Библиотека сайта rus-linux.net
CMake
Глава 5 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: "CMake", глава из
книги "The Architecture
of Open Source Applications"
Автор: Bill Hoffman и Kenneth Martin
Дата публикации: 2012 г.
Перевод: Н.Ромоданов
Дата перевода: 28 августа 2012 г.
В 1999 году Национальная медицинская библиотека заказала небольшой компании, называющейся Kitware, разработать улучшенный способ конфигурирования, сборки и развертывания сложного программного обеспечения, предназначенный для большого количества различных платформ. Эта работа была частью проекта Insight Segmentation and Registration, или ITK (смотрите в конце статьи примечание 1). На компанию Kitware, играющую ведущую роль в проекте, было возложена разработка системы сборки приложений, которой могли бы пользоваться исследователи и разработчики проекта ITK. Система должна была быть простой в использовании и должна была помочь наиболее продуктивно использовать время, затрачиваемое исследователями на программирование. Согласно этой директиве появилась система CMake, которая заменила устаревающий подход с использованием autoconf/libtool, применявшийся при сборке программ. Система была разработана для того, чтобы преодолеть недостатки существующих инструментальных средств и при этом сохранить их преимущества.
Кроме того, что CMake является системой сборки, он в течение многих лет эволюционировал в семейство инструментальных средств: CMake, CTest, CPack и CDash. CMake является инструментом для сборки, предназначенным для создания программ. CTest - это инструментальный драйвер тестов, применяемый при запуске регрессионных тестов. CPack является упаковщиком, используемым при создании инсталляторов на конкретные платформы для программ, созданных с использованием CMake. CDash - это веб-приложение, предназначенное для отображения результатов тестирования и выполнения тестирования в технологии непрерывной сборки проектов.
5.1. История создания CMake и предъявленные к нему требования
Когда разрабатывался CMake, обычной практикой было использование в проекте конфигурационного скрипта и файлов Makefile для платформ Unix, а для Windows - проектных файлов Visual Studio. Такая двойственность систем сборки делала кросс-платформенную разработку во многих проектах очень утомительной: простое действие по добавлению в проект нового файла с исходным кодом оказывалось тяжелым делом. Очевидно, что разработчики хотели иметь единую унифицированную систему сборки. У разработчиков CMake был опыт двух подходов к решению проблемы унифицированной системы сборки.
Первым подходом была система сборки VTK разработки 1999 года. Эта система состояла из конфигурационного скрипта для Unix и исполняемого модуля для Windows, называемого pcmaker. Программа pcmaker, которая была написана на языке C, читала файлы Makefile для платформ Unix и создавала файлы NMake - для Windows. Исполняемый модуль pcmaker помещался в репозиторий CVS системы VTK. В некоторых типичных случаях, например, при добавлении новой библиотеки, нужно было изменять исходный код этого модуля и новый двоичный модуль снова помещать в репозиторий. Хотя, в некотором смысле, это была унифицированная система, в ней было много недостатков.
Другой подход, опыт применения которого был у разработчиков, состоял в использовании системы gmake, представляющей собой базовую систему сборки для системы TargetJr. Система TargetJr являлась средой машинного зрения, написанной на языке C++ и первоначально разработанной для рабочих станций фирмы Sun. Сначала в TargetJr при создании файлов Makefile использовалась система imake. Но, в какой-то момент, когда потребовался порт для Windows, была создана система gmake. С этой системой, базирующейся на gmake, можно было использовать как компиляторы для платформы Unix , так и компиляторы для Windows. Системе требовалось несколько переменных среды окружения, которые нужно было установить перед запуском gmake. Неверная настройка среды окружения приводила к сбою в работе системы, причем такому, в котором было трудно разобраться, особенно - конечным пользователям.
Оба эти подхода страдали от серьезного недостатка: они заставляли разработчиков приложений для Windows использовать командную строку. Опытные разработчики предпочитают в Windows использовать интегрированные среды разработки (IDE). Это побуждало разработчиков приложений для Windows вручную создавать файлы IDE и добавлять их в проект, снова создавая двойную систему сборки. Кроме отсутствия поддержки среды IDE, в обоих подходах, описанных выше, было чрезвычайно трудно совмещать вместе различные программные проекты. Например, в VTK было очень мало модулей чтения изображений, главным образом, из-за того, что в системе сборки было очень трудно пользоваться библиотеками, например, libtiff и libjpeg.
