Библиотека сайта rus-linux.net
PyPy
Глава 19 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: PyPy
Автор: Benjamin Peterson
Перевод: А.Панин
19.4. Инструменты преобразования кода для языка RPython
Набор инструментов для языка RPython предназначен для осуществления нескольких фаз преобразования кода, в ходе которых код на языке RPython преобразовывается в код на целевом языке, обычно C. Высокоуровневое представление фаз преобразования кода показано на Рисунке 19.1. Сами инструменты для преобразования кода разработаны с использованием языка Python (без ограничений) и тесно связаны с интерпретатором PyPy по причинам, которые будут освещены совсем скоро.
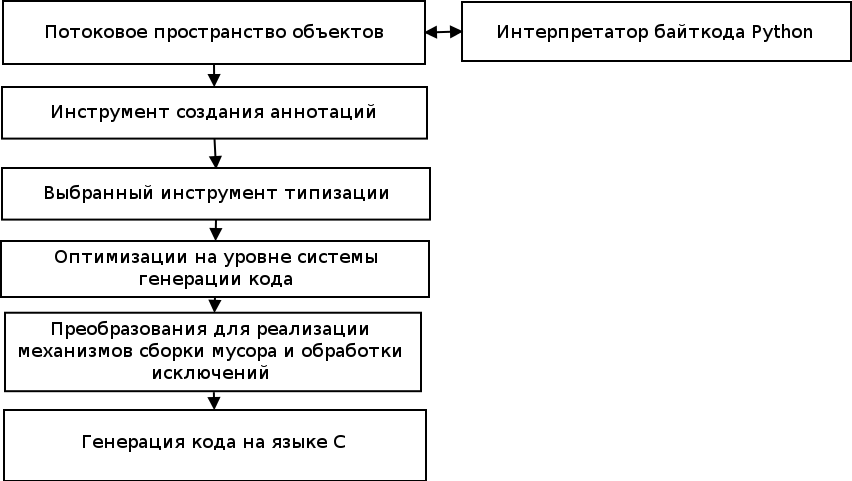
Рисунок 19.1: Шаги преобразования кода
Первой операцией, которую выполняет инструмент для преобразования кода, является загрузка программы на языке RPython в адресное пространство процесса. (Эта операция осуществляется с использование стандартных для языка Python директив, предназначенных для поддержки операций загрузки модулей). Язык RPython налагает ряд ограничений на стандартные динамические функции языка Python. Например, функции не могут создаваться в процессе работы программы и одна и та же переменная не имеет возможности хранить значения несовместимых типов, примером которых могут служить целочисленное значение и объект. Несмотря на это, в момент начальной загрузки программы инструментом преобразования кода, она обрабатывается обычным интерпретатором языка Python и может использовать все динамические функции языка Python. Интерпретатор языка Python из состава PyPy является программой значительного размера, разработанной с использованием языка RPython, которая эксплуатирует эту возможность для реализации функций метапрограммирования. Например, она генерирует код для управления мультиметодами в стандартном пространстве объектов. Единственное требование заключается в том, что программа должна использовать корректные для языка RPython синтаксические конструкции перед началом новой фазы преобразования кода средствами соответствующего инструмента.
Инструмент преобразования кода строит потоковые графы, отражающие программу на языке RPyton, в ходе процесса с названием "абстрактная интерпретация" ("abstract interpretation"). В ходе абстрактной интерпретации происходит повторное использование интерпретатора языка Python из состава PyPy для интерпретации программ на языке RPython при наличии специального пространства объектов, называемого потоковым пространством объектов (flow objspace). Повторимся, что интерпретатор языка Python рассматривает объекты в программе как черные ящики, обращаясь к пространству объектов для выполнения любой операции. Потоковое пространство объектов вместо стандартного набора объектов языка Python работает только с двумя типами объектов: переменными и константами. Переменные представляют значения, не известные в момент преобразования кода, а константы, что не удивительно, представляют неизменные значения, которые известны в данный момент. Потоковое пространство объектов обладает базовыми возможностями сворачивания констант; если требуется выполнить операцию, все аргументы которой являются константами, в рамках него будет осуществлено статическое вычисление значения. Требования к неизменности значений и указания на необходимость использования констант в рамках языка RPython обозначаются значительно шире, чем в стандартном языке Python. Например, модули, которые несомненно изменяемы в рамках языка Python, представляются константами в потоковом пространстве объектов, так как они не существуют в рамках языка RPython и должны быть свернуты в константы в потоковом пространстве объектов. По мере того, как интерпретатор языка Python интерпретирует байткод функций языка RPython, потоковое пространство объектов записывает операции, выполнение которых требуется. В рамках него осуществляется запись данных для всех конструкций условных ветвлений. Конечный результат абстрактной интерпретации функции является потоковым графом, состоящим из связанных блоков, причем каждый блок содержит одну или большее количество операций.
