на базе кода из руководства по разработке ядра – автор Bran. // Переписано для руководств по разработке ядра - автор James Molloy // #include "common.h" #include "descriptor_tables.h" // Предоставляет нам доступ к нашим ассемблерным функциям из нашего кода на C. extern void gdt_flush(u32int); // Прототипы внешних функций. static void init_gdt(); static void gdt_set_gate(s32int,u32int,u32int,u8int,u8int); gdt_entry_t gdt_entries[5]; gdt_ptr_t gdt_ptr; idt_entry_t idt_entries[256]; idt_ptr_t idt_ptr;
Обратите внимание на функцию gdt_flush - она будет определена в ассемблерном файле и для нас будет загружен указатель на нашу таблицу GDT.
// Подпрограмма инициализации - заносит нули во все подпрограммы, обслуживающие прерывания,
// инициализирует таблицы GDT и IDT.
void init_descriptor_tables()
{
// Initialise the global descriptor table.
init_gdt();
}
static void init_gdt()
{
gdt_ptr.limit = (sizeof(gdt_entry_t) * 5) - 1;
gdt_ptr.base = (u32int)&gdt_entries;
gdt_set_gate(0, 0, 0, 0, 0); // Null segment
gdt_set_gate(1, 0, 0xFFFFFFFF, 0x9A, 0xCF); // Code segment
gdt_set_gate(2, 0, 0xFFFFFFFF, 0x92, 0xCF); // Data segment
gdt_set_gate(3, 0, 0xFFFFFFFF, 0xFA, 0xCF); // User mode code segment
gdt_set_gate(4, 0, 0xFFFFFFFF, 0xF2, 0xCF); // User mode data segment
gdt_flush((u32int)&gdt_ptr);
}
// Устанавливает значения для одной записи в GDT.
static void gdt_set_gate(s32int num, u32int base, u32int limit, u8int access, u8int gran)
{
gdt_entries[num].base_low = (base & 0xFFFF);
gdt_entries[num].base_middle = (base >> 16) & 0xFF;
gdt_entries[num].base_high = (base >> 24) & 0xFF;
gdt_entries[num].limit_low = (limit & 0xFFFF);
gdt_entries[num].granularity = (limit >> 16) & 0x0F;
gdt_entries[num].granularity |= gran & 0xF0;
gdt_entries[num].access = access;
}
Давайте просто проанализируем на минутку этот код. Сначала init_gdt настраивает структуру указателей GDT - предельное значение limit является размером записи GDT, умноженной на 5, - у нас 5 записей. Почему 5 записей? Это очевидно, поскольку у нас есть дескрипторы сегмента кода и сегмента данных для ядра, дескрипторы сегмента кода и сегмента данных для пользовательского режима и пустая запись null. Она должна присутствовать, иначе могут произойти неприятные вещи.
Затем gdt_init настраивает 5 дескрипторов с помощью обращения к gdt_set_gate. gdt_set_gate просто делает некоторые сложные битовые преобразования и сдвиги, с которыми можно разобраться при более детальном рассмортрении кода. Обратите внимание, что единственное различие в в дескрипторах четырех сегментов - это байт доступа 0x9A, 0x92, 0xFA, 0xF2. кода выполняется отображение, вы увидите, что будут меняться биты, которые в диаграмме, приведенной выше, отмечены как поля type и DPL. DPL является дескриптором уровня привилегий: 3 - для пользовательского кода и 0 - для кода ядра. Type определяет, является ли сегментом кода или сегментом данных (процессор проверяет это часто и это может быть причиной большого разочарования).
Наконец, у нас есть функция на языке ассемблера, которая запишет указатель GDT.