Было решено, что новая система сборки должна быть разработана для ITK и, в общем случае, для C++. Основные требования к новой системе сборки выглядели следующим образом:
- Зависимость должна быть только от компилятора C++, установленного в системе.
- Должна быть возможность генерировать входные файлы для Visual Studio IDE.
- Должна быть возможность указывать системе сборки, что надо собрать - статические библиотеки, разделяемые библиотеки, исполняемые модули или плагины.
- Должна быть возможность на этапе сборки запускать генераторы кода.
- Поддержка деревьев сборки должна быть отделена от поддержки дерева исходных кодов.
- Должна быть возможность выполнять самопроверку системы, то есть возможность автоматически определять, что сможет и что не сможет делать система.
- Должно автоматически выполняться сканирование зависимостей по заголовочным файлам C/C++.
- Все функции должны работать слаженно и одинаково на всех поддерживающих платформах.
Чтобы избежать зависимости от каких-либо дополнительных библиотек и анализаторов, CMake был спроектирован только с одной главной зависимостью — компилятором С++ (который, как мы можем с уверенностью предположить, у нас есть, если мы собираем код C++). В то время было трудно собирать и устанавливать скриптовые языки, например, Tcl, на многих популярных системах UNIX и Windows. Сегодня на современных суперкомпьютерах и защищенных компьютерах, у которых нет подключения к интернету, это все еще остается проблемой, поскольку все еще трудно собирать библиотеки сторонних разработчиков. Т.к. система сброки, как таковая, являлась главной задачей, было решено, что в CMake не будут добавляться какие-либо дополнительные зависимости. Из-за этих ограничений в CMake пришлось создать свой собственной простой язык, из-за которого некоторым все еще не нравится CMake. Впрочем, тогда самым популярным встроенным языком был Tcl. Если бы CMake был системой сборки на основе Tcl, то вряд ли бы он достиг той популярности, которой он обладает сегодня.
Возможность создавать проектные файлы IDE является сильной стороной CMake, но это также является ограничением CMake, поскольку поддерживаются только те возможности, которые изначально присутствуют в IDE. Впрочем, преимущества получения сборочных файлов для конкретной IDE перевешивают эти ограничения. Хотя такое решение сделало разработку CMake сложнее, оно существенно облегчило разработку ITK и других проектов, в которых применяется CMake. Разработчикам удобнее и продуктивнее работать с теми инструментальными средствами, с которыми они лучше знакомы. Благодаря тому, что разработчики пользуются инструментальными средствами, которым они отдают предпочтение, в проектах можно наилучшим образом использовать самый важный ресурс - разработчиков.
Всем программам C/C++ необходим один или несколько следующих сборочных блоков: исполняемые модули, статические библиотеки, разделяемые библиотеки и плагины. CMake должен был позволять создавать эти компонентов для всех поддерживаемых платформ. Несмотря на то, что создание таких компонентов поддерживается на всех платформах, флаги компилятора, которые используются при их создании, существенно различаются в зависимости от компиляторов и платформ. За счет того, что в CMake сложность и различие платформ скрыты в простой команде, разработчики могут создавать такие компоненты в Windows, Unix и Mac. Это позволяет разработчикам сосредоточиться на проекте, а не на деталях, связанных со сборкой разделяемой библиотеки.
В системе сборки дополнительная сложность связана с генераторами кода. В VTK с самого начала была предложена схема, в которой код на C++ автоматически помещается внутрь кода Tcl, Python и Java следующим образом: выполняется анализ заголовочных файлов C++ и автоматически создается слой-обертка. Для этого необходима система сборки, которая может собрать исполняемый модуль на C/C++ (генератор обвертки), а затем на этапе сборки запустить этот модуль и создать другой исходный код C/C++ (обертки для конкретных модулей). Затем этот сгенерированный исходный код должен быть откомпилирован в исполняемые модули или разделяемые библиотеки. Все это должно произойти в среде IDE и с использованием сгенерированных файлов Makefile.
