Библиотека сайта rus-linux.net
Библиотека Warp
Глава 11 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Warp
Авторы: Kazu Yamamoto, Michael Snoyman, Andreas Voellmy
Перевод: Н.Ромоданов
Очистка с помощью таймеров
В этом разделе объясняется, как реализован тайм-аут подключения и как осуществляется кэширование файловых дескрипторов.
Таймеры подключений
Чтобы предотвратить атаки вида Slowloris, взаимодействие с клиентом должно быть прервано в случае, если в течение определенного периода времени клиент не отправит достаточного количества данных. В языке Haskell есть стандартная функция, называемая timeout, тип которой определяется следующим образом:
Int -> IO a -> IO (Maybe a)
Первым аргументом является продолжительность тайм-аута, указываемая в микросекундах. Вторым аргументом является действие, которое обрабатывает ввод/вывод (IO). Эта функция возвращает значение Maybe a в контексте IO. Maybe определяется следующим образом:
data Maybe a = Nothing | Just a
Nothing указывает ошибку (без указания причины), а Just обрамляет успешное значение a. Поэтому timeout возвращает Nothing в случае, если действие не было завершено в указанное время. В противном случае возвращается успешное значение, обрамленное в Just. Функция timeout красноречиво показывает, какие возможности компоновки есть в замечательном языке Haskell.
Функция timeout используется для многих целей, но ее производительность недостаточна для реализации высокопроизводительных серверов. Проблема в том, что для каждого созданного тайм-аута эта функция будет порождать новый пользовательский поток. Хотя пользовательские потоки дешевле, чем системные потоки, с ними, по-прежнему, связаны накладные расходы, которые могут суммироваться. Нам необходимо избежать создание отдельного пользовательского потока для обработки тайм-аута каждого подключения. Поэтому мы реализовали систему тайм-аутов, в которой для тайм-аутов всех соединений используется только один пользовательский поток, вызываемый менеджером тайм-аута. В сущности применены следующие две идеи:
- сдвоенная ссылка
IORef - безопасный алгоритм свопинга и слияния значений.
Предположим, что статус соединений описывается как Active и Inactive. Чтобы очистить неактивные подключения, менеджер ожидания периодически проверяет состояние каждого подключения. Если статус - Active, менеджер тайм-аута переводит его в Inactive. Если статус - Inactive, менеджер тайм-аута уничтожает связанный с ним пользовательский поток.
Ссылка на статус делается с помощью IORef. IORef является ссылкой, значение которой может деструктивно обновляться. В добавок к менеджеру тайм-аута, каждый пользовательский поток по мере того, пока поддерживается подключение, периодически устанавливает свой статус в Active через собственную ссылку IORef.
Менеджер тайм-аутов использует для этих состояний список ссылок IORef. Пользовательский поток, порожденный для нового подключения, пытается добавить в этот список свою новую ссылку IORef со статусом Active. Поэтому список является критической секцией, и для, чтобы сохранить согласованность списка, нам нужно поддерживать его атомарность (atomicity).
Здесь под атомарностью имеется в виду такое свойство списка, что когда над ним выполняется некоторая операция, эта операция должны быть выполнена полностью. Частичное выполнение операции над отдельными элементами списка не допускается
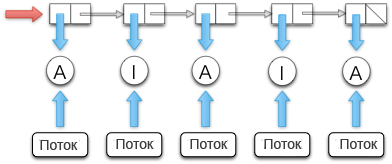
Рис.11.12: Список значений состояний, их индикация и их соответствие
Стандартным способом поддержки согласованности в языке Haskell является переменная MVar. Но переменная MVar медленная, поскольку каждая переменная MVar защищена специальной блокировкой. Вместо этого, мы воспользовались еще одной ссылкой IORef для ссылки на список, и функцией atomicModifyIORef для того, чтобы манипулировать дополнительной ссылкой. Функция atomicModifyIORef является функцией атомарного обновления значений IORef. Она реализуется через команду CAS (Compare-and-Swap — сравнил и выполнил своп/обмен значений), которая выполняется значительно быстрее, чем блокировки.
