Библиотека сайта rus-linux.net
Git
Глава 6 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: Git
Автор: Susan Potter
Перевод: А.Панин
6.6. База данных объектов
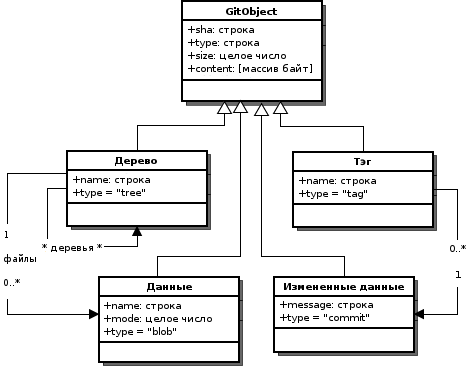
Рисунок 6.2: Объекты Git
- Дерево (Tree): элемент дерева может являться данными или еще одним деревом в случае представления директории с данными.
- Данные (Blob): данный тип объекта используется для представления файла, находящегося в репозитории.
- Измененные данные (Commit): данный тип объекта используется для указания на дерево, представляющее директорию верхнего уровня для измененных в ходе текущей операции данных, а также для ранее измененных данных и стандартных атрибутов.
- Тэг (Tag): тэг имеет имя и указывает на операцию изменения данных в истории изменений репозитория, которую он представляет.
- В том случае, если два объекта являются идентичными, они будут иметь одинаковые SHA-хэши.
- В том случае, если объекты различаются, они будут иметь разные SHA-хэши.
- В том случае, если объект был только частично скопирован или произошло другое повреждение данных, повторный расчет SHA-хэша для данного объекта поможет обнаружить такое повреждение данных.
Два первых свойства SHA-хэшей, относящиеся к установлению идентичности объектов, полезны для реализации распределенной модели Git (вторая задача системы Git). Последнее свойство позволяет организовать систему защиты от повреждения данных (третья задача Git).
Несмотря на желаемые результаты использования хранилища на основе направленных ациклических графов для хранения данных и истории объединений ветвей, для многих репозиториев хранилище на основе данных отличий файлов окажется более эффективным в плане использования дискового пространства, нежели хранилище на основе отдельных объектов, представленных направленными ациклическими графами.
6.7. Техники хранения и сжатия данных
Git решает проблему чрезмерного потребления дискового пространства путем сжатия объектов, причем файл индексирования данных используется для указания на сдвиги, по которым находятся определенные объекты в соответствующем упакованном файле.

Рисунок 6.3: Диаграмма упакованного файла с соответствующим файлом индексирования
Мы можем подсчитать количество отдельных (или не сжатых) объектов в локальном репозитории Git с помощью команды git count-objects. После этого мы можем упаковать отдельные объекты средствами Git в рамках базы данных объектов, удалить уже упакованные отдельные объекты и обнаружить лишние упакованные файлы с помощью вспомогательных команд Git в случае необходимости.
Формат файла упаковки объектов эволюционировал с начального уровня, представленного форматом с сохранением контрольных сумм для упакованного файла и файла индексирования в самом файле индексирования. Однако, данный подход допускал возможность неустанавливаемого повреждения сжатых данных, так как фаза повторной упаковки не предусматривала каких-либо дополнительных проверок. Во 2 версии формата файла упаковки объектов эта проблема была преодолена путем включения контрольных сумм для каждого из сжимаемых объектов в файл индексирования. Версия 2 также позволила создавать упакованные файлы размером более 4 ГБ, которые не поддерживались в начальной версии. Для быстрого установления факта повреждения файла упаковки объектов в его конце должен быть записан 20-байтный хэш SHA-1 для упорядоченного списка всех хэшей SHA объектов из этого файла. В новом формате файла упаковки объектов наибольшее внимание было уделено достижению второй цели проектирования, а именно защите данных от повреждения.
При удаленном взаимодействии Git подсчитывает объем добавленных и содержащихся в репозитории данных, которые должны быть переданы по сети для синхронизации репозиториев (или только ветви) и в процессе работы генерирует файл упаковки объектов, который должен быть отправлен назад с использованием выбранного клиентом протокола.
Следующий раздел: История объединения ветвей