Библиотека сайта rus-linux.net
|
|
|

|
Linux Device Drivers, 2nd EditionBy Alessandro Rubini & Jonathan Corbet2nd Edition June 2001 0-59600-008-1, Order Number: 0081 586 pages, $39.95 |
Chapter 5
Enhanced Char Driver OperationsContents:
ioctl
Blocking I/O
poll and select
Asynchronous Notification
Seeking a Device
Access Control on a Device File
Backward Compatibility
Quick ReferenceIn Chapter 3, "Char Drivers", we built a complete device driver that the user can write to and read from. But a real device usually offers more functionality than synchronous read and write. Now that we're equipped with debugging tools should something go awry, we can safely go ahead and implement new operations.
What is normally needed, in addition to reading and writing the device, is the ability to perform various types of hardware control via the device driver. Control operations are usually supported via the ioctl method. The alternative is to look at the data flow being written to the device and use special sequences as control commands. This latter technique should be avoided because it requires reserving some characters for controlling purposes; thus, the data flow can't contain those characters. Moreover, this technique turns out to be more complex to handle than ioctl. Nonetheless, sometimes it's a useful approach to device control and is used by tty's and other devices. We'll describe it later in this chapter in "Device Control Without ioctl".
ioctl
The ioctl function call in user space corresponds to the following prototype:
int ioctl(int fd, int cmd, ...);The ioctl driver method, on the other hand, receives its arguments according to this declaration:
int (*ioctl) (struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg);Choosing the ioctl Commands
Before writing the code for ioctl, you need to choose the numbers that correspond to commands. Unfortunately, the simple choice of using small numbers starting from 1 and going up doesn't work well.
To help programmers create unique ioctl command codes, these codes have been split up into several bitfields. The first versions of Linux used 16-bit numbers: the top eight were the "magic'' number associated with the device, and the bottom eight were a sequential number, unique within the device. This happened because Linus was "clueless'' (his own word); a better division of bitfields was conceived only later. Unfortunately, quite a few drivers still use the old convention. They have to: changing the command codes would break no end of binary programs. In our sources, however, we will use the new command code convention exclusively.
To choose ioctl numbers for your driver according to the new convention, you should first check include/asm/ioctl.h and Documentation/ioctl-number.txt. The header defines the bitfields you will be using: type (magic number), ordinal number, direction of transfer, and size of argument. The ioctl-number.txt file lists the magic numbers used throughout the kernel, so you'll be able to choose your own magic number and avoid overlaps. The text file also lists the reasons why the convention should be used.
#define SCULL_IOCTL1 0x6b01 #define SCULL_IOCTL2 0x6b02 /* .... */
type
numberThe ordinal (sequential) number. It's eight bits (
_IOC_NRBITS) wide.
directionThe direction of data transfer, if the particular command involves a data transfer. The possible values are
_IOC_NONE(no data transfer),_IOC_READ,_IOC_WRITE, and_IOC_READ | _IOC_WRITE(data is transferred both ways). Data transfer is seen from the application's point of view;_IOC_READmeans reading fromthe device, so the driver must write to user space. Note that the field is a bit mask, so_IOC_READand_IOC_WRITEcan be extracted using a logical AND operation.
size
The header file
<asm/ioctl.h>, which is included by<linux/ioctl.h>, defines macros that help set up the command numbers as follows:_IO(type,nr),_IOR(type,nr,dataitem),_IOW(type,nr,dataitem), and_IOWR(type,nr,dataitem). Each macro corresponds to one of the possible values for the direction of the transfer. Thetypeandnumberfields are passed as arguments, and thesizefield is derived by applying sizeof to thedataitemargument. The header also defines macros to decode the numbers:_IOC_DIR(nr),_IOC_TYPE(nr),_IOC_NR(nr), and_IOC_SIZE(nr). We won't go into any more detail about these macros because the header file is clear, and sample code is shown later in this section./* Use 'k' as magic number */ #define SCULL_IOC_MAGIC 'k' #define SCULL_IOCRESET _IO(SCULL_IOC_MAGIC, 0) /* * S means "Set" through a ptr * T means "Tell" directly with the argument value * G means "Get": reply by setting through a pointer * Q means "Query": response is on the return value * X means "eXchange": G and S atomically * H means "sHift": T and Q atomically */ #define SCULL_IOCSQUANTUM _IOW(SCULL_IOC_MAGIC, 1, scull_quantum) #define SCULL_IOCSQSET _IOW(SCULL_IOC_MAGIC, 2, scull_qset) #define SCULL_IOCTQUANTUM _IO(SCULL_IOC_MAGIC, 3) #define SCULL_IOCTQSET _IO(SCULL_IOC_MAGIC, 4) #define SCULL_IOCGQUANTUM _IOR(SCULL_IOC_MAGIC, 5, scull_quantum) #define SCULL_IOCGQSET _IOR(SCULL_IOC_MAGIC, 6, scull_qset) #define SCULL_IOCQQUANTUM _IO(SCULL_IOC_MAGIC, 7) #define SCULL_IOCQQSET _IO(SCULL_IOC_MAGIC, 8) #define SCULL_IOCXQUANTUM _IOWR(SCULL_IOC_MAGIC, 9, scull_quantum) #define SCULL_IOCXQSET _IOWR(SCULL_IOC_MAGIC,10, scull_qset) #define SCULL_IOCHQUANTUM _IO(SCULL_IOC_MAGIC, 11) #define SCULL_IOCHQSET _IO(SCULL_IOC_MAGIC, 12) #define SCULL_IOCHARDRESET _IO(SCULL_IOC_MAGIC, 15) /* debugging tool */ #define SCULL_IOC_MAXNR 15The value of the ioctl
cmdargument is not currently used by the kernel, and it's quite unlikely it will be in the future. Therefore, you could, if you were feeling lazy, avoid the complex declarations shown earlier and explicitly declare a set of scalar numbers. On the other hand, if you did, you wouldn't benefit from using the bitfields. The header<linux/kd.h>is an example of this old-fashioned approach, using 16-bit scalar values to define the ioctl commands. That source file relied on scalar numbers because it used the technology then available, not out of laziness. Changing it now would be a gratuitous incompatibility.The Return Value
The Predefined Commands
Though the ioctl system call is most often used to act on devices, a few commands are recognized by the kernel. Note that these commands, when applied to your device, are decoded before your own file operations are called. Thus, if you choose the same number for one of your ioctl commands, you won't ever see any request for that command, and the application will get something unexpected because of the conflict between the ioctlnumbers.