def factorial(n):
if n == 1:
return 1
return n * factorial(n - 1)
Потоковый граф для функции выглядит следующим образом:
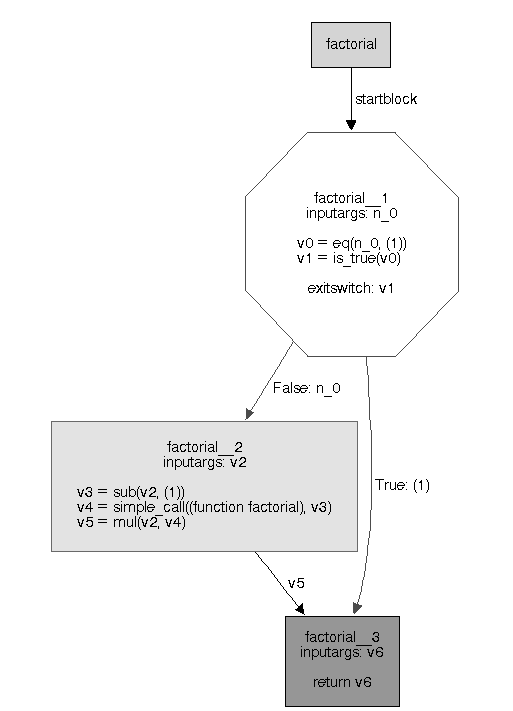
Рисунок 19.2: Потоковый граф для функции вычисления факториала
Функция вычисления факториала была разделена на блоки, содержащие операции, записанные в рамках потокового пространства объектов. Каждый блок имеет входные аргументы и список операций с переменными и константами. Первый блок содержит выбор перехода в конце, который позволяет установить, к какому блоку перейдет управление после завершения выполнения первого блока. Решение о выходе может приниматься на основе значения какой-либо переменной или на основе того, было ли сгенерировано исключение в ходе выполнения последней операции блока. Передача управления осуществляется в соответствии с линиями между блоками.
Потоковый граф, сгенерированный в потоковом пространстве объектов, представлен в статической единичной форме назначения (static single assignment form или SAA), являющейся промежуточном представлением, обычно используемым в компиляторах. Ключевая возможность представления SAA заключается в том, что значение каждой переменной присваивается единожды. Это свойство упрощает реализацию многих преобразований и оптимизаций, осуществляемых компиляторами.
После завершения генерации графа функции начинается фаза генерации аннотации. Инструмент создания аннотаций устанавливает типы результатов и аргументов для каждой из операций. Например, описанная выше функция вычисления факториала в аннотации будет принимать и возвращать целочисленные значения.
Следующая фаза называется типизацией (RTyping). В ходе типизации используется информация от инструмента создания аннотаций для того, чтобы преобразовать каждую из высокоуровневых операций, отображенных в рамках графа потоков данных, в низкоуровневые операции. Это первая часть процесса преобразования кода, для которой имеет значение выбранная система генерации кода. На основе системы генерации кода происходит выбор специфичного для программы инструмента типизации (RTyper). На данный момент инструмент типизации поддерживает две системы типов: низкоуровневую систему типов для систем генерации кода на таких языках, как C, а также высокоуровневую систему типов с классами. Высокоуровневые операции и типы языка Python приводятся в соответствие с выбранной системой типов. Например, для операции add с операндами, представленными целочисленными значениями в аннотации, будет сгенерирована операция int_add с низкоуровневой системой типов. Более сложные операции, такие, как поиск в хэш-таблицах, генерируют вызовы функций.
После типизации производятся некоторые оптимизации низкоуровневого потокового графа. Эти оптимизации по большей части являются такими стандартными применяемыми компиляторами оптимизациями, как сворачивание констант, удаление лишних операций резервирования памяти, а также удаление неиспользуемого кода.
Обычно код на языке Python периодически использует операции динамического резервирования памяти. Язык RPython, являясь производным языка Python, наследует этот шаблон проектирования, связанный с интенсивным резервированием памяти. Однако, в большинстве случаев эти резервирования памяти являются временными и локальными в рамках функций. Удаление операций резервирования памяти (malloc removal) является оптимизацией, призванной бороться с этими случаями. С помощью этой оптимизации производится удаление описанных операций резервирования памяти путем "разделения" ранее динамически созданного объекта на компоненты в том случае, если это возможно.
def distance(x1, y1, x2, y2):
p1 = (x1, y1)
p2 = (x2, y2)
return math.hypot(p1[0] - p2[0], p1[1] - p2[1])
v60 = malloc((GcStruct tuple2))
v61 = setfield(v60, ('item0'), x1_1)
v62 = setfield(v60, ('item1'), y1_1)
v63 = malloc((GcStruct tuple2))
v64 = setfield(v63, ('item0'), x2_1)
v65 = setfield(v63, ('item1'), y2_1)
v66 = getfield(v60, ('item0'))
v67 = getfield(v63, ('item0'))
v68 = int_sub(v66, v67)
v69 = getfield(v60, ('item1'))
v70 = getfield(v63, ('item1'))
v71 = int_sub(v69, v70)
v72 = cast_int_to_float(v68)
v73 = cast_int_to_float(v71)
v74 = direct_call(math_hypot, v72, v73)
Этот код не является оптимальным по нескольким причинам. В функции резервируется память для хранения двух кортежей, которые никогда не покинут ее пределы. К тому же, без видимых причин используется косвенный способ доступа к полям кортежей.
