Библиотека сайта rus-linux.net
Contingent: Динамическая система сборки
Оригинал: Contingent: A Fully Dynamic Build System
Авторы: Brandon Rhodes, Daniel Rocco
Дата публикации: July 12, 2016
Перевод: Н.Ромоданов
Дата перевода: январь 2017 г.
Правильное использование классов
Вы, возможно, были удивлены отсутствием классов в приведенном выше обсуждении структуры данных языка Python. В конце концов, классы являются частным механизмом структурирования приложений и вряд ли менее частым предметом жарких споров среди сторонников и недоброжелателей использования классов. Как когда-то думали, классы были достаточно важными с тем, чтобы вокруг них были разработаны все учебные программы, и в большинстве популярных языков программирования есть синтаксические конструкции для их определения и использования.
Но оказывается, что классы часто просто безразличны вопросам разработки структуры данных. Вместо того, чтобы предложить нам совершенно альтернативную парадигму моделирования данных, классы просто повторяют структуры данных, которые мы уже видели:
- Экземпляр класса реализуется как словарь dict.
- Экземпляр класса используется как мутируемый (изменяемый) кортеж.
В классе предлагается просмотр ключа с помощью красивого синтаксиса, где у вас есть, скажем, graph.incoming вместо graph["incoming"]. Но, на практике, экземпляры классов почти никогда не используются в качестве хранилищ вида "ключ-значение". Вместо этого они используются для организации связанных, но разнородных данных по имени атрибутов, причем детали реализации спрятаны (инкапсулированы) за согласованным и запоминающимся интерфейсом.
Так что вместо того, чтобы хранить в кортеже вместе имя хоста и номер порта и вспоминать, что было на первом месте и что занимало второе, вы создаете класс Address, в экземплярах которого есть атрибуты host и port. Затем вы можете передавать объекты Address везде, где в противном случае вы должны были использовать анонимные кортежи. Код становится легче читать и проще писать. Но использование экземпляра класса реально ничего не меняет из того, с чем мы сталкиваемся при проектировании данных; он просто представляем собой более красивый и менее анонимный контейнер.
Тогда истинное значение классов не том, что они меняют науку проектирования данных. Значение классов в том, что они позволяют скрыть ваш дизайн данных от остальной части программы!
Удачный дизайн приложений зависит от нашей способности использовать мощные встроенные структуры данных, которые нам предлагает язык Python и одновременной минимизации объема деталей, которые мы обязаны держать в наших головах в любой момент времени. Классы предоставляют нам механизм для решения этой очевидной дилеммой: используются эффективно и предоставляют фасад вокруг некоторой небольшой части общего дизайна системы. Когда работа ведется с одним подмножеством, например с графом Graph, мы можем не помнить о деталях реализаций других подмножеств до тех пор, пока знаем их интерфейс. Таким образом, программисты в процессе написания системы часто сами перемещаются между несколькими уровнями абстракции — они работают с конкретной моделью и деталями реализации конкретной подсистемы, а когда переходят к концепциям более высокого уровня, то пользуются их интерфейсами.
Например, если смотреть извне, то код может просто запрашивать новый экземпляр граф Graph:
>>> from contingent import graphlib >>> g = graphlib.Graph()
и не нужно разбираться с тем, как работает класс Graph. При обработке графа, когда добавляется ребро или выполняются некоторые другие операции, код, в котором используется граф, просто выглядит как интерфейс действий — обращения к методам:
>>> g.add_edge('index.rst', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial.html')
>>> g.add_edge('api.rst', 'api.html')
Внимательные читатели заметили, что мы добавили ребра в наш граф без явного создания объектов "узел" и "ребро", а сами вершины в этих предварительных примерах являются просто строками. Если обратиться к другим языкам и традициям, можно было бы ожидать что для всего, что есть в системе, увидим определяемые пользователем классы и интерфейсы:
Graph g = new ConcreteGraph();
Node indexRstNode = new StringNode("index.rst");
Node indexHtmlNode = new StringNode("index.html");
Edge indexEdge = new DirectedEdge(indexRstNode, indexHtmlNode);
g.addEdge(indexEdge);
Как в самом языке Python, так и среди сообщества его приверженцев явно и намеренно делается акцент на использование простых исходных структур данных для решения проблем вместо того, чтобы для каждой ежеминутно возникающей проблемы создавать пользовательские классы. Это один из аспектов понятия решений в стиле "Pythonic": в решениях на языке Python стараются свести к минимуму накладные расходы, связанные с синтаксисом, и переложить нагрузку на мощные встроенные инструменты языка Python и на обширную стандартную библиотеку.