The predefined commands are divided into three groups:
The following ioctl commands are predefined for any file:
FIOCLEX
FIONCLEX
FIOASYNC
FIONBIO"File IOctl Non-Blocking I/O'' (described later in this chapter in "Blocking and Nonblocking Operations"). This call modifies the
O_NONBLOCKflag infilp->f_flags. The third argument to the system call is used to indicate whether the flag is to be set or cleared. We'll look at the role of the flag later in this chapter. Note that the flag can also be changed by the fcntl system call, using the F_SETFL command.
Using the ioctl Argument
Address verification for kernels 2.2.x and beyond is implemented by the function access_ok, which is declared in
<asm/uaccess.h>:int access_ok(int type, const void *addr, unsigned long size);int err = 0, tmp; int ret = 0; /* * extract the type and number bitfields, and don't decode * wrong cmds: return ENOTTY (inappropriate ioctl) before access_ok() */ if (_IOC_TYPE(cmd) != SCULL_IOC_MAGIC) return -ENOTTY; if (_IOC_NR(cmd) > SCULL_IOC_MAXNR) return -ENOTTY; /* * the direction is a bitmask, and VERIFY_WRITE catches R/W * transfers. `Type' is user oriented, while * access_ok is kernel oriented, so the concept of "read" and * "write" is reversed */ if (_IOC_DIR(cmd) & _IOC_READ) err = !access_ok(VERIFY_WRITE, (void *)arg, _IOC_SIZE(cmd)); else if (_IOC_DIR(cmd) & _IOC_WRITE) err = !access_ok(VERIFY_READ, (void *)arg, _IOC_SIZE(cmd)); if (err) return -EFAULT;
put_user(datum, ptr)__put_user(datum, ptr)These macros write the datum to user space; they are relatively fast, and should be called instead of copy_to_userwhenever single values are being transferred. Since type checking is not performed on macro expansion, you can pass any type of pointer to put_user, as long as it is a user-space address. The size of the data transfer depends on the type of the
ptrargument and is determined at compile time using a special gcc pseudo-function that isn't worth showing here. As a result, ifptris a char pointer, one byte is transferred, and so on for two, four, and possibly eight bytes.
get_user(local, ptr)__get_user(local, ptr)These macros are used to retrieve a single datum from user space. They behave like put_user and __put_user, but transfer data in the opposite direction. The value retrieved is stored in the local variable
local; the return value indicates whether the operation succeeded or not. Again, __get_user should only be used if the address has already been verified with access_ok.
Capabilities and Restricted Operations
Access to a device is controlled by the permissions on the device file(s), and the driver is not normally involved in permissions checking. There are situations, however, where any user is granted read/write permission on the device, but some other operations should be denied. For example, not all users of a tape drive should be able to set its default block size, and the ability to work with a disk device does not mean that the user can reformat the drive. In cases like these, the driver must perform additional checks to be sure that the user is capable of performing the requested operation.
The full set of capabilities can be found in
<linux/capability.h>. A subset of those capabilities that might be of interest to device driver writers includes the following:
CAP_DAC_OVERRIDEThe ability to override access restrictions on files and directories.
CAP_NET_ADMIN
CAP_SYS_MODULE
CAP_SYS_RAWIO
CAP_SYS_ADMINA catch-all capability that provides access to many system administration operations.
CAP_SYS_TTY_CONFIG
Before performing a privileged operation, a device driver should check that the calling process has the appropriate capability with the capable function (defined in
<sys/sched.h>):int capable(int capability);if (! capable (CAP_SYS_ADMIN)) return -EPERM;In the absence of a more specific capability for this task,
CAP_SYS_ADMINwas chosen for this test.The Implementation of the ioctl Commands
switch(cmd) { #ifdef SCULL_DEBUG case SCULL_IOCHARDRESET: /* * reset the counter to 1, to allow unloading in case * of problems. Use 1, not 0, because the invoking * process has the device open. */ while (MOD_IN_USE) MOD_DEC_USE_COUNT; MOD_INC_USE_COUNT; /* don't break: fall through and reset things */ #endif /* SCULL_DEBUG */ case SCULL_IOCRESET: scull_quantum = SCULL_QUANTUM; scull_qset = SCULL_QSET; break; case SCULL_IOCSQUANTUM: /* Set: arg points to the value */ if (! capable (CAP_SYS_ADMIN)) return -EPERM; ret = __get_user(scull_quantum, (int *)arg); break; case SCULL_IOCTQUANTUM: /* Tell: arg is the value */ if (! capable (CAP_SYS_ADMIN)) return -EPERM; scull_quantum = arg; break; case SCULL_IOCGQUANTUM: /* Get: arg is pointer to result */ ret = __put_user(scull_quantum, (int *)arg); break; case SCULL_IOCQQUANTUM: /* Query: return it (it's positive) */ return scull_quantum; case SCULL_IOCXQUANTUM: /* eXchange: use arg as pointer */ if (! capable (CAP_SYS_ADMIN)) return -EPERM; tmp = scull_quantum; ret = __get_user(scull_quantum, (int *)arg); if (ret == 0) ret = __put_user(tmp, (int *)arg); break; case SCULL_IOCHQUANTUM: /* sHift: like Tell + Query */ if (! capable (CAP_SYS_ADMIN)) return -EPERM; tmp = scull_quantum; scull_quantum = arg; return tmp; default: /* redundant, as cmd was checked against MAXNR */ return -ENOTTY; } return ret;int quantum; ioctl(fd,SCULL_IOCSQUANTUM, &quantum); ioctl(fd,SCULL_IOCTQUANTUM, quantum); ioctl(fd,SCULL_IOCGQUANTUM, &quantum); quantum = ioctl(fd,SCULL_IOCQQUANTUM); ioctl(fd,SCULL_IOCXQUANTUM, &quantum); quantum = ioctl(fd,SCULL_IOCHQUANTUM, quantum);Of course, a normal driver would not implement such a mix of calling modes in one place. We have done so here only to demonstrate the different ways in which things could be done. Normally, however, data exchanges would be consistently performed, either through pointers (more common) or by value (less common), and mixing of the two techniques would be avoided.
Device Control Without ioctl
Sometimes controlling the device is better accomplished by writing control sequences to the device itself. This technique is used, for example, in the console driver, where so-called escape sequences are used to move the cursor, change the default color, or perform other configuration tasks. The benefit of implementing device control this way is that the user can control the device just by writing data, without needing to use (or sometimes write) programs built just for configuring the device.
The drawback of controlling by printing is that it adds policy constraints to the device; for example, it is viable only if you are sure that the control sequence can't appear in the data being written to the device during normal operation. This is only partly true for ttys. Although a text display is meant to display only ASCII characters, sometimes control characters can slip through in the data being written and can thus affect the console setup. This can happen, for example, when you issue grep on a binary file; the extracted lines can contain anything, and you often end up with the wrong font on your console.[25]
Blocking I/O
One problem that might arise with read is what to do when there's no data yet, but we're not at end-of-file.
