Библиотека сайта rus-linux.net
Масштабируемая Веб-архитектура и распределенные системы
Глава 1 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: "Scalable Web Architecture and Distributed Systems",
глава из книги "The Architecture
of Open Source Applications" том 2.
Автор: Кейт Мэтсудейра,
Перевод: © jedi-to-be. Коррекция:
Anastasiaf15,
sunshine_lass,
Amaliya,
fireball,
Goudron.
Перевод впервые был опубликован на сайте Хабрахабр
1.3. Структурные компоненты быстрого и масштабируемого доступа к данным
Рассмотрев некоторые базовые принципы в разработке распределенных систем, давайте теперь перейдем к более сложному моменту - масштабирование доступа к данным.
Самые простые веб-приложения, например, приложения стека LAMP, схожи с изображением на рисунке 1.5.

Рисунок 1.5: Простые веб-приложения
С ростом приложения возникают две основных сложности: масштабирование доступа к серверу приложений и к базе данных. В хорошо масштабируемом дизайне приложений веб-сервер или сервер приложений обычно минимизируется и часто воплощает архитектуру, не предусматривающую совместного разделения ресурсов. Это делает уровень сервера приложений системы горизонтально масштабируемым. В результате использовании такого дизайна тяжёлый труд сместится вниз по стеку к серверу базы данных и вспомогательным службам; именно на этом слое и вступают в игру настоящие проблемы масштабирования и производительности.
Остальная часть этой главы посвящена некоторым наиболее распространенным стратегиям и методам повышения производительности и обеспечения масштабируемости подобных типов служб путем предоставления быстрого доступа к данным.
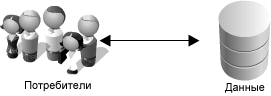
Рисунок 1.6: Упрощенное веб-приложение
Большинство систем может быть упрощено до схемы на рисунке 1.6,
которая является хорошей отправной точкой для начала рассмотрения. Если у Вас есть много данных, можно предположить, что Вы хотите иметь к ним такой же легкий доступ и быстрый доступ, как к коробке с леденцами в верхнем ящике вашего стола. Хотя данное сравнение чрезмерно упрощено, оно указывает на две сложные проблемы: масштабируемость хранилища данных и быстрый доступ к данным.
Для рассмотрения данного раздела давайте предположим, что у Вас есть много терабайт (ТБ) данных, и Вы позволяете пользователям получать доступ к небольшим частям этих данных в произвольном порядке. (См. рисунок 1.7.)
Схожей задачей является определение местоположения файла изображения где-нибудь на файловом сервере в примере приложения хостинга изображений.
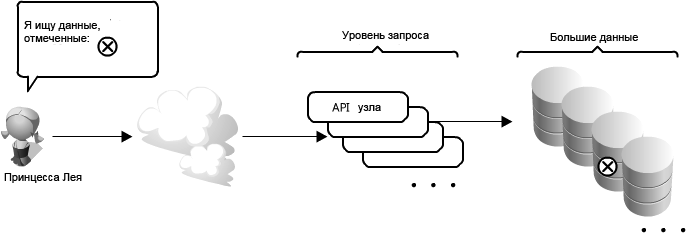
Рисунок 1.7: Доступ к определенным данным
Это особенно трудно, потому что загрузка терабайтов данных в память может быть очень накладной и непосредственно влияет на количество дисковых операций ввода-вывода. Скорость чтения с диска в несколько раз ниже скорости чтения из оперативной памяти - можно сказать, что доступ к памяти с так же быстр, как Чак Норрис, тогда как доступ к диску медленнее очереди в поликлинике. Эта разность в скорости особенно ощутима для больших наборов данных; в сухих цифрах доступ к памяти 6 раз быстрее, чем чтение с диска для последовательных операций чтения, и в 100,000 раз - для чтений в случайном порядке (см. "Патологии Больших Данных", http://queue.acm.org/detail.cfm?id=1563874). ). Кроме того, даже с уникальными идентификаторами, решение проблемы нахождения местонахождения небольшой порции данных может быть такой же трудной задачей, как и попытка не глядя вытащить последнюю конфету с шоколадной начинкой из коробки с сотней других конфет.