Когда на C/C++ разрабатываются универсальные кросс-платформенное программы, важно программировать функциональные возможности системы, а не конкретную систему. В autotools есть модель для проведения самопроверки системы, которая состоит из компиляции небольших фрагментов кода, его проверки и запоминания результатов. Поскольку подразумевалось, что CMake должен был быть кросс-платформенным, в него вошла подобная технология самопроверки системы. Она позволяет разработчикам выполнять программирование для канонической системы, а не для конкретных систем. Это важно для достижения мобильности в будущем, поскольку со временем меняются как компиляторы, так и операционные системы. Например, следующий код:
#ifdef linux // делаем что-то для linux #endif
менее устойчив, чем следующий код:
#ifdef ИМЕЕТСЯ_ФУНКЦИЯ // делаем что-то с помощью этой функции #endif
Другое первоначальное требование к CMake также было взято из autotools: возможность создавать деревья сборки, которые будут отделены от дерева исходных кодов. Это позволяет для одного и того же дерева исходных кодов создавать несколько типов деревьев сборки. В результате предотвращается влияние деревьев сборки на дерево исходных кодов, что часто мешает работе систем контроля версий.
Одной из наиболее важных особенностей системы сборки является возможность управлять зависимостями. Если исходный файл изменен, то все программы, использующие этот исходный файл, должны быть пересобраны заново. Для кода C/C++ как часть зависимостей должны быть также проверены заголовочные файлы, включенные в файл .c или .cpp. Если не отслеживать случаи, когда в действительности должна компилироваться только часть кода, то из-за неверной информации о зависимостях может затрачиваться большое количество времени.
Все требования к новой системе сборки и ее функциональные возможности должны быть одинаково хорошо реализованы для всех поддерживаемых платформ. Необходимо, чтобы CMake был простым API, позволяющим разработчикам, не знающим особенностей платформы, создавать сложные программные системы. В сущности, программы, использующие CMake, перенаправляют в CMake всю сложность, связанную со сборкой. После того, как было создано общее представление об инструментальном средстве сборки и базовом наборе к нему требований, потребовалось достаточно гибко выполнить реализацию. В проекте ITK система сборки нужна была практически с первого дня. Первые версии CMake не отвечали всему набору требований это общего представления, но могли выполнять сборку на Windows и Unix.
5.2. Как реализован CMake
Как уже упоминалось, языками разработки пакета CMake являются C и C++. Чтобы объяснить его внутренние особенности, далее в настоящем разделе сначала описывается процедура использования CMake в том виде, как ее видит пользователь, а затем изучаются используемые в CMake структуры.
5.2.1. Процедура использования CMake
Процедура использования CMake состоит из двух основных этапов. Во-первых, это шаг "конфигурирования", на котором пакет CMake обрабатывает все переданные ему входные данные и создает внутреннее представление сборки, которую нужно выполнить. Затем идет следующий этап - шаг "генерации". На этом этапе создаются файлы фактической сборки.
Переменные среды окружения (или не среды окружения)
Во многих системах сборки в 1999 году и даже сегодня во время создания проекта используются переменные среды окружения командной оболочки. Закономерно, что в проекте есть переменная среды окружения PROJECT_ROOT, которая указывает на местонахождение корня дерева исходных кодов. Переменные среды окружения также используются для указания на дополнительные или внешние пакеты. Трудность этого этого подхода в том, что для того, чтобы сборка проекта работала, нужно каждый раз, когда выполняется сборка, устанавливать значения всех этих внешних переменных. Чтобы решить эту проблему, в CMake есть кэш-файл, в котором в одном месте запомнены все переменные, необходимые для сборки. Они являются переменными CMake , а не переменными командной оболочки или среды окружения. Когда CMake запускается первый раз для конкретного дерева сборки, он создает файл CMakeCache.txt, в котором постоянно хранятся все переменные, необходимые для этой сборки. Поскольку этот файл является частью дерева сборки, переменные всегда будут доступны для CMake при каждом его запуске.