[GLOBAL gdt_flush] ; Позволяет коду на C обращаться gdt_flush(). gdt_flush: mov eax, [esp+4] ; Берет указатель на таблицу GDT, переданную в качестве параметра. lgdt [eax] ; Загружает новый указатель GDT mov ax, 0x10 ; 0x10 является смещением, находящимся в таблице GDT и указываемым на наш сегмент данных mov ds, ax ; Загрузка переключателей всех сегментов данных mov es, ax mov fs, ax mov gs, ax mov ss, ax jmp 0x08:.flush ; 0x08 является смещением на наш сегмент кода: Длинный переход! .flush: ret
Эта функция берет первый параметр, переданный ей (в esp+4), загружает в GDT значение указателей (с помощью инструкции lgdt), затем загружает переключатель сегментов для сегментов кода и сегментов данных. Заметьте, что длина каждой записи GDT составляет 8 байтов, а дескриптором кода ядра является второй сегмент, так что смещение будет равно 0x08. Аналогичным образом дескриптор данных ядра является третьим, так что в этом случае смещение будет 16 = 0x10. Здесь мы переносим значение 0x10 в регистры сегмента данных ds,es,fd,gs,ss. Чтобы изменить сегмент кода, нужно поступить немного по-другому; мы должны выполнить длинный переход. Это приводит к неявному изменению значения CS.
4.3. Таблица дескрипторов прерываний IDT (теория)
Есть моменты, когда вы хотите прервать работу процессора. Вы хотите остановить то, что он делает, и заставить его сделать что-то другое. Примером этого является ситуация, когда таймер или клавиатура делает запрос на прерывание (IRQ). Прерывание похоже на сигнал POSIX - он сообщает вам, что произошло что-то интересное. Процессор может регистрировать 'обработчики сигналов' (обработчики прерываний), которые имеют дело с прерываниями, затем передать управление в код, который обработает прерывание. Прерывания могут обрабатываться через внешние ресурсы - через IRQ, или с использованием внутренних ресурсов, т.е. с помощью инструкции 'int n'. Есть очень веская причины стараться обрабатывать прерывания с помощью внешнего программного обеспечения, но это уже тема другой главы!
Таблица дескрипторов прерываний The Interrupt Descriptor Table указывает процессору, где найти обработчики для каждого прерывания. Эта таблица очень похожа на таблицу GDT. Это просто массив записей, каждая из которых соответствует номер прерывания. Есть 256 допустимых номеров прерываний, так что должно быть 256 записей. Если происходит прерывание, а для него нет записи (подходит даже запись со значением NULL), то процессор перейдет в режим panic и произойдет перезагрузка системы.
4.3.1. Отказы, ловушки и исключения
Процессору иногда нужно будет передать сигналы в ваше ядро. Может случиться что-то важное, например, деление на ноль или ошибка при подкачке страницы. Для того, чтобы это сделать, используются первые 32 прерывания. Поэтому вдвойне важно, чтобы все они не отображались в NULL, в противном случае после троекратной ошибки процессор выполнит перезагрузку (эмулятор bochs перейдет в режим panic и выдаст ошибку 'unhandled exception' - 'необработанное исключение').
Ниже приведены специальные прерывания, связанные с работой процессора:
- 0 - Прерывание деления на ноль
- 1 - Прерывание отладки (пошагового исполнения)
- 2 - Немаскируемое прерывание
- 3 - Прерывание точки останова
- 4 - Переполнение при выполнении команды Into
- 5 - Прерывание выхода за границы данных
- 6 - Прерывание неправильного кода операции
- 7 - Прерывание отсутствие сопроцессора
- 8 - Прерывание двойной ошибки (код ошибки помещается в стек)
- 9 - Нарушение сегментации памяти сопроцессором
- 10 - Неправильный TSS (код ошибки помещается в стек)
- 11 - Отсутствие сегмента (код ошибки помещается в стек)
- 12 - Ошибка стека (код ошибки помещается в стек)
- 13 - Ошибка общей защиты (код ошибки помещается в стек)
- 14 - Ошибка системы страничной организации памяти (код ошибки помещается в стек)
- 15 - Неизвестное прерывание
- 16 - Ошибка сопроцессора
- 17 - Прерывание контроля выравнивания
- 18 - Прерывание, связанное с общей работой процессора
- 19-31 - Зарезервировано
4.4. Таблица дескрипторов прерываний IDT (практика)
4.4.1. Файл descriptor_tables.h
Мы должны добавить в файл descriptor_tables.h немного определений:
// Структура, описывающая шлюз прерываний.
struct idt_entry_struct
{
u16int base_lo; // Младшие 16 битов адреса, куда происходи переход в случае возникновения прерывания.
u16int sel; // Переключатель сегмента ядра.
u8int always0; // Это значение всегда должно быть нулевым.
u8int flags; // More flags. See documentation.
u16int base_hi; // Старшие 16 битов адреса, куда происходи переход.
