Библиотека сайта rus-linux.net
Веб бот, использующий сопрограммы asyncio (3 часть)
Предварительная публикация главы из сборника "500 строк или меньше", новой книги серии «The Architecture of Open Source Applications»
Оригинал: "A Web Crawler With asyncio Coroutines"
Автор: A. Jesse Jiryu Davis and Guido van Rossum
Дата публикации: 15 September 2015
Перевод: Н.Ромоданов
Дата перевода: январь 2016 г.
Это продолжение статьи. Начало смотрите здесь
Координирование работы сопрограмм
Мы начали с описания того, как, по нашему мнению, должен работать бот. Теперь пришло время реализовать эту работу с помощью сопрограмм asyncio.
Наш бот будет получать первую страницу, находить на ней ссылки и добавлять их в очередь. После этого он продолжит сканировать сайт и анализировать несколько страниц одновременно. Но, чтобы ограничить нагрузку на клиентскую и и серверную части, мы хотим указать некоторое максимальное количество worker-ов, которые должны работать, и не более того. Всякий раз, когда worker завершает получение страницы, он должен немедленно брать из очереди следующую ссылку. Могут возникать ситуации, когда работы не будет не хватать, так что некоторые worker-ы должны приостанавливать свою работу. Но, когда worker попадает на страницу с большим количеством новых ссылок, то очередь внезапно вырастает и любой worker, который находился в паузе, должен проснуться и получить задание. Наконец, наша программа должна остановиться сразу, как только вся работа будет сделана.
Представьте себе, если бы worker-ы были потоками. Как бы мы должны были записать алгоритм работы бота? Возможно, мы бы могли использовать синхронизированную очередь [11] из стандартной библиотеки Python. Каждый раз, когда элемент помещается в очередь, очередь увеличивает счетчик "задач". Потоки worker-ов после завершения работы с отдельным элементом вызывают task_done. Основной поток блокирует Queue.join до тех пор, пока каждому обрабатываемому элементу в очереди будет соответствовать некоторый вызов task_done, после чего происходит выход из программы.
Сопрограммы используют тот же самый шаблон с очередью из asyncio! Во-первых, мы импортируем очередь asyncio [12]:
try:
from asyncio import JoinableQueue as Queue
except ImportError:
# In Python 3.5, asyncio.JoinableQueue is
# merged into Queue.
from asyncio import Queue
Мы собираем все состояния worker-ов в классе crawler и записываем основную логику в его методе crawl. Мы запускаем crawl в виде сопрограммы и цикл asyncio работает до тех пор, пока crawl не закончит свою работу:
loop = asyncio.get_event_loop()
crawler = crawling.Crawler('http://xkcd.com',
max_redirect=10)
loop.run_until_complete(crawler.crawl())
crawler начинает свою работу с корневого адреса URL и значения max_redirect, т. е. Того количества ссылок, по которым он будет двигаться для того, чтобы получить какой-нибудь еще один адрес URL. Он помещает пару (URL, max_redirect) в очередь. (Зачем? Немного потерпите …).
class Crawler:
def __init__(self, root_url, max_redirect):
self.max_tasks = 10
self.max_redirect = max_redirect
self.q = Queue()
self.seen_urls = set()
# aiohttp's ClientSession does connection pooling and
# HTTP keep-alives for us.
self.session = aiohttp.ClientSession(loop=loop)
# Put (URL, max_redirect) in the queue.
self.q.put((root_url, self.max_redirect))
Сейчас количество незавершенных задач в очереди равно одной. Вернемся в наш основной скрипт и запустим цикл событий и метод crawl:
loop.run_until_complete(crawler.crawl())
Сопрограмма crawl запускает worker-ы. Это похоже на основной поток: она блокирует join до тех пор , пока все задачи не будут закончены, а worker-ы в это время работают в фоновом режиме.
@asyncio.coroutine
def crawl(self):
"""Run the crawler until all work is done."""
workers = [asyncio.Task(self.work())
for _ in range(self.max_tasks)]
# When all work is done, exit.
yield from self.q.join()
for w in workers:
w.cancel()
Если бы worker-ы были потоками, то мы, возможно, не захотели бы запускать их все сразу. Чтобы избежать использования дорогостоящих потоков до тех пор, пока не будет ясно, что они необходимы, мы бы увеличивали пул потоков только тогда, когда это бы действительно было нужно. Но сопрограммы дешевы, так что мы просто запускаем их в максимально допустимом количестве.
