Библиотека сайта rus-linux.net
Open MPI
Глава 15 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: Open MPI,
глава из книги "The Architecture of Open Source Applications" том 2.
Автор: Jeffrey M. Squyres
Перевод: Н.Ромоданов
Структура модуля
Структуры модулей определяются индивидуально в каждом фреймворке; между ними мало общего. В зависимости от того, какой используется фреймворк, компонент создает один или несколько экземпляров модулей и укажет, что они должны использоваться.
Например, во фреймворке BTL, один модуль обычно соответствует одному сетевому устройству. Если процесс MPI работает на Linux сервере с тремя устройствами Ethernet, то компонент TCP BTL создаст три модуля TCP BTL; один модуль соответствует каждому устройству Linux Ethernet. Затем каждый из модулей будет полностью ответственен за отправку и получение всех данных через конкретное сетевое устройство.
Объединяем все вместе
На рис.15.3 показана вложенность структур в компоненте TCP BTL и то, как он генерирует по одному модулю для каждой из трех устройств Ethernet.
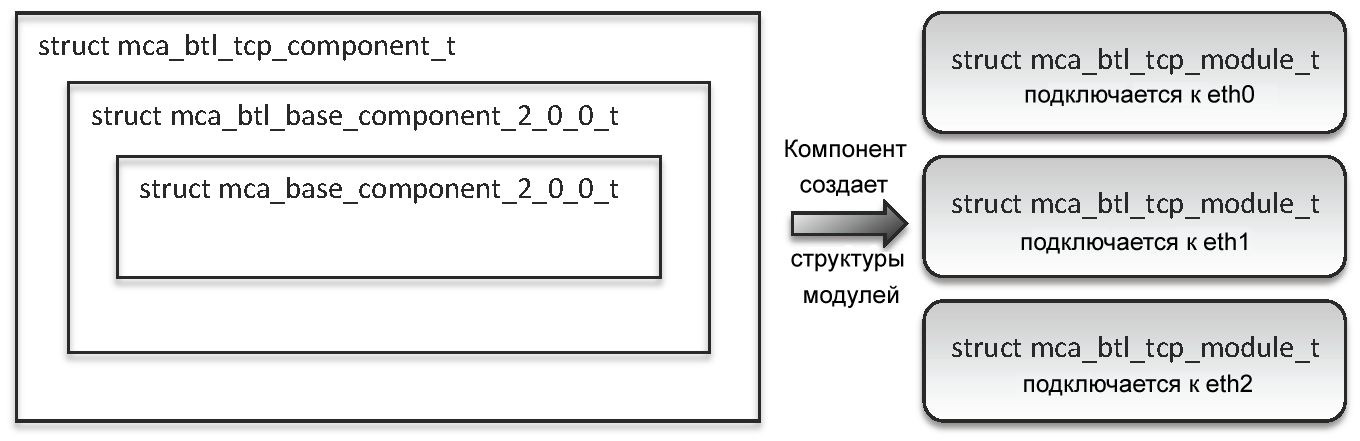
Рис.15.3: С левой стороны показана вложенность структур в компоненте TCP BTL. Справа показано, как компонент генерирует по одному модулю для каждого интерфейса Ethernet, идущего вверх.
Композиция модулей BTL, таким образом, позволяет движку верхнего уровня MPI обрабатывать все сетевые устройства одинаковым образом и выполнять привязку к каналу пользовательского уровня.
Например, рассмотрим отправку большого сообщения с помощью конфигурации из трех устройств, описанных выше. Предположим, что для того, чтобы достичь предполагаемого получателя, можно использовать любое из трех устройств Ethernet (достижимость определяется сетями TCP, масками и некоторыми строго задаваемыми эвристиками). В данном случае отправитель разделит большое сообщение на множество фрагментов. Каждый фрагмент будет назначен в цикле одному из модулей TCP BTL (поэтому каждому модулю будет назначено примерно одна треть фрагментов). Затем каждый модуль отправляет назначенные ему фрагменты через его собственное соответствующее устройство Ethernet.
Эта схема может показаться сложной, но она удивительно эффективна. За счет того, что пересылка большого сообщения происходит с помощью конвейера через несколько модулей TCP BTL, типичная среда высокопроизводительных вычислений (например, когда каждое устройство Ethernet находится на отдельной шине PCI) может через несколько устройств Ethernet поддерживать почти максимальную пропускную скорость.
Параметры времени выполнения
Разработчики при написании кода часто принимают решения, например, следующие:
- Должен ли использоваться алгоритм A или алгоритм B?
- Буфер какого размера должен предварительно выделиться?
- Насколько долгим должен быть таймаут?
- На какой размер сообщений должен быть настроен сетевой протокол?
- ... и так далее.
Пользователи склонны полагать, что разработчики ответят на подобные вопросы так, что это, в общем случае, подойдет для большинства типов систем. Тем не менее, в сообществе, связанном с высокопроизводительными вычислениями, много ученых и инженеров - опытных пользователей, которые хотят для каждого возможного варианта вычислительного цикла активно настраивать свои аппаратные и программные стеки. Хотя эти пользователи обычно не хотят возиться с фактическим кодом собственной реализации MPI, им интересно в различных обстоятельствах возиться с выбором различных внутренних алгоритмов, выбором различных моделей потребления ресурсов или принудительно задавать конкретные сетевые протоколы.
Поэтому когда разрабатывался проект Open MPI, была добавлена система параметров MCA; система представляет собой гибкий механизм, позволяющий пользователям во время исполнения изменять значения внутренних параметров Open MPI. В частности, разработчики могут везде в базовом коде Open MPI регистрировать строковые и целочисленные параметры MCA, указывающее соответствующее значение, используемое по умолчанию, и строку описания, определяющую, что это за параметр и как он используется. Общее правило состоит в том, что разработчики вместо того, чтобы жестко кодировать константы, используют параметры MCA, которые устанавливаются во время выполнения, что позволяет опытным пользователям настраивать то, как система будет себя вести на этапе выполнения.
В базовом коде трех абстрактных слоев есть ряд параметров MCA, но основная часть параметров MCA системы Open MPI размещены в отдельных компонентах. Например, в плагине TCL BTL есть параметр, определяющий должен ли использоваться только интерфейсы TCPv4, только интерфейсы TCPv6 или оба типа интерфейсов. Кроме того, с помощью еще одного параметра TCP BTL можно точно указывать какие используются устройства Ethernet.
Пользователи могут узнать, какие параметры доступны, с помощью специального, предназначенного для пользователей инструментального средства (ompi_info), работающего из командной строки. Значения параметров можно устанавливать несколькими способами: в командной строке, через переменные среды окружения, через реестр Windows, или с помощью системных или пользовательских файлов в стиле INI.
Система параметров MCA дополнила идею гибкого выбора плагинов во время выполнения и оказалось весьма ценной для пользователей. Хотя разработчики Open MPI старались выбирать разумные значения, используемые по умолчанию в самых разнообразных ситуациях, каждая высокопроизводительная среда имеет свои отличия. Неизбежно существуют среды, для которых не подходят значения параметров, задаваемые в Open MPI по умолчанию, и которые, возможно, даже вредят поддержке высокой производительности. Система параметров MCA позволяет пользователям быть активными и настраивать поведение Open MPI в соответствие с их средой. Это не только упрощает ситуацию с запросами об изменениях в Open MPI и/или с сообщениями об ошибках, но также позволяет пользователям экспериментировать с пространством параметров и находить лучшую конфигурацию для их конкретной системы.
Далее Усвоенные уроки