Шаг конфигурирования
На шаге конфигурирования CMake сначала читает файл CMakeCache.txt, если тот существует после предыдущего запуска. Затем он читает файл CMakeLists.txt, который находится в корне дерева исходных кодов, переданных в CMake. На шаге конфигурирования файл CMakeLists.txt анализируется анализатором языка CMake. Каждая команда CMake, обнаруженная в файле, выполняется объектом с образом команды. Кроме того, на этом шаге с помощью команд CMake include и add_subdirectory может быть проанализирован файл CMakeLists.txt. В CMake для каждой команды, которая может использоваться в языке CMake, есть объект C++. Примерами таких команд являются команды add_library, if, add_executable, add_subdirectory и include. В сущности, весь язык CMake реализован в виде обращений к командам. Синтаксический анализатор просто преобразует входные файлы CMake в вызовы команд и списки строк, которые являются аргументами этих команд.
На шаге конфигурирования, по существу, "работает" код CMake, предоставленный пользователями. После того, как весь код будет выполнен и будут вычислены все значения кэш-переменных, в CMake будет запомненное представление проекта, который должен быть собран. В него будут включены все библиотеки, исполняемые модули, команды пользователя и вся другая информация, необходимая для создания окончательных файлов сборки для выбранного генератора. В этом момент файл CMakeCache.txt сохраняется на диске для использования при будущих запусках CMake.
Запомненное представление проекта является набором целевых задач, определяющих просто то, что нужно собрать, например, библиотеки и исполняемые модули. В CMake также можно указывать пользовательские целевые задачи: пользователи могут определять свои собственные входные и выходные данные, а также предоставлять свои собственные исполняемые модули или скрипты, которые должны работать во время сборки. В CMake каждая целевая задача хранится в объекте cmTarget. Эти объекты хранятся, в свою очередь, в объекте cmMakefile, который, по существу, является местом хранения всех целевых задач, найденных в заданном каталоге дерева исходного кода. Итоговым результатом является дерево объектов cmMakefile, содержащих отображения объектов cmTarget.
Шаг генерации
Как только шаг конфигурирования будет завершен, происходит переход к шагу генерации. Шаг генерации — это этап, когда CMake создает файлы сборки для целевого инструментального средства сборки, выбранного пользователем. В этот момент внутреннее представление целевых задач (создание библиотек, исполняемых модулей, пользовательские целевые задачи) преобразуется либо во входные файлы сборочной инструментальной среды IDE, такой как Visual Studio, либо в набор файлов Makefile, который будут обработан командой make. Внутреннее представление, создаваемое CMake после шага конфигурирования, настолько обобщено, что один и тот же код и те же самые структуры данных могут максимальным образом использоваться различными инструментальными средствами сборки.
Общий вид процедуры использования CMake приведен на рис.5.1.
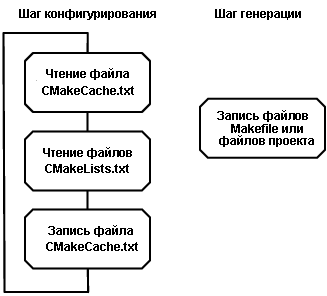
Рис.5.1: Общий вид процедуры использования CMake
5.2.2. CMake: Код
Объекты CMake
CMake является объектно-ориентированной системой, в которой используется наследование, шаблоны проектирования и инкапсуляция. Основные объекты на C++ и их отношения приведены на рис.5.2.