Интересно рассмотреть то, как бот прекращает работу. Когда значение фьючерса join будет получено, задачи worker не уничтожаются, а лишь приостанавливаются: они ждут новых адресов URL, но адреса не поступают. Поэтому главная сопрограмма уничтожит их перед тем, как завершить работу. В противном случае интерпретатор Python остановится и вызовет деструкторы всех объектов, а все «живые» задачи выдадут следующее сообщение:
ERROR:asyncio:Task was destroyed but it is pending!
(ОШИБКА: Уничтожена приостановленная задача Task)
А как операция cancel выполняет свою работу? В генераторах есть фьючерсы, о которых мы вам еще не рассказали. Вы можете извне передать в генератор исключение:
>>> gen = gen_fn()
>>> gen.send(None) # Start the generator as usual.
1
>>> gen.throw(Exception('error'))
Traceback (most recent call last):
File "<input>", line 3, in <module>
File "<input>", line 2, in gen_fn
Exception: error
Генератор возобновляет свою работу с помощью throw, но в результате возникает исключение. Если в стеке вызовов генератора нет закешированного кода, то исключение передается по стеку обратно вверх. Поэтому для того, чтобы завершить работу сопрограммы task:
# Method of Task class.
def cancel(self):
self.coro.throw(CancelledError)
Когда генератор переводится в паузу в некоторой инструкции yield from, он возобновляет свою работу и выдает исключение. Мы осуществляем завершение работы в методе step задачи task:
# Method of Task class.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration:
return
next_future.add_done_callback(self.step)
Теперь задача знает, что ее работа будет завершена, поэтому когда она будет уничтожаться, она не будет выдавать никаких сообщений.
Выход из crawl произойдет после того, как будет завершена работа worker-ов. Цикл событий видит, что сопрограмма завершена (как это делается, мы увидим позже) и таким образом произойдет выход из цикла:
loop.run_until_complete(crawler.crawl())
В метод crawl включено все, что должна делать наша главная сопрограмма. Это сопрограммы worker, которые из очереди получают адреса URL, операция перехода по адресам и анализ полученного результата на наличие новых ссылок. В каждом worker-е запускается отдельная сопрограмма work:
@asyncio.coroutine
def work(self):
while True:
url, max_redirect = yield from self.q.get()
# Download page and add new links to self.q.
yield from self.fetch(url, max_redirect)
self.q.task_done()
Python видит, что в этом коде есть инструкции yield from, и компилирует его в функцию-генератор. Поэтому когда главная сопрограмма десять раз вызывает self.work, этот метод, на самом деле, выполняться не будет: он только создает десять генераторов-объектов, имеющих ссылки на этот код. Каждый объект переносится в задачу Task. Задача Task получает каждый фьючерс через поля генератора и когда значение фьючерса будет известно, запускает генератор с каждым результатом фьючерса при помощи метода send. Поскольку в генераторах есть свои собственные фрагменты стека, они работают независимо друг от друга со своими собственными локальными переменными и указателями команд.
Координация работы worker-ов осуществляется с помощью очереди. Каждый worker ожидает новые адреса URL с помощью следующего кода:
url, max_redirect = yield from self.q.get()
Метод get очереди сам по себе является сопрограммой: он переходит в паузу до тех пор, пока кто-нибудь не поместит элемент в очередь, после чего он возобновит работу и вернет этот элемент.
Кстати, это также происходит в случае, когда worker перейдет в паузу в конце обхода, когда главная сопрограмма завершит работу. С точки зрения рассмотрения сопрограммы, такое последнее путешествие по циклу событий происходит в случае, когда инструкция yield from выдает ошибку CancelledError.
Когда worker получает страницу, он анализирует ссылки и помещает новые ссылки в очередь, а затем вызывает task_done для того, чтобы на единицу уменьшить значение счетчика. В конце концов, worker получает страницу, адреса URL на которой уже были найдены, и нет никакой работы кроме той, что находится в очереди. Таким образом, вызов worker-ром метода task_done уменьшает значение счетчика до нуля. После этого crawl, который ожидает выполнения метода join для очереди, выходит их паузы и завершает работу.