As usual, before we show actual code, we'll explain a few concepts.
Going to Sleep and Awakening
Whenever a process must wait for an event (such as the arrival of data or the termination of a process), it should go to sleep. Sleeping causes the process to suspend execution, freeing the processor for other uses. At some future time, when the event being waited for occurs, the process will be woken up and will continue with its job. This section discusses the 2.4 machinery for putting a process to sleep and waking it up. Earlier versions are discussed in "Backward Compatibility" later in this chapter.
wait_queue_head_t my_queue; init_waitqueue_head (&my_queue);DECLARE_WAIT_QUEUE_HEAD (my_queue);
sleep_on(wait_queue_head_t *queue);
interruptible_sleep_on(wait_queue_head_t *queue);
sleep_on_timeout(wait_queue_head_t *queue, long timeout);interruptible_sleep_on_timeout(wait_queue_head_t *queue, long timeout);These two functions behave like the previous two, with the exception that the sleep will last no longer than the given timeout period. The timeout is specified in "jiffies,'' which are covered in Chapter 6, "Flow of Time".
void wait_event(wait_queue_head_t queue, int condition);int wait_event_interruptible(wait_queue_head_t queue, int condition);These macros are the preferred way to sleep on an event. They combine waiting for an event and testing for its arrival in a way that avoids race conditions. They will sleep until the condition, which may be any boolean C expression, evaluates true. The macros expand to a while loop, and the condition is reevaluated over time -- the behavior is different from that of a function call or a simple macro, where the arguments are evaluated only at call time. The latter macro is implemented as an expression that evaluates to 0 in case of success and
-ERESTARTSYSif the loop is interrupted by a signal.
Of course, sleeping is only half of the problem; something, somewhere will have to wake the process up again. When a device driver sleeps directly, there is usually code in another part of the driver that performs the wakeup, once it knows that the event has occurred. Typically a driver will wake up sleepers in its interrupt handler once new data has arrived. Other scenarios are possible, however.
wake_up(wait_queue_head_t *queue);This function will wake up all processes that are waiting on this event queue.
wake_up_interruptible(wait_queue_head_t *queue);
wake_up_sync(wait_queue_head_t *queue);wake_up_interruptible_sync(wait_queue_head_t *queue);Normally, a wake_up call can cause an immediate reschedule to happen, meaning that other processes might run before wake_up returns. The "synchronous" variants instead make any awakened processes runnable, but do not reschedule the CPU. This is used to avoid rescheduling when the current process is known to be going to sleep, thus forcing a reschedule anyway. Note that awakened processes could run immediately on a different processor, so these functions should not be expected to provide mutual exclusion.
DECLARE_WAIT_QUEUE_HEAD(wq); ssize_t sleepy_read (struct file *filp, char *buf, size_t count, loff_t *pos) { printk(KERN_DEBUG "process %i (%s) going to sleep\n", current->pid, current->comm); interruptible_sleep_on(&wq); printk(KERN_DEBUG "awoken %i (%s)\n", current->pid, current->comm); return 0; /* EOF */ } ssize_t sleepy_write (struct file *filp, const char *buf, size_t count, loff_t *pos) { printk(KERN_DEBUG "process %i (%s) awakening the readers...\n", current->pid, current->comm); wake_up_interruptible(&wq); return count; /* succeed, to avoid retrial */ }A Deeper Look at Wait Queues
The
wait_queue_head_ttype is a fairly simple structure, defined in<linux/wait.h>. It contains only a lock variable and a linked list of sleeping processes. The individual data items in the list are of typewait_queue_t, and the list is the generic list defined in<linux/list.h>and described in "Linked Lists" in Chapter 10, "Judicious Use of Data Types". Normally thewait_queue_tstructures are allocated on the stack by functions like interruptible_sleep_on; the structures end up in the stack because they are simply declared as automatic variables in the relevant functions. In general, the programmer need not deal with them.void simplified_sleep_on(wait_queue_head_t *queue) { wait_queue_t wait; init_waitqueue_entry(&wait, current); current->state = TASK_INTERRUPTIBLE; add_wait_queue(queue, &wait); schedule(); remove_wait_queue (queue, &wait); }The code here creates a new
wait_queue_tvariable (wait, which gets allocated on the stack) and initializes it. The state of the task is set toTASK_INTERRUPTIBLE, meaning that it is in an interruptible sleep. The wait queue entry is then added to the queue (thewait_queue_head_t *argument). Then schedule is called, which relinquishes the processor to somebody else. schedule returns only when somebody else has woken up the process and set its state toTASK_RUNNING. At that point, the wait queue entry is removed from the queue, and the sleep is done.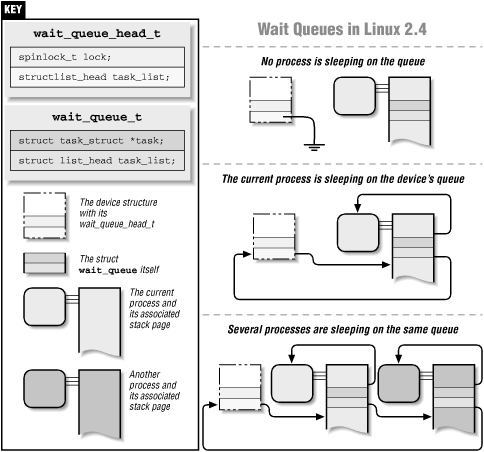
Figure 5-1. Wait queues in Linux 2.4
A quick look through the kernel shows that a great many procedures do their sleeping "manually'' with code that looks like the previous example. Most of those implementations date back to kernels prior to 2.2.3, before wait_event was introduced. As suggested, wait_event is now the preferred way to sleep on an event, because interruptible_sleep_onis subject to unpleasant race conditions. A full description of how that can happen will have to wait until "Going to Sleep Without Races" in Chapter 9, "Interrupt Handling"; the short version, simply, is that things can change in the time between when your driver decides to sleep and when it actually gets around to calling interruptible_sleep_on.
One other reason for calling the scheduler explicitly, however, is to do exclusive waits. There can be situations in which several processes are waiting on an event; when wake_up is called, all of those processes will try to execute. Suppose that the event signifies the arrival of an atomic piece of data. Only one process will be able to read that data; all the rest will simply wake up, see that no data is available, and go back to sleep.