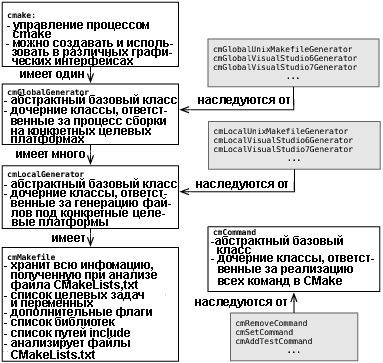
Рис.5.2: Объекты CMake
Результаты анализа каждого файла CMakeLists.txt хранятся в объекте cmMakefile. Объект cmMakefile не только хранит информацию о каталоге, но и управляет анализом файла CMakeLists.txt. Функция анализа обращается к объекту, который для анализа языка CMake обращается к синтаксическому анализатору на базе lex/yacc. Т.к. синтаксис языка CMake меняется не часто, а lex и yacc не всегда есть в системах, где CMake выполняет сборку, файлы, получаемые на выходе lex и yacc, обрабатываются и вместе со всеми другими файлами, созданными вручную, сохранятся в каталоге Source системы контроля версий.
Другим важным классом в CMake является класс cmCommand. Это базовый класс реализации всех команд языка CMake. В каждом его подклассе не только реализуется команда, но и осуществляется ее документирование. В качестве примера взгляните на методы документирования в классе cmUnsetCommand:
virtual const char* GetTerseDocumentation()
{
return "Unset a variable, cache variable, or environment variable.";
}
/**
* More documentation.
*/
virtual const char* GetFullDocumentation()
{
return
" unset(<variable> [CACHE])\n"
"Removes the specified variable causing it to become undefined. "
"If CACHE is present then the variable is removed from the cache "
"instead of the current scope.\n"
"<variable> can be an environment variable such as:\n"
" unset(ENV{LD_LIBRARY_PATH})\n"
"in which case the variable will be removed from the current "
"environment.";
}
Анализ зависимостей
В CMake есть мощные встроенные средства анализа зависимостей для отдельных файлов исходного кода на языках Fortran, C и C++. Поскольку в интегрированных средах разработки (в IDE) есть свои собственные средства работы с информацией о зависимостях файлов, CMake для этих систем сборок пропускает шаг анализа зависимостей. В случае с IDE CMake создает входной файл, нативный для IDE, и предоставляет самой IDE обрабатывать информацию о зависимостях уровня файлов. Информация о зависимостях уровня целевой задачи преобразуется в формат IDE и добавляется к остальной информации о зависимостях.
Что касается сборок, использующих файлы Makefile, то до сих пор нативная программа make не знает, как автоматически вычислять и сохранять информацию о зависимостях. Для этих сборок CMake автоматически вычисляет информацию о зависимостях для файлов на C, C++ и Fortran. Вычисление информации о зависимостях и поддержание ее в актуальном состоянии автоматически выполняется с помощью CMake. После того, как с помощью CMake проект будет первоначально сконфигурирован, пользователям нужно будет только запускать команду make, а остальную работу сделает CMake.
Хотя пользователям не требуется знать, как CMake выполняет эту работу, может оказаться полезным взглянуть в проекте на файлы с информацией о зависимостях. Для каждой целевой задачи эта информация хранится в следующих четырех файлах - depend.make, flags.make, build.make и DependInfo.cmake. В файле depend.make хранится информация о зависимостях для всех объектных файлов каталога. В файле flags.make хранятся флаги компиляции, используемые с исходными файлами для этой целевой задачи. Если они изменились, то файлы должны быть перекомпилированы. Файл DependInfo.cmake все еще используется для хранения информации о зависимостях и также содержит информацию о том, какие файлы являются частями проекта и какие в них используются языки. Наконец, правила для сборки зависимостей хранятся в файле build.make. Если зависимости для целевой задачи устарели, информация о зависимостях для данной целевой задачи будет перерасчитана заново и зависимости будут обновлены. Это делается из-за того, что любое изменение в любом файле .h может добавить новую зависимость.
CTest и CPack
По ходу дела CMake перерос из системы сборки проекта в семейство инструментальных средств, предназначенных для сборки, тестирования и создания пакетов программ. Кроме команды cmake, работающей из командной строки, и программ графического интерфейса CMake, CMake также поставляется в комплекте с инструментальным средством тестирования CTest и средством создания пакетов CPack. CTest и CPack используют тот же самый базовый код, что и CMake, но являются отдельными инструментами и для основной сборки проекта они не нужны.