Мы обещали объяснить, почему элементы в очереди представляют собой пары следующего вида:
# URL to fetch, and the number of redirects left.
('http://xkcd.com/353', 10)
Для новых адресов URL указывается десять оставшихся перенаправлений. Когда будут получены конкретные результаты для этого URL, то будет задан новый адрес с завершающей косой чертой. Мы уменьшаем количество оставшихся перенаправлений и помещаем в очередь новый адрес:
# URL with a trailing slash. Nine redirects left.
('http://xkcd.com/353/', 9)
Пакет aiohttp, которым мы пользуемся, будет следовать перенаправлению, которое задано по умолчанию, и предоставит нам окончательный результат. Однако, мы не сообщаем, куда направить результат, и обработчик перенаправляет результат в crawler, который может объединить пути, ведущие к одной цели: если мы уже видели это адрес URL, то он находится в self.seen_urls и мы уже пошли по этому пути в другой точке входа:
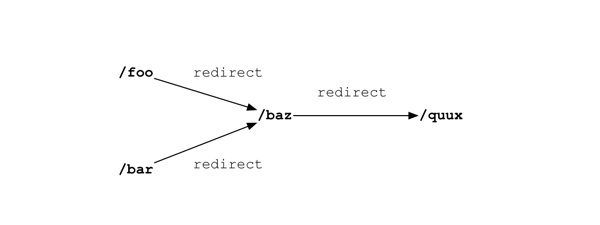
Рис.9.4: Перенаправления
crawler выбирает "foo" и видит, что он перенаправляется на "baz", так что добавляет "baz" в очередь и переходит к seen_urls. Если следующая страница, которую он получает, это "foo", которая также перенаправляется на "baz", но "baz" повторно в очередь не помещается.
@asyncio.coroutine
def fetch(self, url, max_redirect):
# Handle redirects ourselves.
response = yield from self.session.get(
url, allow_redirects=False)
try:
if is_redirect(response):
if max_redirect > 0:
next_url = response.headers['location']
if next_url in self.seen_urls:
# We have been down this path before.
return
# Remember we have seen this URL.
self.seen_urls.add(next_url)
# Follow the redirect. One less redirect remains.
self.q.put_nowait((next_url, max_redirect - 1))
else:
links = yield from self.parse_links(response)
# Python set-logic:
for link in links.difference(self.seen_urls):
self.q.put_nowait((link, self.max_redirect))
self.seen_urls.update(links)
finally:
# Return connection to pool.
yield from response.release()
Если в результате будет получена страница, а не перенаправление, то fetch анализирует ее на предмет ссылок и помещает новые ссылки в очередь.
Если бы это был многопоточный код, то все бы плохо из-за состояния гонок (race conditions). Например, в последних нескольких строках worker проверяет, находится ли ссылка в seen_urls, и если нет, то worker ставит ее в очередь и добавляет в seen_urls. Если последовательность действий между двумя операциями прерывается, то другой worker может обработать ту же самую ссылку, находящуюся на другой странице, обнаружив, что ее еще нет в seen_urls, и также добавит ее в очередь. Теперь одна и та же ссылка помещена в очередь два раза, что приводит (в лучшем случае) к дублированию работы и неверным статистическим данным.
Однако сопрограмма уязвима только в случае прерывания инструкции yield from. Это ключевое различие, поскольку это делает код сопрограмм гораздо менее подверженным состоянию гонки, чем многопоточный код: многопоточный код должен войти в критическую секцию явно и установить блокировку, т. к. в противном случае возможно возникновение прерывания. Однако, по умолчанию, в сопрограмме Python прерывание не возникает и сопрограмма уступает управление только тогда, когда это запрашивается явно.
Нам больше не нужен класс fetcher наподобие того, который у нас был в программе с обратными вызовами. Назначением этого класса была попытка справиться с дефицитом обратных вызовов: поскольку их локальные переменные не сохраняются между вызовами, то им нужно было немного места для сохранения состояния в тех случаях, когда они ожидают операции ввода/вывода. Но сопрограмма fetch может хранить свое состояние в локальных переменных точно также, как это делает обычная функция, так что больше нет необходимости использовать класс.
Когда метод fetch завершит обработку ответа сервера, он возвратит управление в вызывающий метод work. Метод work вызывает для очереди метод task_done, а затем из очереди получает следующий URL.
Когда метод fetch помещает новые ссылки в очередь, он увеличивает счетчик незавершенных задач на единицу и основная сопрограмма, которая ожидает q.join, переходит в паузу. Но если нет необнаруженных ссылок и это в очереди был последний адрес URL, то, когда метод work вызовет метод task_done, количество незавершенных задач уменьшится до нуля. Затем событие выведет метод join из паузы и основная сопрограмма завершится.