The code to perform an exclusive sleep looks very similar to that for a regular sleep:
void simplified_sleep_exclusive(wait_queue_head_t *queue) { wait_queue_t wait; init_waitqueue_entry(&wait, current); current->state = TASK_INTERRUPTIBLE | TASK_EXCLUSIVE; add_wait_queue_exclusive(queue, &wait); schedule(); remove_wait_queue (queue, &wait); }Adding the
TASK_EXCLUSIVEflag to the task state indicates that the process is in an exclusive wait. The call to add_wait_queue_exclusive is also necessary, however. That function adds the process to the end of the wait queue, behind all others. The purpose is to leave any processes in nonexclusive sleeps at the beginning, where they will always be awakened. As soon as wake_up hits the first exclusive sleeper, it knows it can stop.Those wanting to dig even deeper into the wait queue code can look at
<linux/sched.h>andkernel/sched.c.Writing Reentrant Code
When a process is put to sleep, the driver is still alive and can be called by another process. Let's consider the console driver as an example. While an application is waiting for keyboard input on
tty1, the user switches totty2and spawns a new shell. Now both shells are waiting for keyboard input within the console driver, although they sleep on different wait queues: one on the queue associated withtty1and the other on the queue associated withtty2. Each process is blocked within the interruptible_sleep_on function, but the driver can still receive and answer requests from other ttys.You need to make reentrant any function that matches either of two conditions. First, if it calls schedule, possibly by calling sleep_on or wake_up. Second, if it copies data to or from user space, because access to user space might page-fault, and the process will be put to sleep while the kernel deals with the missing page. Every function that calls any such functions must be reentrant as well. For example, if sample_read calls sample_getdata, which in turn can block, then sample_read must be reentrant as well as sample_getdata, because nothing prevents another process from calling it while it is already executing on behalf of a process that went to sleep.
Finally, of course, code that sleeps should always keep in mind that the state of the system can change in almost any way while a process is sleeping. The driver should be careful to check any aspect of its environment that might have changed while it wasn't paying attention.
Blocking and Nonblocking Operations
Another point we need to touch on before we look at the implementation of full-featured read and write methods is the role of the
O_NONBLOCKflag infilp->f_flags. The flag is defined in<linux/fcntl.h>, which is automatically included by<linux/fs.h>.
Both these statements assume that there are both input and output buffers; in practice, almost every device driver has them. The input buffer is required to avoid losing data that arrives when nobody is reading. In contrast, data can't be lost on write, because if the system call doesn't accept data bytes, they remain in the user-space buffer. Even so, the output buffer is almost always useful for squeezing more performance out of the hardware.
The performance gain of implementing an output buffer in the driver results from the reduced number of context switches and user-level/kernel-level transitions. Without an output buffer (assuming a slow device), only one or a few characters are accepted by each system call, and while one process sleeps in write, another process runs (that's one context switch). When the first process is awakened, it resumes (another context switch), write returns (kernel/user transition), and the process reiterates the system call to write more data (user/kernel transition); the call blocks, and the loop continues. If the output buffer is big enough, the write call succeeds on the first attempt -- the buffered data will be pushed out to the device later, at interrupt time -- without control needing to go back to user space for a second or third write call. The choice of a suitable size for the output buffer is clearly device specific.
Only the read, write, and open file operations are affected by the nonblocking flag.
A Sample Implementation: scullpipe
typedef struct Scull_Pipe { wait_queue_head_t inq, outq; /* read and write queues */ char *buffer, *end; /* begin of buf, end of buf */ int buffersize; /* used in pointer arithmetic */ char *rp, *wp; /* where to read, where to write */ int nreaders, nwriters; /* number of openings for r/w */ struct fasync_struct *async_queue; /* asynchronous readers */ struct semaphore sem; /* mutual exclusion semaphore */ devfs_handle_t handle; /* only used if devfs is there */ } Scull_Pipe;ssize_t scull_p_read (struct file *filp, char *buf, size_t count, loff_t *f_pos) { Scull_Pipe *dev = filp->private_data; if (f_pos != &filp->f_pos) return -ESPIPE; if (down_interruptible(&dev->sem)) return -ERESTARTSYS; while (dev->rp == dev->wp) { /* nothing to read */ up(&dev->sem); /* release the lock */ if (filp->f_flags & O_NONBLOCK) return -EAGAIN; PDEBUG("\"%s\" reading: going to sleep\n", current->comm); if (wait_event_interruptible(dev->inq, (dev->rp != dev->wp))) return -ERESTARTSYS; /* signal: tell the fs layer to handle it */ /* otherwise loop, but first reacquire the lock */ if (down_interruptible(&dev->sem)) return -ERESTARTSYS; } /* ok, data is there, return something */ if (dev->wp > dev->rp) count = min(count, dev->wp - dev->rp); else /* the write pointer has wrapped, return data up to dev->end */ count = min(count, dev->end - dev->rp); if (copy_to_user(buf, dev->rp, count)) { up (&dev->sem); return -EFAULT; } dev->rp += count; if (dev->rp == dev->end) dev->rp = dev->buffer; /* wrapped */ up (&dev->sem); /* finally, awaken any writers and return */ wake_up_interruptible(&dev->outq); PDEBUG("\"%s\" did read %li bytes\n",current->comm, (long)count); return count; }static inline int spacefree(Scull_Pipe *dev) { if (dev->rp == dev->wp) return dev->buffersize - 1; return ((dev->rp + dev->buffersize - dev->wp) % dev->buffersize) - 1; } ssize_t scull_p_write(struct file *filp, const char *buf, size_t count, loff_t *f_pos) { Scull_Pipe *dev = filp->private_data; if (f_pos != &filp->f_pos) return -ESPIPE; if (down_interruptible(&dev->sem)) return -ERESTARTSYS; /* Make sure there's space to write */ while (spacefree(dev) == 0) { /* full */ up(&dev->sem); if (filp->f_flags & O_NONBLOCK) return -EAGAIN; PDEBUG("\"%s\" writing: going to sleep\n",current->comm); if (wait_event_interruptible(dev->outq, spacefree(dev) > 0)) return -ERESTARTSYS; /* signal: tell the fs layer to handle it */ if (down_interruptible(&dev->sem)) return -ERESTARTSYS; } /* ok, space is there, accept something */ count = min(count, spacefree(dev)); if (dev->wp >= dev->rp) count = min(count, dev->end - dev->wp); /* up to end-of-buffer */ else /* the write pointer has wrapped, fill up to rp-1 */ count = min(count, dev->rp - dev->wp - 1); PDEBUG("Going to accept %li bytes to %p from %p\n", (long)count, dev->wp, buf); if (copy_from_user(dev->wp, buf, count)) { up (&dev->sem); return -EFAULT; } dev->wp += count; if (dev->wp == dev->end) dev->wp = dev->buffer; /* wrapped */ up(&dev->sem); /* finally, awaken any reader */ wake_up_interruptible(&dev->inq); /* blocked in read() and select() */ /* and signal asynchronous readers, explained later in Chapter 5 */ if (dev->async_queue) kill_fasync(&dev->async_queue, SIGIO, POLL_IN); PDEBUG("\"%s\" did write %li bytes\n",current->comm, (long)count); return count; }To test the blocking operation of the scullpipe device, you can run some programs on it, using input/output redirection as usual. Testing nonblocking activity is trickier, because the conventional programs don't perform nonblocking operations. The misc-progs source directory contains the following simple program, called nbtest, for testing nonblocking operations. All it does is copy its input to its output, using nonblocking I/O and delaying between retrials. The delay time is passed on the command line and is one second by default.
