Библиотека сайта rus-linux.net
Система распознавания символов (OCR)
Оригинал: Optical Character Recognition (OCR)
Автор: Marina Samuel
Дата публикации: July 12, 2016
Перевод: Н.Ромоданов
Дата перевода: февраль 2017 г.
Перевод главы 15 из книги "500 Lines or Less", которая представляет собой четвертый том серии "Архитектура приложений с открытым исходным кодом".
Creative Commons
Перевод был сделан в соответствие с лицензией . С русским вариантом лицензии можно ознакомиться .
Введение
А что, если бы ваш компьютер мог помыть посуду, постирать белье, приготовить вам ужин, а также убраться в вашем доме? Я могу с уверенностью сказать, что большинство из нас было бы рады получить такую помощь! Но что нужно сделать в компьютере, чтобы он мог выполнять эти задачи точно так, как это делают люди?
Известный ученый Алан Тьюринг (Alan Turing) предложил тест, в последствие названный тестом Тьюринга, в качестве способа определения того, может ли машина иметь разум неотличимый от разума человеческого существа. В тесте человек задает вопросы человеку и машине и пытается по ответам определить, кто есть кто. Если человек не в состоянии определить, кто из отвечающих - машина, то считается, что машина имеет интеллект уровня человека.
Хотя вокруг теста Тьюринга ведется много споров о том, действительно ли он является оценкой интеллекта, и сможем ли мы действительно строить такие интеллектуальные машины, нет никаких сомнений в том, что машины с некоторой степенью интеллекта уже существуют. В настоящее время есть программное обеспечение, которое помогает роботам перемещаться офис и выполнять небольшие задания, либо помогать тем, кто страдает болезнью Альцгеймера. Более распространенными примерами искусственного интеллекта (Artificial Intelligence - A.I.) является то, как поисковик Google оценивает, что вы ищете, когда вы выполняете поиск по некоторым ключевым словам, или то, как социальная сеть Facebook решает, что поместить в ленту новостей.
Одним из хорошо известных примеров использования искусственного интеллекта является распознавание символов (Optical Character Recognition - OCR). Система распознавания символов является частью программного обеспечения, которое может в качестве входных данных принимать образы рукописных символов и интерпретировать их в машиночитаемый текст. Хотя вы можете ни о чем таком не думать, когда получаете в банкомате по чеку, подписанному от руки, некоторую сумму с депозитного счета, в фоновом режиме выполняется определенная интересная работа. В этой главе мы рассмотрим работающий пример простой системы распознавания символов, которая распознает цифры с помощью искусственной нейронной сети (Artificial Neural Network - ANN). Но, для начала, давайте немного расширим круг наших знаний.
Что такое искусственный интеллект?
Хотя определение интеллекта, данное Тьюрингом, звучит разумно, к концу дня влпрос о том, что представляет собой интеллект, обычно перерастает в философскую дискуссию. Но специалисты по компьютерным системам выделяют в отраслях искусственного интеллекта определенные типы систем. Каждый тип систем используется для решения определенных наборов задач. К подобным типам систем относятся следующие:
- Логическая и вероятностная дедукции и логический вывод на основе некоторого заранее определенного знания о мире, например, может помочь решить, когда нужно включить кондиционер в случае, если обнаружилось, что повысилась температура и воздух стал более влажным;
- Эвристический поиск, например, такой, который можно использовать для того, чтобы в шахматах найти наилучший следующий ход при помощи перебора всех возможных ходов и выбора именно того хода, после которого ваша позиция станет наилучшей;
- Машинное обучение (Machine learning - ML) с использованием моделей с обратной связью, например, решения проблем распознавания образов в таких системах, как распознавание символов.
Обычно при машинном обучении для подготовки системы, которая должна выявлять закономерности, требуется использовать большие наборы данных. Некоторые наборы данных, которые будут использованы для обучения, могут быть промаркированы, что означает, что этих входных данных указаны ожидаемые результаты, а для немаркированных данных ожидаемые результаты не определены. Алгоритмы, которые обучают системы с использованием немаркированных данных, называются алгоритмами с обучением без учителя (unsupervised algorithms), а те, которые обучают систему по маркированным данным, называются алгоритмами с обучением с учителем (supervised algorithms). Для создания систем распознавания символов используется много алгоритмов и методов машинного обучения, и одним из подходов являются искусственные нейронные сети.
Искусственные нейронные сети
Что такое искусственные нейронные сети?
Искусственная нейронная сеть (Artificial Neural Networks – ANN) представляет собой структуру, состоящую из соединенных между собой узлов, которые взаимодействуют друг с другом. Интерес к такой структуре и ее функциональным возможностям возник после изучения нейронных сетей, обнаруженных в мозге биологических структур. объясняет, как за счет физического изменения своей структуры и степени связи между элементами такие сети могут научиться распознавать некоторые фигуры. Аналогичным образом в типичной искусственной нейронной сети (показана на рис.15.1) между узлами есть связи, имеющие вес, причем этот вес изменяется по мере того, как сеть обучается. Узлы, помеченные "+1" имеют смещение. Крайний левый столбец синих узлов является столбцом с входными узлами, средний столбец содержит скрытые узлы, а крайний правый столбец содержит выходные узлы. Столбцов со скрытыми узлами, которые называются скрытыми слоями, может быть много.