Модуль ctest предназначен для запуска регрессионных тестов. В проекте можно легко с помощью команды add_test создавать тесты для CTest. Тесты можно выполнить с помощью CTest, а результаты тестирования также можно с помощью CTest отправить в приложение CDash для просмотра их в интернете. CTest и CDash вместе аналогичны инструментальному средству тестирования Hudson. Самое главное их отличие в следующем: CTest поволяет выполнять тестирование в более разнообразных условиях. Клиентские системы можно настроить таким образом, что исходный код будет выбираться из системы контроля версий, затем будут выполняться тесты, а результат будет отправляться в приложение CDash. В случае с Hudson для того, чтобы можно было запускать тесты, на клиентских машинах
нужно открывать доступ пакету Hudson по ssh.
Модуль cpack предназначен для создания инсталляторов проектов. Пакет CPack работает почти также, как и та часть CMake, которая выполняет сборку: пакет взаимодействует с другими инструментальными средствами создания пакетов. Например, в Windows для создания в проекте самостоятельно запускаемых инсталляторов используется упаковщик NSIS. CPack запускает на выполнение инсталляционные правила проекта, в результате чего создается инсталляционное дерево, которое затем передается программе, создающей инсталляторы, например, NSIS. CPack также поддерживает создание файлов RPM, файлов .deb — для Debian, а также файлов .tar, .tar.gz и самораспаковывающихся файлов tar.
5.2.3. Графические интерфейсы
Первое, с чем сталкиваются многие пользователи, только что увидевшие CMake, это одна из программ пользовательского интерфейса CMake. В CMake есть два основных приложения пользовательского интерфейса: оконное приложение на базе Qt, а также приложение с текстовым интерфейсом, похожим на графический, работающее из командной строки. Эти графические интерфейсы используются в качестве графического редактора файла CMakeCache.txt. Это сравнительно простые интерфейсы с двумя кнопками - конфигурирование и генерация, используемыми для запуска основных этапов процесса CMake. Текстовый интерфейс доступен на Unix-платформах типа TTY и в Cygwin. Графический интерфейс Qt доступен на всех платформах. Примеры графического интерфейса приведены на рис. 5.3 и 5.4.
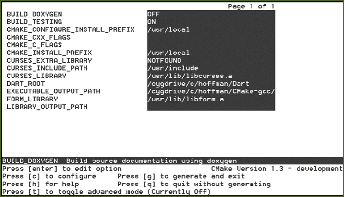
Рис.5.3: Интерфейс командной строки
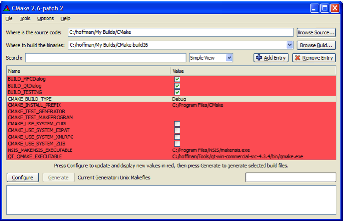
Рис.5.4: Графический интерфейс
В обоих вариантах графического интерфейса имена кэш-переменных размещены слева, а их значения - справа. Значения, указываемые справа, пользователь может заменить теми, которые подходят для конкретной сборки. Есть два набора переменных — обычный и расширенный. По умолчанию пользователю показывается обычный набор переменных. В проекте в файлах CMakeLists.txt можно указать, какие переменные будут входить в расширенный набор переменных. Этот подход позволяет предложить пользователю несколько вариантов, выбираемых для конкретной сборки.
Поскольку по мере того, как выполняются команды, значения кэш-переменных могут изменяться, процесс приближения к финальной сборке может быть итеративным. Например, включение некоторых параметров может потребовать использовать другие параметры. По этой причине в графическом интерфейсе кнопка "генерации" остается отключенной до тех пор, пока у пользователя не будет иметься возможности, по крайней мере, один раз увидеть все параметры. Каждый раз, когда нажимается кнопка конфигурирования, новые кэш-переменные, которые еще не были показаны пользователю, отображаются красным цветом. После того, как во время конфигурирования будут созданы все новые кэш-переменные, будет включена кнопка генерации.