Ниже приведена общая схема безопасного алгоритм свопинга и объединения значений:
do xs <- atomicModifyIORef ref (\ys -> ([], ys)) -- swap with an empty list, [] xs' <- manipulates_status xs atomicModifyIORef ref (\ys -> (merge xs' ys, ()))
Менеджер тайм-аутов атомарно выполняет своп/обмен данных между списком и пустым списком. Затем он обновляет список, а именно переключает статус потока или удаляет ненужный статус для уже удаленного пользовательского потока. Во время этого процесса, могут быть созданы новые подключения и значения их состояний вставляются с помощью функции atomicModifyIORef, вызываемой из соответствующего пользовательского потока. Затем менеджер тайм-аутов атомарно объединяет обработанный список и новый список. Благодаря ленивому выполнению, используемому в языке Haskell, применение функции слияния выполняется за время O(1), а операция объединения, которая выполняется за время O(N), откладывается до тех пор, эти значения действительно не потребуются.
Таймеры дескрипторов файлов
Рассмотрим случай, когда Warp отправляет весь файл с помощью команды sendfile(). Для того, чтобы узнать размер файла, нам, к сожалению, нужно вызывать команду stat(), т. к. команда sendfile() в Linux требует, чтобы вызывающий указывал, какое количество байтов должно быть послано (в команде sendfile() во FreeBSD/MacOS есть магическое число 0, указывающие конец файла).
Если приложения WAI знает размер файла, то Warp может избежать использование команды stat(). Для приложений WAI проще кэшировать информацию о файла, такую как размер файла и время его модификации. Если тайм-аут кэша достаточен (скажем, 10 секунд), риск несостоятельности данных, находящихся в кэше, не серьезен. Так что мы можем безопасно очистить кэш и не беспокоиться об утечке памяти.
Поскольку в команде sendfile() нужен дескриптор файла, то типичной последовательностью команд для отправки файла будет следующей - open(), sendfile(), которая повторяется, если это необходимо, и close(). В этом подразделе мы рассмотрим, как кэшировать файловые дескрипторы для того, чтобы избежать вызов команд open() и close() большее количество раз, чем это необходимо. Кэширование файловых дескрипторов должно работать следующим образом: если клиент просит, чтобы был отправлен файл, то при помощи команды open() открывается дескриптор файла. И если вскоре после этого еще один клиент запрашивает тот же самый файл, то ранее открытый дескриптор файла используется повторно. В дальнейшем, если ни один пользовательских потоков не использует дескриптор файла, то он закрывается с помощью команды close().
Типичной тактикой для этого случая является подсчет ссылок. Мы не были уверены, что мы смогли бы реализовать надежный счетчик ссылок. Что произойдет, если пользователь поток будет закрыт по непредвиденным причинам? Если мы не сможем для него уменьшить счетчик на единицу, то произойдет утечка дескриптора файла. Мы обратили внимание, что поскольку в схеме тайм-аута подключений не используются счетчики ссылок, она достаточно безопасна с тем, чтобы ее еще использовать и как механизм кеширования файловых дескрипторов. Тем не менее, мы не можем просто воспользоваться менеджером тайм-аута по нескольким причинам.
Каждый пользовательский поток имеет свой собственный статус, причем статус не является общедоступным. Но мы хотели бы кэшировать файловые дескрипторы с тем, чтобы благодаря общему доступу избежать использования команд open() и close(). Поэтому нам нужно искать дескриптор файла для запрашиваемого файла в коллекции кэшированных файловых дескрипторов. Поскольку этот поиск должен быть быстрым, мы не должны пользоваться списком. Поскольку запросы принимаются параллельно, то для одного и того же файла могут одновременно быть отрыто два или более дескрипторов файла. Таким образом, для одного и того же имени файла нам нужно хранить несколько файловых дескрипторов. Структура данных, которую мы описываем, называется multimap.
Мы реализовали структуру multimap, которая просматривается за время O(log N), а удаление узлов в которой происходит за время O(N) для деревьев вида red-black с узлами, в которых находятся непустые списки. Поскольку дерево вида red-black является деревом бинарного поиска, то время просмотра равно O(log(N)), где N - число узлов. Мы также можем преобразовать его в упорядоченный список за время O(N). В нашей реализации на этом этапе также выполняется удаление узлов, в которых содержатся дескрипторы уже закрытых файлов. Мы используем алгоритм, который преобразует упорядоченный список в дерево вида red-black за время O(N).
Продолжение статьи: Дальнейшая работа.