} __attribute__((packed));
typedef struct idt_entry_struct idt_entry_t;
// Структура, описывающая указатель на массив обработчиков прерываний.
// Этот формат подходит для загрузки с помощью 'lidt'.
struct idt_ptr_struct
{
u16int limit;
u32int base; // Адрес первого элемента нашего массива idt_entry_t.
} __attribute__((packed));
typedef struct idt_ptr_struct idt_ptr_t;
// Эти внешние директивы позволят нам получить доступ к адресам наших ассемблерных обработчиков прерываний ISR.
extern void isr0 ();
...
extern void isr31();

Видите? Очень похоже на запись GDT и структуры ptr. На рисунке показан формат поля флагов. Младшие 5 битов должны всегда иметь одно и то же значение 0b0110, т.е.14 в десятичной системе. DPL описывает уровень привилегий, с какими, как мы ожидаем, будет осуществляться вызов - в нашем случае равен нулю, но, поскольку мы движемся вперед, мы должны изменить его на 3. Бит P означает, что запись есть. Любой дескриптор со сброшенным этим битом явно указывает на исключительную ситуацию "прерывание не обрабатывается".
4.4.2. Файл descriptor_tables.c
Мы должны изменить этот файл и добавить в него наш новый код:
extern void idt_flush(u32int);
...
static void init_idt();
static void idt_set_gate(u8int,u32int,u16int,u8int);
...
idt_entry_t idt_entries[256];
idt_ptr_t idt_ptr;
...
void init_descriptor_tables()
{
init_gdt();
init_idt();
}
...
static void init_idt()
{
idt_ptr.limit = sizeof(idt_entry_t) * 256 -1;
idt_ptr.base = (u32int)&idt_entries;
memset(&idt_entries, 0, sizeof(idt_entry_t)*256);
idt_set_gate( 0, (u32int)isr0 , 0x08, 0x8E);
idt_set_gate( 1, (u32int)isr1 , 0x08, 0x8E);
...
idt_set_gate(31, (u32int)isr32, 0x08, 0x8E);
idt_flush((u32int)&idt_ptr);
}
static void idt_set_gate(u8int num, u32int base, u16int sel, u8int flags)
{
idt_entries[num].base_lo = base & 0xFFFF;
idt_entries[num].base_hi = (base >> 16) & 0xFFFF;
idt_entries[num].sel = sel;
idt_entries[num].always0 = 0;
// Мы должны раскомментировать приведенную ниже операцию OR в случае, если нужен пользовательский режим.
// Эта операция устанавливает уровень привилегий, используемый шлюзом прерываний, равным 3.
idt_entries[num].flags = flags /* | 0x60 */;
}
Мы также намерены добавить в gdt.s следующий код:
[GLOBAL idt_flush] ; Allows the C code to call idt_flush(). idt_flush: mov eax, [esp+4] ; Берет указатель на IDT, передаваемый в качестве параметра. lidt [eax] ; Загружает указатель IDT. ret
4.4.3. Файл interrupt.s
Отлично! У нас есть код, который будет сообщать процессору, где искать наши обработчики прерываний - но мы еще ничего не написали!
Когда процессор получает прерывание, он сохраняет в стеке содержимое важных регистров (указателя команд, указателя стека, сегментов кода и данных, регистра флагов). Затем он по нашей таблице IDT находит место, где расположен обработчик прерываний, и передает ему управление.