Давайте с учетом этих соображений вернемся к классу Graph, проанализируем его структуру и реализацию с тем, чтобы выявить взаимосвязь между структурами данных и интерфейсов класса. Когда создается новый экземпляр класса Graph, то уже должны быть построены два словаря, в которых согласно логике, описанной в предыдущем разделе, должны храниться ребра:
class Graph:
"""A directed graph of the relationships among build tasks."""
def __init__(self):
self._inputs_of = defaultdict(set)
self._consequences_of = defaultdict(set)
Подчеркивание перед именами атрибутов _inputs_of и _consequences_of является общим соглашением в сообществе приверженцев языка Python, которое указывает, что атрибут является приватным (типа private). Такое соглашение является одним из способов, с помощью которого сообщество предлагает программистам передавать сообщения и предупреждения друг с другу сквозь пространство и время. Признавая необходимость указывать различия между общедоступными (типа public) и внутренними атрибутами объекта, сообщество приняло решение, что один символ подчеркивания, предваряющий атрибут, будет указателем для других программистов, в том числе и для нас самих в будущем, на то, что этот атрибут лучше всего трактовать как часть невидимого внутреннего механизма конкретного класса.
Почему же мы используем defaultdict вместо стандартного словаря dict? Когда словари dict компонуются с другими данным, то обычной проблемой становится обработка недостающих ключей. При использовании обычного словаря dict поиск ключа, который не существует, вызывает появление ошибки KeyError:
>>> consequences_of = {}
>>> consequences_of['index.rst'].add('index.html')
Traceback (most recent call last):
...
KeyError: 'index.rst'
Для того, чтобы обработать такой конкретный случай, использование обычного словаря dict требует использование в коде специальной проверки, например, для случая, когда добавляется новое ребро:
# Special case to handle “we have not seen this task yet”:
if input_task not in self._consequences_of:
self._consequences_of[input_task] = set()
self._consequences_of[input_task].add(consequence_task)
Эта ситуация настолько обычная, что в языке Python есть специальная утилита defaultdict, предоставляющая функцию, которая возвращает значение для отсутствующих ключей. Когда мы спрашиваем о ребре, которого еще нет в классе Graph, мы вместо исключения получим в ответ пустой набор данных:
>>> from collections import defaultdict >>> consequences_of = defaultdict(set) >>> consequences_of['api.rst'] set()
Задание таким способом структуры нашей реализации означает, что в случае, если используется один и тот же ключ, первое обращение к каждому ключу может выглядеть точно также как и второе и последующие:
>>> consequences_of['index.rst'].add('index.html')
>>> 'index.html' in consequences_of['index.rst']
True
Давайте с учетом этих методов рассмотрим реализацию метода add_edge, который мы ранее использовали для построения графа на рис.4.1.
def add_edge(self, input_task, consequence_task):
"""Add an edge: `consequence_task` uses the output of `input_task`."""
self._consequences_of[input_task].add(consequence_task)
self._inputs_of[consequence_task].add(input_task)
В этом методе скрыт тот факт, что поскольку нам нужно знать об обеих ориентациях ребра, для каждого нового ребра потребуются два, а не один , шага его запоминания. И обратите внимание, что в методе add_edge()не известно и не требуется знать была ли прежде известна вершина. Поскольку первоначальная и каждая последующая структура данных создается с использованием defaultdict(set), метод add_edge( остается в блаженном неведении относительно новизны вершины - defaultdict на лету заботится о разнице и создает новый объект set. Как мы видели выше, метод add_edge( мог бы быть в три раза больше, если бы мы не использовали defaultdict. Более важно еще и то, что было бы труднее понять и разобраться с получившемся в результате кодом. В данной реализации демонстрируется подход к проблемам в стиле Pythonic: простой, прямой и краткий.
