Библиотека сайта rus-linux.net
Разработка сценариев командной оболочки для начинающих. Часть 3: Другие системные команды и их объединение в рамках конвейеров
Оригинал: The Beginner’s Guide to Shell Scripting 3: More Basic Commands & Chains
Автор: Yatri Trivedi
Дата публикации: 29 июля 2011 г.
Перевод: А.Панин
Дата перевода: 21 октября 2016 г.
Вы уже знаете о том, как создавать сценарии,
а также использовать аргументы и циклы for. Теперь давайте рассмотрим некоторые другие простые команды для работы с текстовыми файлами, а также вопросы связывания потоков ввода и вывода команд с файлами или с потоками ввода и вывода других команд.
Дополнительные полезные системные команды
Мы уже рассмотрели основные аспекты создания сценариев командной оболочки, а также методику использования в этих сценариях циклов for, поэтому вам следует ознакомиться с предыдущими статьями серии в том случае, если вы пропустили их.
Интерфейс командной строки системы по ряду причин является крайне удобным, причем возможность связывания команд является его наиболее важной особенностью. Если бы для выполнения дополнительного действия или использования вывода команды для какой-либо другой цели приходилось делать заметки или воспроизводить вывод всех команд, мы бы все уже давно сошли с ума. Функция перенаправления вывода команд позволяет сохранять вывод любой команды или использовать его непосредственно в качестве ввода другой команды. Мы также можем использовать файлы в качестве источников ввода и целей для сохранения вывода команд.
Перед тем как продолжить, давайте рассмотрим простые системные команды, которые могут успешно использоваться в множестве различных сценариев.
echo - команда, которая просто выводит (отображает) строку, переданную в качестве ее аргумента
echo аргумент с пробелами
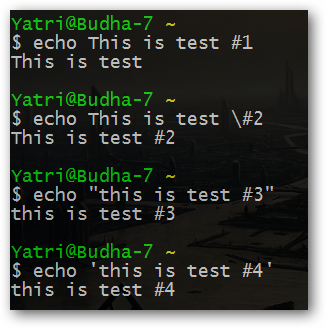
Как вы можете заметить, специальные символы должны "экранироваться" для их корректной обработки. Это операция осуществляется с помощью символа обратного слэша (\), размещенного перед специальным символом. Команда echo также отлично работает с переменными.
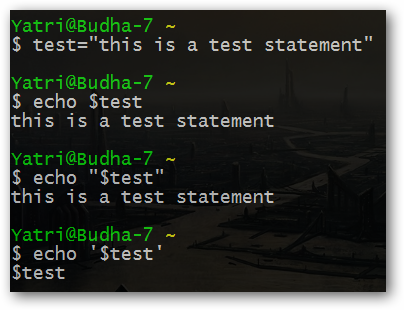
Очевидно, что одинарные и двойные кавычки работают по-разному. Если вас интересует дополнительная информация по данному вопросу, вы можете обратиться к статье "В чем разница между одинарными и двойными кавычками в командной оболочке Bash".
cat - команда, позволяющая выводить содержимое текстового файла.
cat имя_файла_для_вывода_содержимого
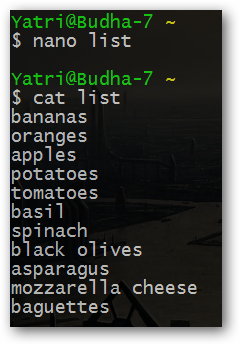
Давайте, к примеру, создадим текстовый файл со следующим содержимым с помощью текстового редактора Nano:
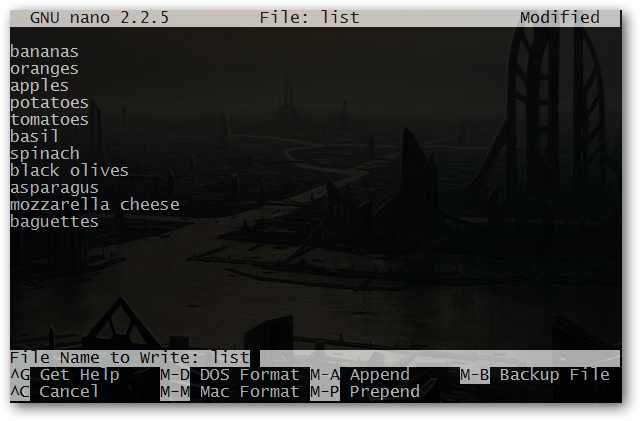
При использовании команды cat по отношению к данному файлу, мы увидим следующий вывод:
grep - одна из наиболее мощных и полезных команд, доступных в Linux. Ее имя расшифровывается как "Global/Regular Expression Print" ("Вывод результатов применения глобальных/регулярных выражений"). Она исследует файл и выводит все строки, соответствующие заданному шаблону. Так как шаблон основывается на "регулярном выражении", краткий шаблон может соответствовать множеству строк. Если это не так, вы всегда можете использовать в качестве шаблона непосредственно фрагмент искомых строк.