Здесь точно также, как и в случае с обработчиками сигналов POSIX, когда запускается ваш обработчик, вы не получите никакой информации о том, какое прерывание произошло. Поэтому, к сожалению, нам недостаточно иметь один общий обработчик, мы должны написать по отдельному обработчику для каждого прерывания, которое мы хотим обрабатывать. Это довольно нудно, поэтому мы хотим сократить количество повторяющегося кода до минимума. Мы делаем это, если напишем много обработчиков, которые просто помещают в стек код прерывания (жестко прописано в ассемблере) и вызывают общую функцию обработчика.
К сожалению, все это второстепенно; у нас есть еще одна проблема - некоторые прерывания также помещают в стек код ошибки. Мы не можем вызвать общие функцию до тех пор, пока не обеспечим единообразное состояние стека, поэтому для тех прерываний, которые не помещают в стек код ошибки, мы будет записывать в стек еще одно фиктивно значение с тем, чтобы состояние стека было одинаковое.
[GLOBAL isr0] isr0: cli ; Сброс прерываний push byte 0 ; Помещаем в стек фиктивный код ошибки (в случае, если ISR0 не помещает в стек свой собственный код ошибки) push byte 0 ; Помещаем в стек номер прерывания (0) jmp isr_common_stub ; Переходим к общей части обработчика.
Это пример работающей подпрограммы, но сделать ее 32 версии - для этого потребуется написать много кода. Впрочем, мы можем использовать макросредство NASM с тем, чтобы уменьшить количество работы:
%macro ISR_NOERRCODE 1 ; define a macro, taking one parameter
[GLOBAL isr%1] ; %1 доступ к первому параметру.
isr%1:
cli
push byte 0
push byte %1
jmp isr_common_stub
%endmacro
%macro ISR_ERRCODE 1
[GLOBAL isr%1]
isr%1:
cli
push byte %1
jmp isr_common_stub
%endmacro
Теперь мы можем просто написать вызовы макрофункции
ISR_NOERRCODE 0 ISR_NOERRCODE 1 ...
Гораздо меньше работы, и стоит делать все, что делает нашу жизнь проще. Просмотр руководства Intel укажет вам, что только в прерываниях 8, 10-14 код ошибки помещается в стек. Остальные требуют использовать фиктивные коды ошибок.
Мы почти у цели - это правда!
Осталось сделать только две крупные вещи: первая - создать на ассемблере общую функцию обработки. Вторая состоит в создании высокоуровневой функции обработки на языке C.
; В файле isr.c [EXTERN isr_handler] ; Это наша общая часть ISR. Она сохраняет состояние процессора, настраивает ; сегменты на использование в режиме ядра, вызывает обработчик отказов, написанный на C ; и, наконец, восстанавливает состояние стека. isr_common_stub: pusha ; Помещает в стек содержимое регистров edi,esi,ebp,esp,ebx,edx,ecx,eax mov ax, ds ; Младшие 16 битов регистра eax = ds. push eax ; Сохранение дескриптора сегмента данных mov ax, 0x10 ; Загрузка сегмента данных ядра mov ds, ax mov es, ax mov fs, ax mov gs, ax call isr_handler pop eax ; Перезагрузка оригинального дескриптора сегмента данных mov ds, ax mov es, ax mov fs, ax mov gs, ax popa ; Выталкиваем из стека значения edi,esi,ebp... add esp, 8 ; Очищаем из стека код ошибки, помещаем в стек номер ISR sti iret ; Выталкиваем из стека следующие пять значений: CS, EIP, EFLAGS, SS и ESP
Этот фрагмент кода является нашим общим обработчиком прерывания. В нем, во-первых, используется команда 'pusha', которая помещает в стек всех регистры общего назначения. В нем в конце для восстановления регистров используется команда 'popa'. В нем также берется и помещается в стек переключатель текущего сегмента данных, все регистры сегмента устанавливаются в режим ядра, а после всего они восстанавливаются. В данный момент от этого действия проку не будет, он появится, когда мы переключимся в пользовательский режим. Обратите также внимание, что вызывается обработчик прерывания высокого уровня - isr_handler.