Код очереди, который координирует работу worker-ов и основной сопрограммы, выглядит следующим образом [13]:
class Queue:
def __init__(self):
self._join_future = Future()
self._unfinished_tasks = 0
# ... other initialization ...
def put_nowait(self, item):
self._unfinished_tasks += 1
# ... store the item ...
def task_done(self):
self._unfinished_tasks -= 1
if self._unfinished_tasks == 0:
self._join_future.set_result(None)
@asyncio.coroutine
def join(self):
if self._unfinished_tasks > 0:
yield from self._join_future
Основная сопрограмма, crawl, получит результат из join. Таким образом, когда последний worker уменьшит количество незавершенных задач до нуля, то это даст сигнал сопрограмме crawl возобновить работу и затем ее полностью завершить.
Путешествие почти завершено. Наша программа началась с вызова crawl:
loop.run_until_complete(self.crawler.crawl())
Каким образом программа завершится? Поскольку crawl является функцией-генератором, ее вызов возвратит генератор. Чтобы можно было управлять генератором, asyncio оборачивает его в задачу:
class EventLoop:
def run_until_complete(self, coro):
"""Run until the coroutine is done."""
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
class StopError(BaseException):
"""Raised to stop the event loop."""
def stop_callback(future):
raise StopError
Когда задача выполнена, то возникает исключение StopError, которое в цикл используется как сигнал о том, что цикл достиг нормального завершения.
Но что это такое? В задаче есть методы, которые называются add_done_callback (добавить выполненный обратный вызов) и result (результат)? Вы можете решить, что задача похожа на фьючерс. Ваши предположения правильны. Мы должны признать, что мы спрятали от вас одну особенность класса Task (задача): задача является фьючерсом.
class Task(Future):
"""A coroutine wrapped in a Future."""
Обычно фьючерс получает значение от какого-нибудь метода, который для него выполняет действие set_result. Но когда сопрограмма останавливается, задача сама задает значение фьючерса. Вспомните наше раннее исследование генераторов Python, в котором в случае, когда генератор возвращает управление, возникало исключение StopIteration:
# Method of class Task.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration as exc:
# Task resolves itself with coro's return
# value.
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
Поэтому, когда цикл обработки событий вызывает task.add_done_callback(stop_callback), он подготавливается задачей для остановки. Здесь снова run_until_complete:
# Method of event loop.
def run_until_complete(self, coro):
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
Когда задача отловит исключение StopIteration и сама установит значение, то внутри цикла сработает обратный вызов StopError. Цикл останавливается и стек вызовов опустошается до run_until_complete. Наша программа завершается.
Заключение
Все чаще, современные программы ограничены пропускной возможностью ввода/вывода, а не производительностью процесса. Для таких программ потоки в языке Python будут наилучшим вариантом: глобальная блокировка интерпретатора предотвращает их действительно параллельное исполнение, а их упреждающее переключение делает их защищенными от состояния гонки. Обычно правильным подходом является использование асинхронности. Но по мере того, как увеличивается объем асинхронного кода, использующего обратные вызовы, стремительно возрастает его запутанность. Сопрограммы в этом случае выглядят гораздо аккуратнее. Эта особенность естественна для сопрограмм с их рациональной обработкой исключений и трассировкой стека.
Если чуть-чуть отвести взгляд так, чтобы инструкция yield from исчезла из поля зрения, то сопрограмма будет выглядеть как поток, осуществляющий традиционный блокирующий ввод/вывод. Мы даже можем координировать взаимодействие сопрограмм с помощью классических шаблонов многопоточного программирования. Не требуется придумывать что-либо новое. Таким образом, для кодера, экспериментирующего с многопоточностью, сопрограммы будут более привлекательным подходом по сравнению с использованием обратных вызовов.
Но когда мы снова непосредственно взглянем на код и сосредоточимся на инструкциях yield from, то мы увидим, что ими отмечаются те места, когда сопрограмма уступает управление и позволяет другим сопрограммам работать. В отличие от потоков, в сопрограмме указывается, где наш код может быть прерван, а где - нет. Глиф Левковиц (Glyph Lefkowitz) в своем разъясняющем эссе "Unyielding" [14] пишет: «Потоки усложняют рассмотрение локальных логических последовательностей, а локальные логические последовательности являются, пожалуй, самым главным в разработке программного обеспечения». Но, когда результат можно получить явно, то с поведением подпрограммы (и, следовательно, ее правильностью) можно разобраться «рассмативая только подпрограмму, а не изучая всю систему».