grep шаблон файл
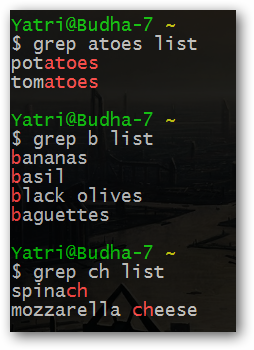
Я могу уверить вас в том, что grep имеет гораздо больше возможностей, но на текущий момент я предлагаю остановиться на наиболее простых из них.
Перенаправление вывода команд
Для перенаправления вывода команды в файл нам придется использовать специальный символ, а именно, знак "больше" (>).
Не желаете ли вы изменить созданный список продуктов? Для этого может использоваться следующая команда:
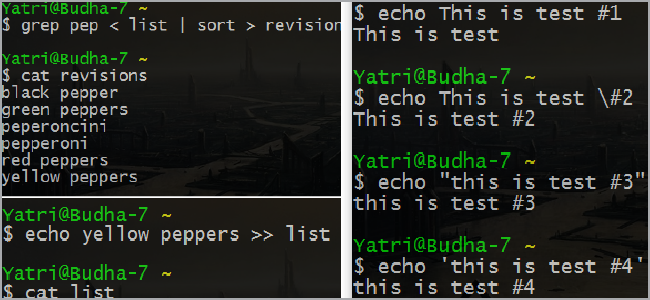
echo pepperoni > list
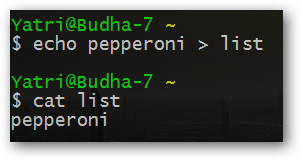
Вы можете обнаружить, что команда echo больше не выводит переданную строку, причем после изучения содержимого файла "list" станет окончательно ясно, что вывод был сохранен именно в нем.
Также следует обратить внимание на тот факт, что предыдущее содержимое файла "list" было удалено. Попробуйте выполнить эту команду снова:
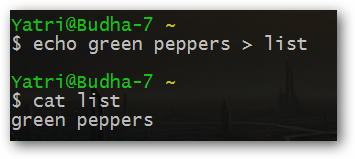
Подобное поведение может оказаться полезным при необходимости повторного использования файла, но чаще всего вам нужно будет просто добавлять строки в существующий файл. Для этой цели следует использовать два следующих друг за другом знака "больше":
echo yellow peppers >> list
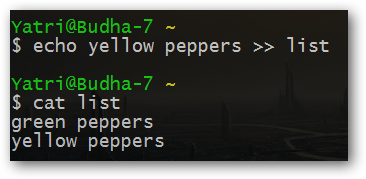
Достаточно просто! Мы ведь можем использовать эту команду для создания списка большего размера, не так ли?
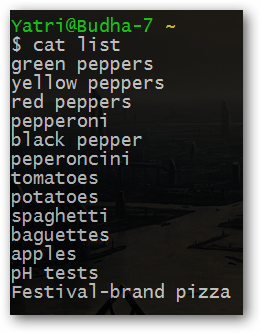
Все получилось. Я думаю, вы уже поняли, почему многие опытные пользователи используют интерфейс командной строки системы для создания списков задач и аналогичных целей, но и это еще не все.
Давайте возьмем вывод команды и направим его непосредственно в файл:
ls -al / > ~/rootlist
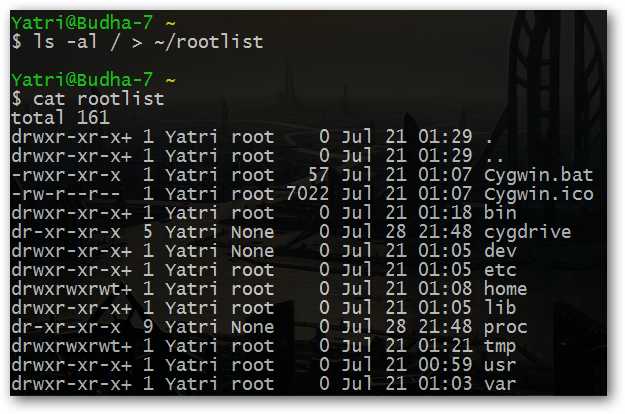
Создание списков файлов, их редактирование и выполнение команд по отношению к этим файлам никогда не было таким простым. И, помимо применения этих простых функций в процессе использования интерфейса командной строки системы, вы также можете применять их по своему усмотрению в сценариях командной оболочки.