5.2.4. Тестирование CMake
Любой новый разработчик CMake сначала знакомится с процессом тестирования, используемым при разработке CMake. В этом процессе задействовано семейство инструментальных средств CMake (CMake, CTest, CPack и CDash). Как только код разработан и помещен в систему контроля версий, машины, выполняющие тестирование в процессе непрерывной сборки проекта, автоматически выполняют сборку и с помощью пакета CTest тестируют новый код CMake. Результаты отсылаются на сервер CDash, который в случае, если есть ошибки сборки, предупреждения компилятора или если тест прошел неудачно, уведомляет об этом разработчиков по электронной почте.
Это классическая схема тестирования, используемая при непрерывной сборке проекта. Как только новый код помещается в репозиторий CMake, он автоматически тестируется на платформах, поддерживаемых в CMake. Если учесть огромное количество компиляторов и платформ, поддерживаемых в CMake, то такая схема тестирования является весьма важной для разработки стабильной системы сборки.
Например, если новый разработчик захочет добавить поддержку новой платформы, то первый вопрос, который ему будет задан — может ли обеспечить непрерывную работу клиентской программы CMake для этой системы. Без постоянного тестирования новая система через некоторое время неизбежно перестанет работать.
5.3. Усвоенные уроки
CMake с самого первого дня успешно использовался при сборке проекта ITK, и это было самой важной частью проекта. Если бы мы могли снова повторить разработку CMake, то мало что следовало бы изменить. Тем не менее, всегда есть то, что можно было бы сделать лучше.
5.3.1. Обратная совместимость
Поддержка обратной совместимости очень важна для команды разработчиков CMake. Основной целью проекта является сделать проще сборку программ. Когда команда проекта или разработчик выбирают CMake в качестве инструмента сборки, важно уважать этот выбор и нужно очень постараться, чтобы сборку можно было бы продолжать выполнять с помощью последующих релизов CMake. В CMake 2.6 реализована политика, что в случае, если предполагается, что некоторое поведение системы устарело, об этом следует выдавать предупреждение, но в системе само такое устаревшее поведение должно поддерживаться. В каждом файле CMakeLists.txt следует указать, какую предполагается использовать версию CMake. Новые версии CMake могут выдавать предупреждения, но они все равно должны собирать проект так, как это делалось в старых версиях.
5.3.2. Язык, язык, язык
Предполагалось, что язык CMake должен быть очень простым. Тем не менее, он является одним из основных препятствий, когда в новом проекте принимается решение об использовании CMake. С языком CMake в процессе его естественного роста были несколько интересных моментов. Первый синтаксический анализатор языка был создан даже не на базе lex/yacc, а был простым анализатором строк. Когда появился шанс расширить язык, мы потратили некоторое время на поиск хорошего встроенного языка среди уже имеющихся языков. Лучшим вариантом для работы оказался язык Lua. Это очень маленький и ясный язык. Даже если бы не использовался сторонний язык, похожий на Lua, мне надо было с самого начала больше внимания уделять существующему языку.
5.3.3. Плагины не работают
Чтобы в проектах можно было расширять возможности языка CMake, в CMake есть класс плагинов. Он позволяет в проекте на языке C создавать новые команды CMake. На тот момент такой подход казался правильным и для того, чтобы можно было пользоваться другими компиляторами, был определен интерфейс языка C. Но с появлением большого количества систем API, например, для 32/64-разрядных Windows и Linux, совместимость плагинов стало поддерживать трудно. Несмотря на то, что расширение языка CMake с помощью самого CMake является не столь мощным средством, оно позволяет избежать ситуаций, когда CMake перестает работать или не может собрать проект из-за того, что плагин не удалось собрать или загрузить.
5.3.4. Ограничение распространения API
Важный урок, усвоенный в процессе разработки проекта CMake, состоит в том, что вы не должны поддерживать обратную совместимость с тем, к чему пользователи не должны получать доступ. Несколько раз в ходе разработки CMake пользователи и заказчики просили, чтобы CMake был преобразован в библиотеку для того, чтобы функциональные возможности CMake можно было бы добавить к другим языкам. Это бы не только разрушило сообщество пользователей CMake из-за того, что возникло бы множество способов применения CMake, но также чрезмерно увеличило бы затраты на техническое обслуживание проекта CMake.
Примечания
- http://www.itk.org/