Для тех, кто будет обращаться, также нужно предоставить простой способ посетить каждое ребро без необходимости знать, как перемещаться по нашей структуре данных:
def edges(self):
"""Return all edges as ``(input_task, consequence_task)`` tuples."""
return [(a, b) for a in self.sorted(self._consequences_of)
for b in self.sorted(self._consequences_of[a])]
С помощью метода Graph.sorted() делается попытка отсортировать вершины в естественном порядке (например, в алфавитном порядке), что может гарантировать для пользователя стабильный порядок вывода данных.
Видно, что благодаря использованию этого метода обхода вызов следующих наших трех методов становится проще, а граф g является тем же самым графом, который мы видели на рис.4.1.
>>> from pprint import pprint
>>> pprint(g.edges())
[('api.rst', 'api.html'),
('index.rst', 'index.html'),
('tutorial.rst', 'tutorial.html')]
Так как у нас теперь есть настоящий живой объект языка Python, а не просто число, мы можем узнать о нем много интересного! Например, когда система Contingent строит блог из исходных файлов и когда изменяется содержимое файла api.rst, системе необходимо знать ответы на такие вопросы, как, например, "Какие объекты зависят от файла api.rst?":
>>> g.immediate_consequences_of('api.rst')
['api.html']
Данный граф Graph сообщает системе Contingent о том, что, когда изменяется файл api.rst, файл api.html становится устаревшим и его нужно будет заново пересобрать.
А как насчет файла index.html?
>>> g.immediate_consequences_of('index.html')
[]
Был возвращен пустой список и это указывает на то, что файл index.html находится в правой части графа и, поэтому, если этот файл меняется, то ничего не нужно больше пересобирать. Этот запрос можно выразить очень просто благодаря той работе, которая уже была выполнена при формировании структуры наших данных:
def immediate_consequences_of(self, task):
"""Return the tasks that use `task` as an input."""
return self.sorted(self._consequences_of[task])
>>> from contingent.rendering import as_graphviz
>>> open('figure1.dot', 'w').write(as_graphviz(g)) and None
На рис.4.1 проигнорировано одно из наиболее важных соотношений, которые мы обнаружили в вводной части нашей главы: способ, с помощью которого заголовки документов появляются в оглавлении. Давайте добавим эту деталь. Мы создадим вершину для каждой строки заголовка, которая должна быть создана с помощь анализа входного файла и перехода к одной из наших следующих подпрограмм:
>>> g.add_edge('api.rst', 'api-title')
>>> g.add_edge('api-title', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial-title')
>>> g.add_edge('tutorial-title', 'index.html')
Результатом будет граф (рис.4.2), с помощью которого можно будет правильно обрабатывать пересборку оглавления, что мы обсуждали в начале этой главы.
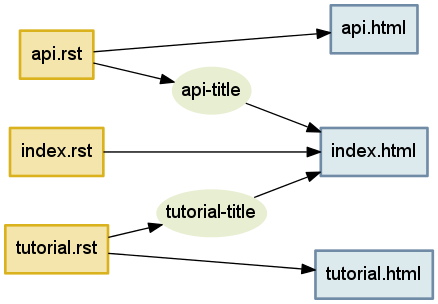
Рис.4.2: Всякий раз, когда изменяется любой из заголовков, которые используются в файле index.html, то нужно будет пересобрать этот файл.
Выше было проиллюстрировано, что, в конечном итоге, система Contingent делает для нас: в графе g собираются все исходные данные и зависимости для различных артефактов, имеющихся в документации нашего проекта.
Перейти к следующей части статьи.
Перейти к началу статьи.