Использование программных каналов или создание конвейеров
Название "программный канал" происходит от символа канала ("|", расположенного на кнопке с обратным слешем "\" на большинстве клавиатур). По сути, программный канал позволяет получать вывод одной команды и непосредственно передавать его на вход другой. Благодаря их существованию вы можете создавать длинные конвейеры команд для получения любого желаемого вывода, а также продуктивно использовать такие команды, как grep.
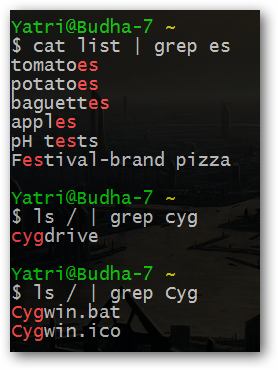
Данный механизм работает аналогично механизму перенаправления вывода (активируемому с помощью символа ">"), но при этом он позволяет осуществлять многократное связывание команд и является более универсальным, так как при его использовании данные не должны сохраняться в текстовом файле.
Очевидно, что при использовании шаблонов grep учитывается регистр. Вы можете использовать флаг "-i" для того, чтобы сообщить о необходимости игнорирования регистра символов шаблона.
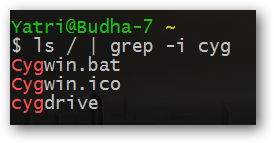
Перенаправление ввода команд
Вы также можете перенаправлять данные из файлов в потоки ввода команд с помощью символа "меньше" ("<").
cat < list
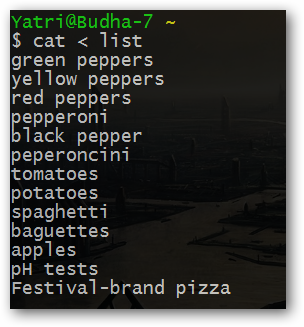
Вы можете заявить: "Это ничем не отличается от использования соответствующего аргумента!". Ну, в этом случае вы будете правы. Механизм перенаправления ввода команд полезен главным образом для связывания команд в конвейеры.
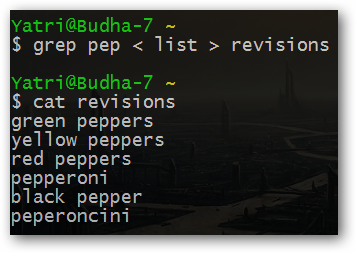
Предположим, что вам нужно сохранить все слова, содержащие последовательность букв "pep" из файла с именем "list" в новом файле с именем "revisions".
grep pep < list > revisions
Давайте немного модифицируем эту команду, добавив в нее функцию сортировки:
grep pep < list | sort > revisions
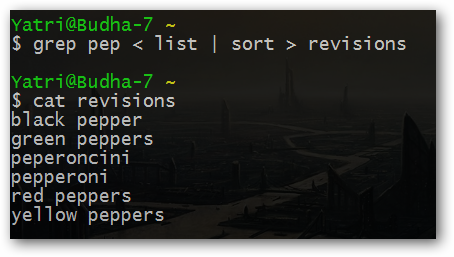
В данном случае "pep" используется в качестве поискового шаблона для исходного файла "list", после чего результаты поиска сортируются в алфавитном порядке (все строки, начинающиеся с заглавной буквы располагаются перед строками, начинающимися с прописной буквы) и сохраняются в целевом файле с именем "revisions".
Для иллюстрации принципа работы команды sort я предлагаю рассмотреть следующий пример:
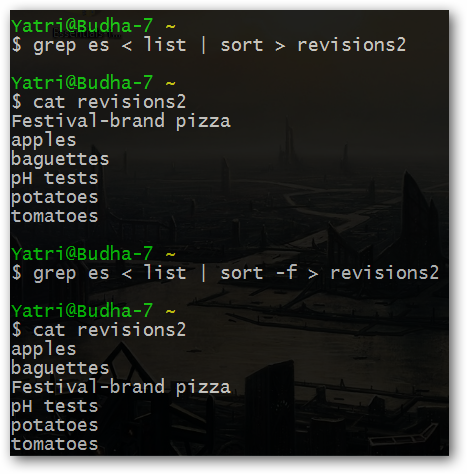
Как вы видите, после добавления флага "-f" команда sort начинает сортировать строки без учета регистра символов. Этот флаг позволяет отсортировать строки из текстового файла по алфавиту без учета регистра символов в тех случаях, когда он не имеет значения.