int main(int argc, char **argv) { int delay=1, n, m=0; if (argc>1) delay=atoi(argv[1]); fcntl(0, F_SETFL, fcntl(0,F_GETFL) | O_NONBLOCK); /* stdin */ fcntl(1, F_SETFL, fcntl(1,F_GETFL) | O_NONBLOCK); /* stdout */ while (1) { n=read(0, buffer, 4096); if (n>=0) m=write(1, buffer, n); if ((n<0 || m<0) && (errno != EAGAIN)) break; sleep(delay); } perror( n<0 ? "stdin" : "stdout"); exit(1); }poll and select
Applications that use nonblocking I/O often use the poll and select system calls as well. poll and selecthave essentially the same functionality: both allow a process to determine whether it can read from or write to one or more open files without blocking. They are thus often used in applications that must use multiple input or output streams without blocking on any one of them. The same functionality is offered by two separate functions because they were implemented in Unix almost at the same time by two different groups: select was introduced in BSD Unix, whereas poll was the System V solution.
unsigned int (*poll) (struct file *, poll_table *);
Call poll_wait on one or more wait queues that could indicate a change in the poll status.
Return a bit mask describing operations that could be immediately performed without blocking.
The
poll_tablestructure, the second argument to the poll method, is used within the kernel to implement the poll and select calls; it is declared in<linux/poll.h>, which must be included by the driver source. Driver writers need know nothing about its internals and must use it as an opaque object; it is passed to the driver method so that every event queue that could wake up the process and change the status of the poll operation can be added to thepoll_tablestructure by calling the function poll_wait:void poll_wait (struct file *, wait_queue_head_t *, poll_table *);
POLLINThis bit must be set if the device can be read without blocking.
POLLRDNORM
POLLRDBAND
POLLPRI
POLLHUP
POLLERR
POLLOUTThis bit is set in the return value if the device can be written to without blocking.
POLLWRNORM
POLLWRBAND
unsigned int scull_p_poll(struct file *filp, poll_table *wait) { Scull_Pipe *dev = filp->private_data; unsigned int mask = 0; /* * The buffer is circular; it is considered full * if "wp" is right behind "rp". "left" is 0 if the * buffer is empty, and it is "1" if it is completely full. */ int left = (dev->rp + dev->buffersize - dev->wp) % dev->buffersize; poll_wait(filp, &dev->inq, wait); poll_wait(filp, &dev->outq, wait); if (dev->rp != dev->wp) mask |= POLLIN | POLLRDNORM; /* readable */ if (left != 1) mask |= POLLOUT | POLLWRNORM; /* writable */ return mask; }With real FIFOs, for example, the reader sees an end-of-file when all the writers close the file, whereas in scullpipe the reader never sees end-of-file. The behavior is different because a FIFO is intended to be a communication channel between two processes, while scullpipe is a trashcan where everyone can put data as long as there's at least one reader. Moreover, it makes no sense to reimplement what is already available in the kernel.
Interaction with read and write
Reading data from the device
If there is data in the input buffer, the readcall should return immediately, with no noticeable delay, even if less data is available than the application requested and the driver is sure the remaining data will arrive soon. You can always return less data than you're asked for if this is convenient for any reason (we did it in scull), provided you return at least one byte.
Writing to the device
If there is space in the output buffer, writeshould return without delay. It can accept less data than the call requested, but it must accept at least one byte. In this case, poll reports that the device is writable.
Flushing pending output
We've seen how the write method by itself doesn't account for all data output needs. The fsyncfunction, invoked by the system call of the same name, fills the gap. This method's prototype is
int (*fsync) (struct file *file, struct dentry *dentry, int datasync);The Underlying Data Structure
The actual implementation of the poll and select system calls is reasonably simple, for those who are interested in how it works. Whenever a user application calls either function, the kernel invokes the poll method of all files referenced by the system call, passing the same
poll_tableto each of them. The structure is, for all practical purposes, an array ofpoll_table_entrystructures allocated for a specific poll or selectcall. Eachpoll_table_entrycontains thestruct filepointer for the open device, await_queue_head_tpointer, and await_queue_tentry. When a driver calls poll_wait, one of these entries gets filled in with the information provided by the driver, and the wait queue entry gets put onto the driver's queue. The pointer towait_queue_head_tis used to track the wait queue where the current poll table entry is registered, in order for free_wait to be able to dequeue the entry before the wait queue is awakened.We tried to show the data structures involved in polling in Figure 5-2; the figure is a simplified representation of the real data structures because it ignores the multipage nature of a poll table and disregards the file pointer that is part of each
poll_table_entry. The reader interested in the actual implementation is urged to look in<linux/poll.h>and fs/select.c.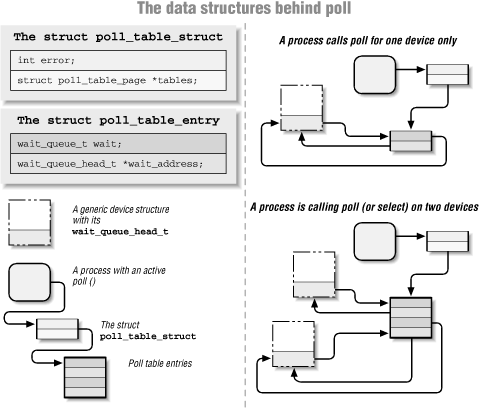
Figure 5-2. The data structures of poll
Asynchronous Notification
Though the combination of blocking and nonblocking operations and the select method are sufficient for querying the device most of the time, some situations aren't efficiently managed by the techniques we've seen so far.
User programs have to execute two steps to enable asynchronous notification from an input file. First, they specify a process as the "owner'' of the file. When a process invokes the
F_SETOWNcommand using the fcntl system call, the process ID of the owner process is saved infilp->f_ownerfor later use. This step is necessary for the kernel to know just who to notify. In order to actually enable asynchronous notification, the user programs must set theFASYNCflag in the device by means of theF_SETFLfcntlcommand.signal(SIGIO, &input_handler); /* dummy sample; sigaction() is better */ fcntl(STDIN_FILENO, F_SETOWN, getpid()); oflags = fcntl(STDIN_FILENO, F_GETFL); fcntl(STDIN_FILENO, F_SETFL, oflags | FASYNC);The Driver's Point of View
A more relevant topic for us is how the device driver can implement asynchronous signaling. The following list details the sequence of operations from the kernel's point of view:
When
F_SETOWNis invoked, nothing happens, except that a value is assigned tofilp->f_owner.