К счастью существует много подходов, которые можно применить для упрощения, из них четыре наиболее важных подхода - это использование кэшей, прокси, индексов и балансировщиков нагрузки. В оставшейся части этого раздела обсуждается то, как каждое из этих понятий может быть использовано для того, чтобы сделать доступ к данным намного быстрее.
Кэши
Кэширование дает выгоду за счет характерной черты базового принципа: недавно запрошенные данные вполне вероятно потребуются еще раз. Кэши используются почти на каждом уровне вычислений: аппаратные средства, операционные системы, веб-браузеры, веб-приложения и не только. Кэш походит на кратковременную память: ограниченный по объему, но более быстрый, чем исходный источник данных, и содержащий элементы, к которым недавно получали доступ. Кэши могут существовать на всех уровнях в архитектуре, но часто находятся на самом близком уровне к фронтэнду, где они реализованы, чтобы возвратить данные быстро без значительной нагрузки бэкэнда.
Каким же образом кэш может использоваться для ускорения доступа к данным в рамках нашего примера API? В этом случае существует несколько мест, подходящих размещения кэша. В качестве одного из возможных вариантов размещения можно выбрать узлы на уровне запроса, как показано на
рисунке 1.8.
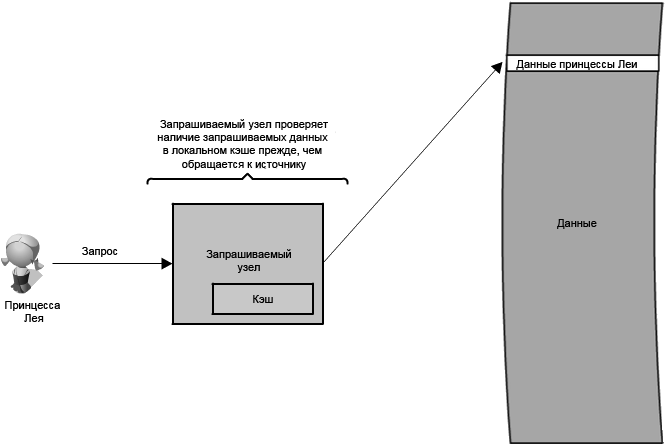
Рисунок 1.8: Размещение кэша на узле уровня запроса
Размещение кэша непосредственно на узле уровня запроса позволяет локальное хранение данных ответа. Каждый раз, когда будет выполняться запрос к службе, узел быстро возвратит локальные, кэшированные данные, если таковые существуют. Если это не будет в кэше, то узел запроса запросит данные от диска. Кэш на одном узле уровня запроса мог также быть расположен как в памяти (которая очень быстра), так и на локальном диске узла (быстрее, чем попытка обращения к сетевому хранилищу).
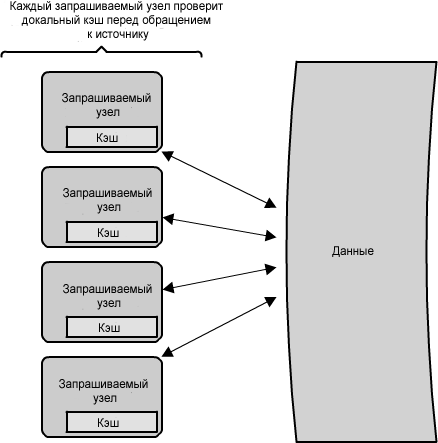
Рисунок 1.9: Системы кэшей
Что происходит, когда вы распространяете кеширование на множество узлов? Как Вы видите в рисунке 1.9, если уровень запроса будет включать множество узлов, то вполне вероятно, что каждый узел будет и свой собственный кэш. Однако, если ваш балансировщик нагрузки в произвольном порядке распределит запросы между узлами, то тот же запрос перейдет к различным узлам, таким образом увеличивая неудачные обращения в кэш. Двумя способами преодоления этого препятствия являются глобальные и распределенные кэши.
Глобальный кэш
Смысл глобального кэша понятен из названия: все узлы используют одно единственное пространство кэша. В этом случае добавляется сервер или хранилище файлов некоторого вида, которые быстрее, чем Ваше исходное хранилище и, которые будут доступны для всех узлов уровня запроса. Каждый из узлов запроса запрашивает кэш таким же образом, как если бы он был локальным. Этот вид кэширующей схемы может вызвать некоторые затруднения, так как единственный кэш очень легко перегрузить, если число клиентов и запросов будет увеличиваться. В тоже время такая схема очень эффективна при определенной архитектуре (особенно связанной со специализированными аппаратными средствами, которые делают этот глобальный кэш очень быстрым, или у которых есть фиксированный набор данных, который должен кэшироваться).