v53 = int_sub(x1_0, x2_0) v56 = int_sub(y1_0, y2_0) v57 = cast_int_to_float(v53) v58 = cast_int_to_float(v56) v59 = direct_call(math_hypot, v57, v58)
Операции резервирования памяти для хранения кортежей были полностью исключены, а также были удалены операции косвенного доступа. Чуть позже мы увидим то, как аналогичная удалению операций резервирования памяти техника используется на уровне приложения Python для реализации JIT-компиляции в PyPy (Раздел 19.5).
PyPy также занимается созданием inline-функций. Как и в языках более низкого уровня, применение inline-функций позволяет улучшить производительность RPython. Как это не удивительно, использование таких функций также позволяет уменьшить размер итогового бинарного файла. Это происходит из-за того, что появляется возможность выполнения большего количества оптимизаций сворачивания переменных и удаления операций резервирования памяти, благодаря которым и уменьшается общий объем кода.
Программа, представленная на данный момент в форме оптимизированных низкоуровневых потоковых графов, передается системе генерации кода для непосредственной генерации исходного кода. Перед тем, как она сможет сгенерировать исходный код на языке C, с помощью специфической системы генерации кода для языка C должны быть осуществлены некоторые дополнительные преобразования. Одним из таких преобразований является преобразование исключений, при осуществлении которого код для обработки исключений преобразуется для использования техники неавтоматизированной раскрутки стека. Другой оптимизацией является вставка проверок глубины стека. С помощью этих проверок могут быть сгенерированы исключения в процессе выполнения программы в том случае, если выполняется слишком глубокая рекурсия. Места, в которых требуются проверки глубины стека, определяются путем подсчета циклов с использованием графа вызовов программы.
Другим преобразованием, выполняемым системой генерации кода для языка C, является добавление функций для сборки мусора (garbage collection - GC). RPython, как и Python, является языком, использующим механизм сборки мусора, при этом язык C не является таковым, поэтому реализация механизма сборки мусора должна быть добавлена. Для этого система преобразования кода, предназначенная для реализации механизма сборки мусора, преобразует потоковые графы программы в потоковые графы с возможностью сборки мусора. Системы преобразования кода сборки мусора из состава PyPy демонстрируют то, как в ходе преобразования можно абстрагироваться от незначительных деталей. В CPython, где используется подсчет ссылок на ресурсы, в рамках кода интерпретатора на языке C должно осуществляться тщательное отслеживание ссылок на объекты Python, с которыми производятся манипуляции. В ходе этого процесса в рамках всей кодовой базы осуществляется реализация схемы сборки мусора, но эта схема подвержена воздействию незначительных ошибок, которые может допускать человек. Система преобразования кода, предназначенная для реализации механизма сборки мусора в рамках PyPy решает обе эти проблемы; она позволяет бесшовно подключать и отключать различные схемы сборки мусора. Не так сложно использовать реализацию системы сборки мусора (одну из многих предоставляемых в рамках PyPy), просто изменив параметр конфигурации во время преобразования. Говоря о ошибках системы преобразования, следует упомянуть о том, что система преобразования кода, предназначенная для реализации механизма сборки мусора, также никогда не совершает ошибок в определении ссылок на ресурс и не забывает о необходимости информирования системы сборки мусора в момент, когда объект перестает использоваться. Мощь абстракции для сборки мусора заключается в том, что эта абстракция позволяет использовать реализации систем сборки мусора, которые практически невозможно реализовать вручную в рамках интерпретатора. Например, некоторые реализации систем сборки мусора из состава PyPy требуют наличия барьера записи (write barrier). Барьер записи является проверкой, которая должна производиться каждый раз, когда контролируемый системой сборки мусора объект помещается в другой контролируемый системой сборки мусора массив или структуру. Процесс установления барьеров записи является трудоемким и может привести к ошибкам в случае ручной реализации, но он достаточно прост в том случае, когда выполняется автоматически системой преобразования кода, предназначенной для реализации механизма сборки мусора.
Наконец, система генерации кода получает возможность создания кода на языке C. Сгенерированный на основе низкоуровневых потоковых графов, код на языке C является уродливым нагромождением операторов goto и неочевидно названных переменных. Преимущество подхода, основанного на создании кода на языке C, заключается в том, что компилятор языка C может выполнить большую часть работы, заключающейся в сложных статических преобразованиях и требующейся для выполнения финальных оптимизаций циклов и резервирования регистров.
Продолжение статьи: JIT-компиляция в PyPy