When
F_SETFLis executed to turn onFASYNC, the driver's fasyncmethod is called. This method is called whenever the value ofFASYNCis changed infilp->f_flags, to notify the driver of the change so it can respond properly. The flag is cleared by default when the file is opened. We'll look at the standard implementation of the driver method soon.
The general implementation offered by Linux is based on one data structure and two functions (which are called in the second and third steps described earlier). The header that declares related material is
<linux/fs.h>-- nothing new here -- and the data structure is calledstruct fasync_struct. As we did with wait queues, we need to insert a pointer to the structure in the device-specific data structure. Actually, we've already seen such a field in the section "A Sample Implementation: scullpipe".The two functions that the driver calls correspond to the following prototypes:
int fasync_helper(int fd, struct file *filp, int mode, struct fasync_struct **fa); void kill_fasync(struct fasync_struct **fa, int sig, int band);Here's how scullpipe implements the fasync method:
int scull_p_fasync(fasync_file fd, struct file *filp, int mode) { Scull_Pipe *dev = filp->private_data; return fasync_helper(fd, filp, mode, &dev->async_queue); }if (dev->async_queue) kill_fasync(&dev->async_queue, SIGIO, POLL_IN);/* remove this filp from the asynchronously notified filp's */ scull_p_fasync(-1, filp, 0);The data structure underlying asynchronous notification is almost identical to the structure
struct wait_queue, because both situations involve waiting on an event. The difference is thatstruct fileis used in place ofstruct task_struct. Thestruct filein the queue is then used to retrievef_owner, in order to signal the process.Seeking a Device
The difficult part of the chapter is over; now we'll quickly detail the llseek method, which is useful and easy to implement.
The llseek Implementation
The llseek method implements the lseek and llseek system calls. We have already stated that if the llseekmethod is missing from the device's operations, the default implementation in the kernel performs seeks from the beginning of the file and from the current position by modifying
filp->f_pos, the current reading/writing position within the file. Please note that for the lseek system call to work correctly, the read and write methods must cooperate by updating the offset item they receive as argument (the argument is usually a pointer tofilp->f_pos).loff_t scull_llseek(struct file *filp, loff_t off, int whence) { Scull_Dev *dev = filp->private_data; loff_t newpos; switch(whence) { case 0: /* SEEK_SET */ newpos = off; break; case 1: /* SEEK_CUR */ newpos = filp->f_pos + off; break; case 2: /* SEEK_END */ newpos = dev->size + off; break; default: /* can't happen */ return -EINVAL; } if (newpos<0) return -EINVAL; filp->f_pos = newpos; return newpos; }loff_t scull_p_llseek(struct file *filp, loff_t off, int whence) { return -ESPIPE; /* unseekable */ }It's interesting to note that since pread and pwrite have been added to the set of supported system calls, the lseek device method is not the only way a user-space program can seek a file. A proper implementation of unseekable devices should allow normal readand write calls while preventing pread and pwrite. This is accomplished by the following line -- the first in both the read and write methods of scullpipe -- we didn't explain when introducing those methods:
if (f_pos != &filp->f_pos) return -ESPIPE;Access Control on a Device File
Offering access control is sometimes vital for the reliability of a device node. Not only should unauthorized users not be permitted to use the device (a restriction is enforced by the filesystem permission bits), but sometimes only one authorized user should be allowed to open the device at a time.
Single-Open Devices
The brute-force way to provide access control is to permit a device to be opened by only one process at a time (single openness). This technique is best avoided because it inhibits user ingenuity. A user might well want to run different processes on the same device, one reading status information while the other is writing data. In some cases, users can get a lot done by running a few simple programs through a shell script, as long as they can access the device concurrently. In other words, implementing a single-open behavior amounts to creating policy, which may get in the way of what your users want to do.
The open call refuses access based on a global integer flag:
int scull_s_open(struct inode *inode, struct file *filp) { Scull_Dev *dev = &scull_s_device; /* device information */ int num = NUM(inode->i_rdev); if (!filp->private_data && num > 0) return -ENODEV; /* not devfs: allow 1 device only */ spin_lock(&scull_s_lock); if (scull_s_count) { spin_unlock(&scull_s_lock); return -EBUSY; /* already open */ } scull_s_count++; spin_unlock(&scull_s_lock); /* then, everything else is copied from the bare scull device */ if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) scull_trim(dev); if (!filp->private_data) filp->private_data = dev; MOD_INC_USE_COUNT; return 0; /* success */ }The close call, on the other hand, marks the device as no longer busy.
int scull_s_release(struct inode *inode, struct file *filp) { scull_s_count--; /* release the device */ MOD_DEC_USE_COUNT; return 0; }Another Digression into Race Conditions
Consider once again the test on the variable
scull_s_countjust shown. Two separate actions are taken there: (1) the value of the variable is tested, and the open is refused if it is not 0, and (2) the variable is incremented to mark the device as taken. On a single-processor system, these tests are safe because no other process will be able to run between the two actions.Instead, scullsingle uses a different locking mechanism called a spinlock. Spinlocks will never put a process to sleep. Instead, if a lock is not available, the spinlock primitives will simply retry, over and over (i.e., "spin''), until the lock is freed. Spinlocks thus have very little locking overhead, but they also have the potential to cause a processor to spin for a long time if somebody hogs the lock. Another advantage of spinlocks over semaphores is that their implementation is empty when compiling code for a uniprocessor system (where these SMP-specific races can't happen). Semaphores are a more general resource that make sense on uniprocessor computers as well as SMP, so they don't get optimized away in the uniprocessor case.
Spinlocks are declared with a type of
spinlock_t, which is defined in<linux/spinlock.h>. Prior to use, they must be initialized:spin_lock_init(spinlock_t *lock);A process entering a critical section will obtain the lock with
spin_lock:spin_lock(spinlock_t *lock);The lock is released at the end with
spin_unlock:spin_unlock(spinlock_t *lock);Restricting Access to a Single User at a Time
The next step beyond a single system-wide lock is to let a single user open a device in multiple processes but allow only one user to have the device open at a time. This solution makes it easy to test the device, since the user can read and write from several processes at once, but assumes that the user takes some responsibility for maintaining the integrity of the data during multiple accesses. This is accomplished by adding checks in the openmethod; such checks are performed after the normal permission checking and can only make access more restrictive than that specified by the owner and group permission bits. This is the same access policy as that used for ttys, but it doesn't resort to an external privileged program.
spin_lock(&scull_u_lock); if (scull_u_count && (scull_u_owner != current->uid) && /* allow user */ (scull_u_owner != current->euid) && /* allow whoever did su */ !capable(CAP_DAC_OVERRIDE)) { /* still allow root */ spin_unlock(&scull_u_lock); return -EBUSY; /* -EPERM would confuse the user */ } if (scull_u_count == 0) scull_u_owner = current->uid; /* grab it */ scull_u_count++; spin_unlock(&scull_u_lock);The code for close is not shown, since all it does is decrement the usage count.