Когда возникает прерывание, процессор автоматически помещает информацию о своем состоянии в стек. В стек помещаются сегмент кода, указатель команд, регистр флагов, сегмент стека и указатель стека. Инструкция IRET специально предназначена для выхода из прерывания. Она выталкивает из стека эти значения и возвращает процессор в первоначальное состояние.
4.4.4. Файл isr.c
//
// isr.c -- Высокоуровневые подпрограмма обслуживания прерываний и обработчики запросов прерываний.
// Часть кода изменена в сравнении с кодом из руководства по разработке ядра – автор Bran.
// Переписано для руководств по разработке ядра - автор James Molloy
//
#include "common.h"
#include "isr.h"
#include "monitor.h"
// Сюда поступает вызов из обработчика прерываний, написанного на ассемблере.
void isr_handler(registers_t regs)
{
monitor_write("recieved interrupt: ");
monitor_write_dec(regs.int_no);
monitor_put('\n');
}
Здесь объяснять особенно нечего - обработчик прерывания выдает на экран сообщение, указывая номер обрабатываемого прерывания. Здесь используется структура registers_t, куда мы помещаем содержимое регистров и которая была определена в isr.h:
4.4.5. Файл isr.h
//
// isr.h -- Интерфейс и структуры для высокоуровневых подпрограмм обслуживания прерываний.
// Часть кода изменена в сравнении с кодом из руководства по разработке ядра – автор Bran.
// Переписано для руководств по разработке ядра - автор James Molloy
//
#include "common.h"
typedef struct registers
{
u32int ds; // Переключатель сегмента данных
u32int edi, esi, ebp, esp, ebx, edx, ecx, eax; // Помещает в стек значения регистров с помощью pusha.
u32int int_no, err_code; // Номер прерывания и код ошибки (если он предоставляется)
u32int eip, cs, eflags, useresp, ss; // Значения автоматически помещаются процессором в стек.
4.4.6. Проверяем и выдаем результат
Ничего себе, это была действительно длинная глава! Не бойтесь - остальные главы не настолько длинные. Просто здесь мы должны были очень много сделать с тем, чтобы из этого что-нибудь получить.
Теперь мы можем это проверить! Добавьте следующий код к вашей функции main():
asm volatile ("int $0x3");
asm volatile ("int $0x4");
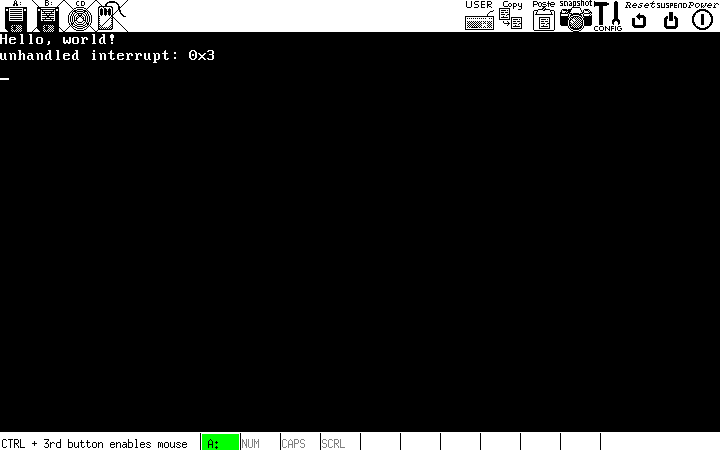
В результат будет вызвано два программных прерываний: 3 и 4. Вы должны увидеть выданные сообщения, похожие на те, что изображены на скриншоте.
Поздравляю! Теперь у вас есть ядро, которое может обрабатывать прерывания и создавать свои собственные таблицы сегментации (довольно бесполезная победа, если посмотреть на созданный код и рассмотренную теорию, но, к сожалению, от этого никуда не денешься!).
Пример кода для этого руководства можно получить здесь.
| Назад | К началу | Вперед |