Библиотека сайта rus-linux.net
Применение принципов оптимизации к средствам компонентного развертывания и конфигурирования систем
Глава 6 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Applying Optimization Principle Patterns to Component Deployment and Configuration Tools,
Авторы: Doug C. Schmidt, William R. Otte, and Aniruddha Gokhal
Перевод: Н.Ромоданов
Оптимизация за счет сокращения числа последовательно выполняемых задач при развертывании приложений
Контекст
Сложность, о которой рассказывается ниже, связана с последовательным (не параллельным) выполнением задач развертывания. Соответствующие причины задержек в DAnCE есть как на глобальном уровне, так и уровне узлов. На глобальном уровне, это отсутствие возможности распараллеливания результатов, полученных с помощью транспорта CORBA, используемого в движке DAnCE. Однако, отсутствие возможности распараллеливания на локальном уровне является результатом отсутствия конкретного соотношения терминов в определении интерфейса реализации D&C с целевой компонентной моделью, которая содержится в спецификации D&C.
Процесс развертывания D&C, который описан в разделе «Процесс развертывания компонентов OMG D&C», позволяет разделять процесс развертывания на ряд подзадач для конкретных узлов. Каждая подзадача назначается отдельным узлам при помощи единственного дистанционного вызова, причем все данные, создаваемые в узлах, возвращаются обратно через параметры "out", которые являются частью сигнатуры операции, описанной в языке IDL. Из-за синхронной (запрос/ответ) природы протокола сообщений CORBA, используемого в реализации DAnCE, традиционный подход состоит в последовательной рассылке этих подзадач на каждый узел. Этот подход прост в реализации, в отличие от сложного в использовании механизма асинхронного вызова методов CORBA (asynchronous method invocation - AMI) [34].
Проблема
Чтобы свести к минимуму первоначальную сложность реализации, мы при проектировании исходной реализации DAnCE использовали (правда, недальновидно) синхронный вызов. Такая глобальная синхронность работала замечательно для сравнительно небольших случаев развертывания с количеством компонентов менее чем 100. По мере роста числа узлов и увеличения количества экземпляров компонентов, назначаемых этим узлам, такая глобальная/локальная последовательная деятельность стала причиной существенного увеличения задержек во время развертывания компонентов.
Подобное последовательное исполнение привело в нашей примере с SEAMONSTER к проблемам, связанным со снижением производительности, т.е. для того, чтобы завершить развертывание в условиях ограниченных вычислительных ресурсах, которыми обладает аппаратура, размещенная в полевых условиях, часто требуется несколько минут. На уровне узла такая задержка может быстро стать катастрофической. В частности, даже относительно небольшое развертывание с вовлечением десятков узлов быстро увеличивает задержки развертывания системы до получаса или больше.
Однако эта проблема последовательного выполнения не ограничивается только глобальным/локальным распределением задач; она также есть в той части инфраструктуры, которая связана с конкретными узлами. В спецификации D&C не описывается, как приложение NodeApplication должно взаимодействовать с целевой компонентной моделью, например, с компонентной моделью CORBA (CORBA Component Model — CCM). Это взаимодействие считается деталями реализации.
В DAnCE архитектура D&C была реализована с помощью трех процессов так, как это показано на рис.6.3.
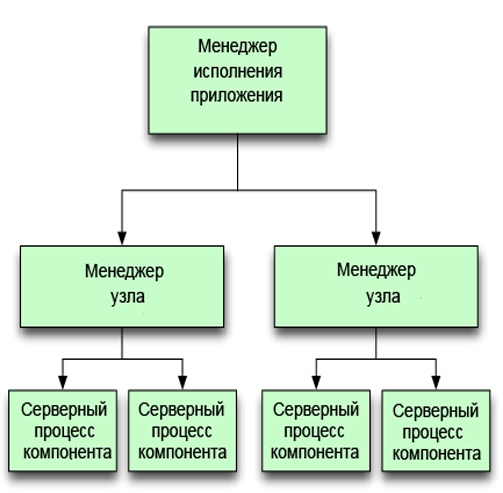
Рис.6.3: Упрощенное представление архитектуры DanCE с последовательным процессом развертывания
Процессы ExecutionManager и NodeManager в своих адресных пространствах создают ассоциированные с ними экземпляры ApplicationManager и Application. Когда для NodeApplication создаются экземпляры конкретных компонентов, то, по мере необходимости, порождается один (или более) отдельных процессов приложения. В этих процессах приложений используется интерфейс, созданный согласно более старой версии спецификации CCM, в которой разрешается, чтобы NodeApplication создавал по отдельности экземпляры компонентов и контейнеры для экземпляров. Этот подход аналогичен подходу, используемому в проекте CARDAMOM [35] (который является еще одной открытой реализацией CCM) и адаптированному для систем DRE уровня предприятия, например, систем управления воздушным движением.
Архитектура DAnCE, показанная на рисунке 6.3, имела проблемы, касающиеся распараллеливания, т. к. в этом случае в реализации NodeApplication была интегрирована непосредственно вся логика, необходимая для выполнения установки, настройки и подключения экземпляров (как это показано на рис.6.4).
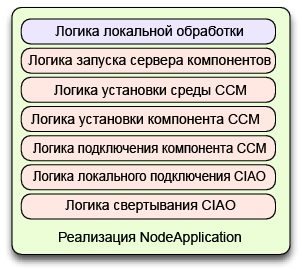
Рис.6.4: Предыдущая реализация NodeApplication в DAnCE
Хотя бы правильнее было бы выполнять лишь некоторую обработку, а оставшуюся часть логики конкретного развертывания делегировать в процесс приложения. Подобная жесткая интеграция усложняет распараллеливание процедур установки на уровне узла по следующим причинам:
- Объем данных, совместно используемой логикой общего развертывания (часть реализации NodeApplication, в которой происходит интерпретация плана) и логикой конкретного развертывания (часть, в которой содержится конкретная информация о том, как управлять компонентами), делает сложной распараллеливание при установке этих данных в контексте единого сервера компонент, т. к. эти данные должны модифицироваться в процессе установки.
- Группы компонентов, установленные в процессах отдельных приложений, рассматривались как отдельные подзадачи развертывания, поэтому подобные группы обрабатывались последовательно одна за другой.
Продолжение статьи: Принципы оптимизации, используемые для сокращения фазы последовательного анализа.