Blocking open as an Alternative to EBUSY
When the device isn't accessible, returning an error is usually the most sensible approach, but there are situations in which you'd prefer to wait for the device.
The alternative to
EBUSY, as you may have guessed, is to implement blocking open.spin_lock(&scull_w_lock); while (scull_w_count && (scull_w_owner != current->uid) && /* allow user */ (scull_w_owner != current->euid) && /* allow whoever did su */ !capable(CAP_DAC_OVERRIDE)) { spin_unlock(&scull_w_lock); if (filp->f_flags & O_NONBLOCK) return -EAGAIN; interruptible_sleep_on(&scull_w_wait); if (signal_pending(current)) /* a signal arrived */ return -ERESTARTSYS; /* tell the fs layer to handle it */ /* else, loop */ spin_lock(&scull_w_lock); } if (scull_w_count == 0) scull_w_owner = current->uid; /* grab it */ scull_w_count++; spin_unlock(&scull_w_lock);The release method, then, is in charge of awakening any pending process:
int scull_w_release(struct inode *inode, struct file *filp) { scull_w_count--; if (scull_w_count == 0) wake_up_interruptible(&scull_w_wait); /* awaken other uid's */ MOD_DEC_USE_COUNT; return 0; }Cloning the Device on Open
Another technique to manage access control is creating different private copies of the device depending on the process opening it.
/* The clone-specific data structure includes a key field */ struct scull_listitem { Scull_Dev device; int key; struct scull_listitem *next; }; /* The list of devices, and a lock to protect it */ struct scull_listitem *scull_c_head; spinlock_t scull_c_lock; /* Look for a device or create one if missing */ static Scull_Dev *scull_c_lookfor_device(int key) { struct scull_listitem *lptr, *prev = NULL; for (lptr = scull_c_head; lptr && (lptr->key != key); lptr = lptr->next) prev=lptr; if (lptr) return &(lptr->device); /* not found */ lptr = kmalloc(sizeof(struct scull_listitem), GFP_ATOMIC); if (!lptr) return NULL; /* initialize the device */ memset(lptr, 0, sizeof(struct scull_listitem)); lptr->key = key; scull_trim(&(lptr->device)); /* initialize it */ sema_init(&(lptr->device.sem), 1); /* place it in the list */ if (prev) prev->next = lptr; else scull_c_head = lptr; return &(lptr->device); } int scull_c_open(struct inode *inode, struct file *filp) { Scull_Dev *dev; int key, num = NUM(inode->i_rdev); if (!filp->private_data && num > 0) return -ENODEV; /* not devfs: allow 1 device only */ if (!current->tty) { PDEBUG("Process \"%s\" has no ctl tty\n",current->comm); return -EINVAL; } key = MINOR(current->tty->device); /* look for a scullc device in the list */ spin_lock(&scull_c_lock); dev = scull_c_lookfor_device(key); spin_unlock(&scull_c_lock); if (!dev) return -ENOMEM; /* then, everything else is copied from the bare scull device */Here's the release implementation for /dev/scullpriv, which closes the discussion of device methods.
int scull_c_release(struct inode *inode, struct file *filp) { /* * Nothing to do, because the device is persistent. * A `real' cloned device should be freed on last close */ MOD_DEC_USE_COUNT; return 0; }Backward Compatibility
Many parts of the device driver API covered in this chapter have changed between the major kernel releases. For those of you needing to make your driver work with Linux 2.0 or 2.2, here is a quick rundown of the differences you will encounter.
Wait Queues in Linux 2.2 and 2.0
A relatively small amount of the material in this chapter changed in the 2.3 development cycle. The one significant change is in the area of wait queues. The 2.2 kernel had a different and simpler implementation of wait queues, but it lacked some important features, such as exclusive sleeps. The new implementation of wait queues was introduced in kernel version 2.3.1.
struct wait_queue *my_queue = NULL;# define DECLARE_WAIT_QUEUE_HEAD(head) struct wait_queue *head = NULL typedef struct wait_queue *wait_queue_head_t; # define init_waitqueue_head(head) (*(head)) = NULLAsynchronous Notification
Some small changes have been made in how asynchronous notification works for both the 2.2 and 2.4 releases.
kill_fasync(struct fasync_struct *queue, int signal);Fortunately, sysdep.h takes care of the issue.
int (*fasync) (struct inode *inode, struct file *filp, int on);The fsync Method
The third argument to the fsync
file_operationsmethod (the integerdatasyncvalue) was added in the 2.3 development series, meaning that portable code will generally need to include a wrapper function for older kernels. There is a trap, however, for people trying to write portable fsync methods: at least one distributor, which will remain nameless, patched the 2.4 fsync API into its 2.2 kernel. The kernel developers usually (usually...) try to avoid making API changes within a stable series, but they have little control over what the distributors do.Access to User Space in Linux 2.0
Memory access was handled differently in the 2.0 kernels. The Linux virtual memory system was less well developed at that time, and memory access was handled a little differently. The new system was the key change that opened 2.1 development, and it brought significant improvements in performance; unfortunately, it was accompanied by yet another set of compatibility headaches for driver writers.
The functions used to access memory under Linux 2.0 were as follows:
int err = 0, tmp; /* * extract the type and number bitfields, and don't decode * wrong cmds: return ENOTTY before verify_area() */ if (_IOC_TYPE(cmd) != SCULL_IOC_MAGIC) return -ENOTTY; if (_IOC_NR(cmd) > SCULL_IOC_MAXNR) return -ENOTTY; /* * the direction is a bit mask, and VERIFY_WRITE catches R/W * transfers. `Type' is user oriented, while * verify_area is kernel oriented, so the concept of "read" and * "write" is reversed */ if (_IOC_DIR(cmd) & _IOC_READ) err = verify_area(VERIFY_WRITE, (void *)arg, _IOC_SIZE(cmd)); else if (_IOC_DIR(cmd) & _IOC_WRITE) err = verify_area(VERIFY_READ, (void *)arg, _IOC_SIZE(cmd)); if (err) return err;Then get_user and put_usercan be used as follows:
case SCULL_IOCXQUANTUM: /* eXchange: use arg as pointer */ tmp = scull_quantum; scull_quantum = get_user((int *)arg); put_user(tmp, (int *)arg); break; default: /* redundant, as cmd was checked against MAXNR */ return -ENOTTY; } return 0;One possible solution is to define a new set of version-independent macros. The path taken by sysdep.h consists in defining upper-case macros:
GET_USER,__GET_USER, and so on. The arguments are the same as with the kernel macros of Linux 2.4, but the caller must be sure that verify_area has been called first (because that call is needed when compiling for 2.0).Capabilities in 2.0
The 2.0 kernel did not support the capabilities abstraction at all. All permissions checks simply looked to see if the calling process was running as the superuser; if so, the operation would be allowed. The function suser was used for this purpose; it takes no arguments and returns a nonzero value if the process has superuser privileges.