Есть две стандартных формы глобальных кэшей, изображенных в схемах. На рисунке 1.10 изображена ситуация, когда кэшируемый ответ не найден в кэше, сам кэш становится ответственным за получение недостающей части данных от базового хранилища. На рисунке 1.11 проиллюстрирована обязанность узлов запроса получить любые данные, которые не найдены в кэше.
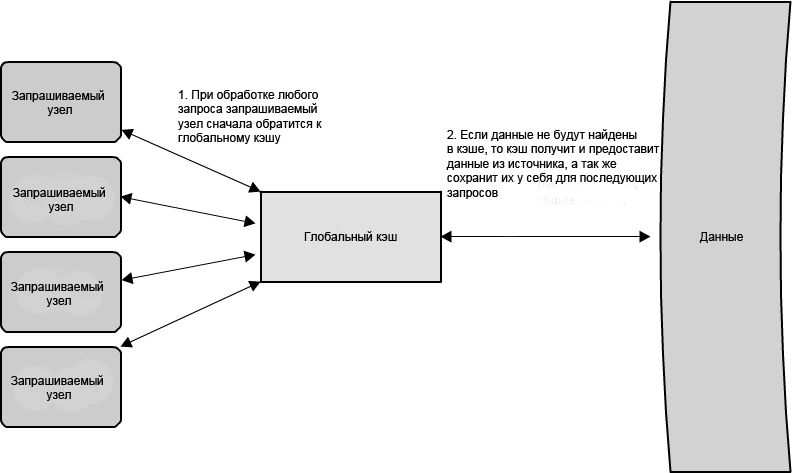
Рисунок 1.10: Глобальный кэш, где кэш ответственен за извлечение
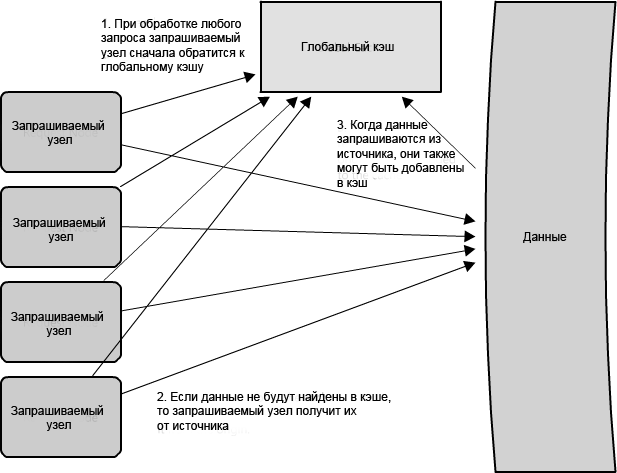
Рисунок 1.11: Глобальный кэш, где узлы запроса ответственны за извлечение
Большинство приложений, усиливающих глобальные кэши, склонно использовать первый тип, где сам кэш управляет замещением и данными выборки, чтобы предотвратить лавинную рассылку запросов на те же данные от клиентов. Однако, есть некоторые случаи, где вторая реализация имеет больше смысла. Например, если кэш используется для очень больших файлов, низкий процент удачного обращения в кэш приведет к перегрузке кэша буфера неудачными обращениями в кэш; в этой ситуации это помогает иметь большой процент общего набора данных (или горячего набора данных) в кэше. Другой пример - архитектура, где файлы, хранящиеся в кэше, статичны и не должны быть удалены. (Это может произойти из-за основных эксплуатационных характеристик касательно такой задержки данных - возможно, определенные части данных должны оказаться очень быстрыми для больших наборов данных - когда логика приложения понимает стратегию замещения или горячие точки лучше, чем кэш.)