Эта глава написана во время ренессанса языка Python и библиотеки async. Сопрограммы на основе генераторов, о разработке которых вы только что узнали, были реализованы в модуле "asyncio" для Python 3.4 в марте 2014 года. В сентябре 2015 года была выпущена версия Python 3.5 с сопрограммами, встроенными в сам язык. Это нативная реализация сопрограмм, использующая новый синтаксис"async def", причем для делегирования действия сопрограмме или ожидания фьючерса в них вместо инструкции "yield from" используется ключевое слово "await".
Несмотря на эти новшества основные идеи остаются точно такими же. Новые нативные сопрограммы языка Python будут синтаксически отличаться от генераторов, но работать они будут очень похоже; действительно, они будут совместно пользоваться реализацией в рамках интерпретатора Python. Задача Task, фьючерс Future и цикл событий будет продолжать играть свою роль в asyncio.
Теперь, когда вы знаете, как работают сопрограммы asyncio, вы можете забыть о большинстве подробностей. Механика скрыта за щеголеватым интерфейсом. Но ваше понимание основ позволит вам правильно и эффективно создавать код в современных условиях асинхронной обработки.
- Затем на PyCon 2013 Гвидо (Guido) представил стандартную библиотеку asyncio с названием "Tulip" ("Тюльпан").
- В случае, если принимающая сторона работает слишком медленно и буфер системы с исходящими данными заполнен, то блокироваться может даже вызов
send. - http://www.kegel.com/c10k.html
- В любом случае блокировщик глобального интерпретатора языка Python запрещает в одном процессе параллельное выполнение кода Python. Распараллеливание в Python алгоритмов, работа которых ограничивается производительностью процессора, требует использования нескольких процессов, либо участки кода, в которых нужно использовать распараллеливание, нужно писать на языке C. Но это тема уже другого обсуждения.
- Джесси (Jesse) в своей работе "What Is Async, How Does It Work, And When Should I Use It?" ("Что такое библиотека Async, как она работает, и когда ею нужно пользоваться?") перечислил ситуации, когда следует пользоваться библиотекой async и когда пользоваться ей не следует. Майк Байер (Mike Bayer) в работе "Asynchronous Python and Databases" ("Асинхронность в языке Python и базы данных") сравнивает пропускную способность библиотеки asyncio и использование многопоточности при различных нагрузках.
- Для комплексного решения этой проблемы смотрите http://www.tornadoweb.org/en/stable/stack_context.html.
- Декоратор
@asyncio.coroutineне волшебный. В самом деле, если с его помощью декорируется функция-генератор и не установлена переменная среды окруженияPYTHONASYNCIODEBUG, то декоратор практически ничего не делает. С его помощью просто устанавливается атрибут_is_coroutine, используемый для удобства в других частях фреймворка. Библиотеку asyncio для генераторов можно использовать вообще без декоратора@asyncio.coroutine. - Встроенные сопрограммы для версии Python 3.5 описаны в PEP 492 - "Coroutines with async and await syntax" ("Сопрограммы с библиотекой async и синтаксисом await").
- Этот фьючерс имеет много недостатков. Например, как только фьючерс получит значение, сопрограмма, которая его получает, немедленно возобновляет работу после паузы, но с нашим кодом это не так. Полную реализацию смотрите в классе Future библиотеки asyncio.
- На самом деле, это точно также, как "yield from" работает в CPython. Функция прежде, чем выполнить инструкцию, увеличивает свой собственный указатель инструкций на единицу. Но после того, как внешний генератор выполнит "yield from", из указателя инструкций будет вычтена единица с тем, чтобы он указывал на "yield from". Затем управление будет возвращено вызывающей части. Цикл повторяется до тех пор, пока внутренний генератор не выдаст исключение
StopIteration, которое укажет внешнему генератору, что ему, наконец, позволено перейти к следующей инструкции. - https://docs.python.org/3/library/queue.html
- https://docs.python.org/3/library/asyncio-sync.html
- Фактическая реализация
asyncio.Queueиспользуетasyncio.Eventвместо фьючерса Future, показанного здесь. Разница в том, что событие Event может быть перезагружено, в то время как Future не может вернуться из состояния, когда фьючерс уже имеет значение, в состояние ожидания. - https://glyph.twistedmatrix.com/2014/02/unyielding.html
Вернуться к началу статьи.
Перейти к оглавлению книг серии «The Architecture of Open Source Applications»
Дополнение
Перевод данной главы сделан по тексту преварительной публикации. 12 июля 2016 был выпущен и опубликован на сайте AOSA окончательный вариант сборника "500 строк или меньше", четвертой книги из серии книг "Архитектура приложений с открытым исходным кодом". Окончательный вариант данной главы можно найти по следующей ссылке.