# define capable(anything) suser()The Linux 2.0 select Method
The 2.0 kernel did not support the poll system call; only the BSD-style select call was available. The corresponding device driver method was thus called select, and operated in a slightly different way, though the actions to be performed are almost identical.
#ifdef __USE_OLD_SELECT__ int scull_p_poll(struct inode *inode, struct file *filp, int mode, select_table *table) { Scull_Pipe *dev = filp->private_data; if (mode == SEL_IN) { if (dev->rp != dev->wp) return 1; /* readable */ PDEBUG("Waiting to read\n"); select_wait(&dev->inq, table); /* wait for data */ return 0; } if (mode == SEL_OUT) { /* * The buffer is circular; it is considered full * if "wp" is right behind "rp". "left" is 0 if the * buffer is empty, and it is "1" if it is completely full. */ int left = (dev->rp + dev->buffersize - dev->wp) % dev->buffersize; if (left != 1) return 1; /* writable */ PDEBUG("Waiting to write\n"); select_wait(&dev->outq, table); /* wait for free space */ return 0; } return 0; /* never exception-able */ } #else /* Use poll instead, already shown */Seeking in Linux 2.0
Prior to Linux 2.1, the llseek device method was called lseek instead, and it received different parameters from the current implementation. For that reason, under Linux 2.0 you were not allowed to seek a file, or a device, past the 2 GB limit, even though the llseek system call was already supported.
The prototype of the file operation in the 2.0 kernel was the following:
int (*lseek) (struct inode *inode, struct file *filp , off_t off, int whence);2.0 and SMP
Quick Reference
This chapter introduced the following symbols and header files.
#include <linux/ioctl.h>This header declares all the macros used to define ioctl commands. It is currently included by
<linux/fs.h>.
_IOC_NRBITS_IOC_TYPEBITS_IOC_SIZEBITS_IOC_DIRBITSThe number of bits available for the different bitfields of ioctl commands. There are also four macros that specify the
MASKs and four that specify theSHIFTs, but they're mainly for internal use._IOC_SIZEBITSis an important value to check, because it changes across architectures.
_IOC_NONE_IOC_READ_IOC_WRITEThe possible values for the "direction'' bitfield. "Read'' and "write'' are different bits and can be OR'd to specify read/write. The values are 0 based.
_IOC(dir,type,nr,size)_IO(type,nr)_IOR(type,nr,size)_IOW(type,nr,size)_IOWR(type,nr,size)
_IOC_DIR(nr)_IOC_TYPE(nr)_IOC_NR(nr)_IOC_SIZE(nr)Macros used to decode a command. In particular,
_IOC_TYPE(nr)is an OR combination of_IOC_READand_IOC_WRITE.
#include <asm/uaccess.h>int access_ok(int type, const void *addr, unsigned long size);This function checks that a pointer to user space is actually usable. access_ok returns a nonzero value if the access should be allowed.
VERIFY_READVERIFY_WRITEThe possible values for the
typeargument in access_ok.VERIFY_WRITEis a superset ofVERIFY_READ.
#include <asm/uaccess.h>int put_user(datum,ptr);int get_user(local,ptr);int __put_user(datum,ptr);int __get_user(local,ptr);Macros used to store or retrieve a datum to or from user space. The number of bytes being transferred depends on
sizeof(*ptr). The regular versions call access_ok first, while the qualified versions (__put_user and __get_user) assume that access_ok has already been called.
#include <linux/capability.h>Defines the various
CAP_symbols for capabilities under Linux 2.2 and later.
int capable(int capability);
#include <linux/wait.h>typedef struct { /* ... */ } wait_queue_head_t;void init_waitqueue_head(wait_queue_head_t *queue);DECLARE_WAIT_QUEUE_HEAD(queue);The defined type for Linux wait queues. A
wait_queue_head_tmust be explicitly initialized with either init_waitqueue_head at runtime or declare_wait_queue_head at compile time.
#include <linux/sched.h>void interruptible_sleep_on(wait_queue_head_t *q);void sleep_on(wait_queue_head_t *q);void interruptible_sleep_on_timeout(wait_queue_head_t *q, long timeout);void sleep_on_timeout(wait_queue_head_t *q, long timeout);Calling any of these functions puts the current process to sleep on a queue. Usually, you'll choose the interruptibleform to implement blocking read and write.
void wake_up(struct wait_queue **q);void wake_up_interruptible(struct wait_queue **q);void wake_up_sync(struct wait_queue **q);void wake_up_interruptible_sync(struct wait_queue **q);These functions wake processes that are sleeping on the queue
q. The _interruptible form wakes only interruptible processes. The _syncversions will not reschedule the CPU before returning.
typedef struct { /* ... */ } wait_queue_t;init_waitqueue_entry(wait_queue_t *entry, struct task_struct *task);
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait);void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);These functions add an entry to a wait queue; add_wait_queue_exclusive adds the entry to the end of the queue for exclusive waits. Entries should be removed from the queue after sleeping with remove_wait_queue.
void wait_event(wait_queue_head_t q, int condition);int wait_event_interruptible(wait_queue_head_t q, int condition);These two macros will cause the process to sleep on the given queue until the given
conditionevaluates to a true value.
void schedule(void);
#include <linux/poll.h>void poll_wait(struct file *filp, wait_queue_head_t *q, poll_table *p)This function puts the current process into a wait queue without scheduling immediately. It is designed to be used by the poll method of device drivers.
int fasync_helper(struct inode *inode, struct file *filp, int mode, struct fasync_struct **fa);
void kill_fasync(struct fasync_struct *fa, int sig, int band);
#include <linux/spinlock.h>typedef struct { /* ... */ } spinlock_t;void spin_lock_init(spinlock_t *lock);The
spinlock_ttype defines a spinlock, which must be initialized (with spin_lock_init) prior to use.
spin_lock(spinlock_t *lock);spin_unlock(spinlock_t *lock);spin_lock locks the given lock, perhaps waiting until it becomes available. The lock can then be released with spin_unlock.

|
|

|
Back to: Linux Device Drivers, 2nd Edition
oreilly.com Home | O'Reilly Bookstores | How to Order | O'Reilly Contacts
International | About O'Reilly | Affiliated Companies | Privacy Policy
╘ 2001, O'Reilly & Associates, Inc.