Распределенный кэш
В распределенном кэше (рисунок 1.12), каждый из его узлов владеет частью кэшированных данных, поэтому если холодильник в продуктовом магазине сравнить с кэшем, тогда распределенный кэш походит на хранение вашей еды в нескольких удобных для доступа местах - холодильнике, стойках и коробке для завтрака, что избавляет необходимости совершать путешествия на склад. Обычно кэш сегментирован при помощи непротиворечивой хеш-функции. Если узел запроса ищет определенную часть данных, он может быстро узнать, куда смотреть в распределенном кэше, чтобы определить, доступны ли эти данные. В этом случае каждый узел поддерживает маленькую часть кэша и сначала отправляет запрос данных другому узлу прежде, чем обращается к источнику. Поэтому, одно из преимуществ распределенного кэша - расширяемое пространство кэша, что достигается простым добавлением узлов к пулу обработки запросов.
Недостаток распределенного кэширования - работа в условиях недостающих узлов. Некоторые распределенные кэши обходят эту проблему, храня избыточные копии данных на множестве узлов; однако, можно представить, насколько быстро логическая структура такого кэша может сложной, особенно в условиях добавления или удаления узлов из уровня запроса. Стоит отметить - даже если узел исчезает, и часть кэша будет потеряна, последствия необязательно окажутся катастрофическими - запросы просто получат данные непосредственно от источника!
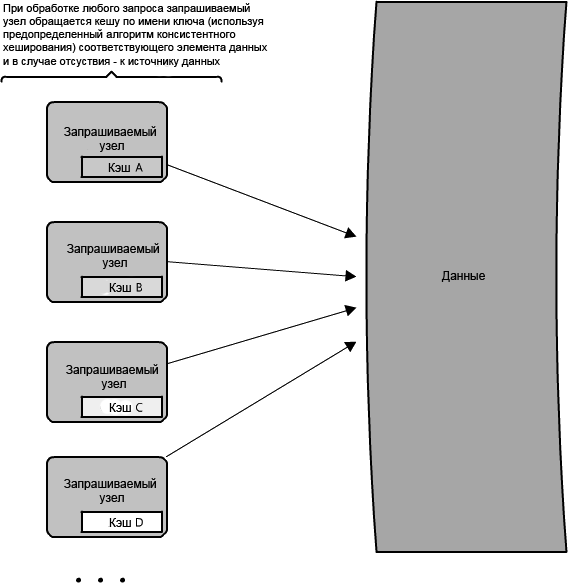
Рисунок 1.12: Распределенный кэш.
Большим преимуществом кэшей является увеличение скорости работы системы (безусловно, только при правильной реализации!) Выбранная методология позволяет ускорить этот процесс для еще большего количества запросов. Однако, использование кэширования предполагает определенные затраты на поддержание дополнительного пространства обычно дорогостоящей памяти. Кэши замечательно подходят не только для общего увеличения производительности системы, но и обеспечения ее функциональность при нагрузке такого высокого уровня, которая в обычной ситуации привела бы к полному отказу в обслуживании.
Одним из популярных примеров кэша с открытым исходным кодом можно назвать Memcached (), который может работать как локальным, так и распределенным кэшем); кроме того, есть много других вариантов (включая специфичные для определенного языка или платформы).
Memcached используется во многих больших веб-сайтах, и даже при том, что он может быть очень мощным, представляет собой просто хранилище типа ключ-значение в оперативной памяти, оптимизированного для произвольного хранения данных и быстрых поисков (O(1)).
Facebook использует несколько различных типов кэширования, чтобы добиться высокой производительности своего сайта (см., "Facebook: кэширование и производительность"). Они используют
$GLOBALS и APC, кэширующие на уровне языка (представленные в PHP за счет вызова функции), который способствует ускорению промежуточных вызовов функции и получению результатов. (Большинство языков оснащены этими типами библиотек для улучшения производительность веб-страницы, и они почти всегда должны использоваться.) Кроме того Facebook использует глобальный кэш, который распределен на множество серверов (см. "Масштабирование memcached в Facebook"), таким образом, что один вызов функции, получающий доступ к кэшу, мог параллельно выполнить множество запросов для данных, хранящихся на различных серверах Memcached. Такой подход позволяет добиться намного более высокой производительности и пропускной способности для данных профиля пользователя, и создать централизованную архитектуру обновления данных. Это важно, так как, при наличии тысяч серверов, функции аннулирования и поддержания непротиворечивости кэша могут вызывать затруднение. Далее речь пойдет об алгоритме действий в случае отсутствия данных в кэше.
Далее: Прокси