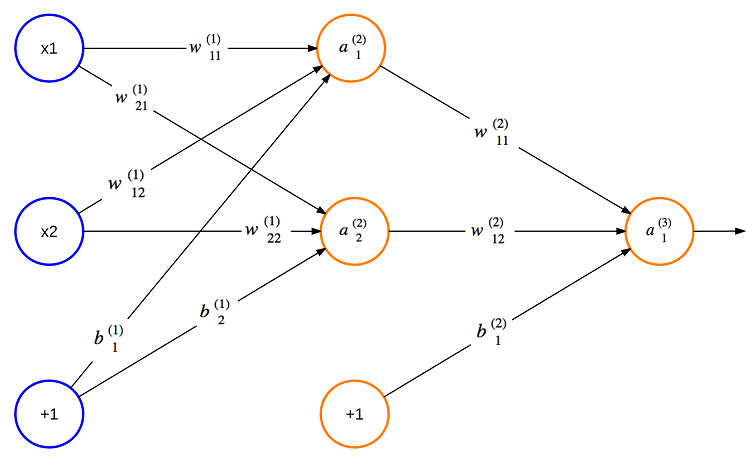
Рис.15.1. Искусственная нейронная сеть
Значения внутри каждого из круглых узлов, показанных на рис.15.1, представляют собой выходные данные узла. Если мы обозначим выходные данные n-го узла из верхней части слоя L как n(L), а связь между i-тым узлом слоя L и j-тым узлом в слое L+1 как wj(L)i, то выходные данные узла a2(2) будут определены следующим образом:
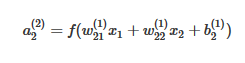
где f(.) называется функцией активации, а b является смещением. Функция активации является функцией, принимающей решение о том, какие выходные данные будут у этого узла. Смещение является дополнительным узлом с фиксированными выходными данными, равными значению 1, которое может быть добавлено к искусственной нейронной сети для повышения ее точности. Мы далее рассмотрим эти два понятия более детально при .
Такой тип сетевой топологии называется нейронной сетью прямого распространения (feedforward neural network), потому что в ней нет циклов. Искусственные нейронные сети с узлами, выходные в которых подаются на их входы, называются реккурентными нейронными сетями (recurrent neural networks). Есть много алгоритмов, которые можно применить для обучения искусственных нейронных сетей прямого распространения; один их часто используемх алгоритмов называется алгоритмом обратного распространением (backpropagation). В системе распознавания текста, которую мы будем реализовывать в этой главе, будет использоваться алгоритм обратного распространения.
Как нам следует пользоваться искусственными нейронными сетями?
Как и в большинстве других подходов машинного обучения, первый шаг для использования алгоритма обратного распространения состоит в решении, как трансформировать или уменьшить нашу проблему в такую, с которой может справиться искусственная нейронная сеть. Другими словами, как мы можем преобразовать наши входные данные так, чтобы их можно было подать на вход искусственной нейронной сети? В случае нашей системы распознавания символов, мы можем в качестве входных данных использовать позиции пикселей для заданной цифры. Стоит отметить, что, чаще всего, выбор формата входных данных не так прост. Если бы мы, например, анализировали большие изображения с целью идентификации в них фигуры, нам бы, возможно, потребовалось бы предварительно обрабатывать изображения таким образом, чтобы внутри них выявлять контуры. Эти контуры были бы входными данными.
А что делать после того, как мы выбрали формат наших входных данных? Поскольку алгоритм обратного распространения является алгоритмом обучения с учителем, то так, как уже упоминалось ранее, его следует обучить с помощью помеченных данных. Таким образом, если мы в качестве обучающих данных подаем данные в виде пикселей, то мы также должны подать данные и с соответствующей цифрой. Это значит, что мы должны найти или собрать большой набор данных, состоящий из нарисованных цифр и соответствующих значений.
Следующим шагом будет разделение набора данных на обучающий и проверочный наборы. Данные обучающего набора используется для запуска алгоритма обратного распространения, с помощью которого устанавливаются веса в нейронной сети. Данные проверочного набора используются для создания предсказаний с помощью обученной сети и вычисления их точности. Если бы мы на наших данным сравнивали производительность алгоритма обратного распространения с производительностью другого алгоритма, то нам бы нужно было разделить данные следующим образом: 50% - на обучение, 25% - для сравнения производительности двух алгоритмов (проверочный набор) и оставшиеся 25% - для тестирования точности выбранного алгоритма (тестовый набор). Поскольку мы не сравниваем алгоритмы, мы можем объединить один из наборов, содержащий 25% данных, с обучающим набором и использовать полученные 75% данных для обучения сети, а 25% данных для того, чтобы проверить, насколько хорошо был обучен алгоритм.
Точность работы нейронной сети определяют для двух целей. Во-первых, для того, чтобы избежать проблемы излишнего обучения. Излишнее обучения происходит, когда сеть имеет гораздо более высокую точность прогнозирования на обучающей выборке, чем на проверочном наборе. Излишнее обучение говорит нам о том, что выбранные для обучения данные недостаточно обобщены и нуждаются в уточнении. Во-вторых, проверка точности для различного количества скрытых слоев и скрытых узлов позволяет нам при разработке искусственной нейронной сети выбрать ее наиболее оптимальный размер. Оптимальный размер нейронной сети будет иметь достаточное количество скрытых узлов и слоев с тем, чтобы можно было делать точные прогнозы, но если можно использовать сеть с несколько меньшим количеством узлов/соединений, то это уменьшит вычислительные накладные расходы, из-за которых может замедлиться обучение сети и увеличится время ожидания результатов прогнозов. После того, как будет выбран оптимальный размер, и сеть будет обучена, она готова делать прогнозы!
Перейти к следующей части статьи.