Простой сценарий
Давайте создадим сценарий, который будет использоваться следующим образом:
script поисковый_запрос файл_со_списком_строк
Он будет принимать поисковый запрос, использовать команду grep для поиска строк, удовлетворяющих этому запросу, сортировку найденных строк и их сохранение в другом файле.
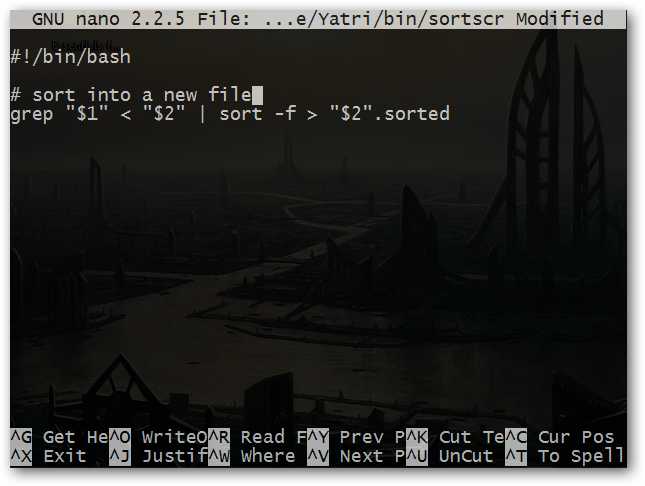
А это содержимое директории, в которой мы будем тестировать наш сценарий:
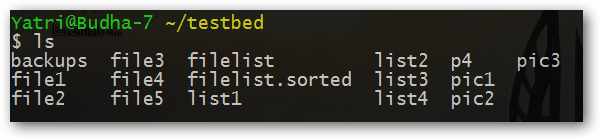
Я привел его по той причине, что мы можем создать файл со списком всех файлов из директории и использовать его в качестве файла со списком строк для тестирования сценария.
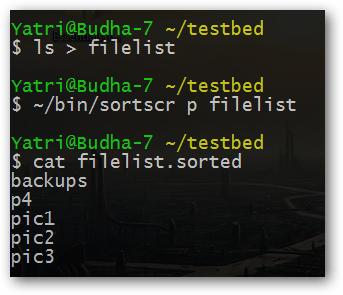
Несложно заметить, что сценарий корректно работает! Чем больше вы будете узнавать о правилах составления и использования регулярных выражений, тем более четкими станут ваши шаблоны для поиска строк. При этом любой шаблон, который может корректно записываться в двойных кавычках, сможет использоваться в качестве первого аргумента сценария.
Коль скоро речь зашла о сортировке, следует отметить, что вы можете не ограничиваться сортировкой по алфавиту. Обратитесь к страницам руководств следующих команд:
-
tsort- команда, реализующая более сложную топологическую сортировку. -
tr- команда, позволяющая связывать определенные символы с другими символами и заменять их друг на друга. -
uniq- команда, удаляющая любые неуникальные (следует читать: дублирующиеся) символы. -
awk- по-настоящему сложная команда для обработки текста, использующая собственный язык программирования и позволяющая, в том числе, разделять имена файлов на составные части. -
cut, paste/join- команды, которые могут оказаться полезными при необходимости выделения полей в тексте из файлов и добавления новых данных в столбцы. -
look- осуществляет поиск строк по аналогии с командойgrep, но при этом использует словарь (который также может быть создан пользователем) для поиска. -
wc- команда, которая позволяет осуществить подсчет строк, символов и других сущностей.
Сегодня мы рассмотрели команды, которые могут пригодиться как при работе с интерфейсом командной строки системы, так при разработке сценариев командной оболочки. Текстовые данные являются именно теми данными, которые используются ежедневно, поэтому навыки работы с ними, поиска в них тех или иных данных, а также их модификации являются ключевыми.
Какие сценарии вам нравятся больше всего? Вы пользуетесь какими-либо специфическими сценариями для работы с текстовыми файлами? Поделитесь своим мнением в разделе комментариев!